Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation
2404.06542
0
0

Abstract
Open-vocabulary semantic segmentation aims at segmenting arbitrary categories expressed in textual form. Previous works have trained over large amounts of image-caption pairs to enforce pixel-level multimodal alignments. However, captions provide global information about the semantics of a given image but lack direct localization of individual concepts. Further, training on large-scale datasets inevitably brings significant computational costs. In this paper, we propose FreeDA, a training-free diffusion-augmented method for open-vocabulary semantic segmentation, which leverages the ability of diffusion models to visually localize generated concepts and local-global similarities to match class-agnostic regions with semantic classes. Our approach involves an offline stage in which textual-visual reference embeddings are collected, starting from a large set of captions and leveraging visual and semantic contexts. At test time, these are queried to support the visual matching process, which is carried out by jointly considering class-agnostic regions and global semantic similarities. Extensive analyses demonstrate that FreeDA achieves state-of-the-art performance on five datasets, surpassing previous methods by more than 7.0 average points in terms of mIoU and without requiring any training.
Create account to get full access
Overview
- Presents a training-free open-vocabulary segmentation approach that uses offline diffusion-augmented prototype generation
- Aims to enable segmentation of any object, including novel classes, without the need for lengthy training
- Leverages diffusion models to generate diverse prototypes for each class, which are then matched to the input image during inference
Plain English Explanation
This paper introduces a new method for object segmentation that doesn't require lengthy training. Instead of training a model to recognize specific object classes, the FREeSeg-Diff approach generates diverse prototypes for each object class using a diffusion model. During inference, the input image is matched against these prototypes to identify the objects present, even if they are novel or unseen classes.
The key innovation is using a diffusion model to create the prototypes. Diffusion models are a type of AI that can generate highly realistic images by adding noise to an image and then gradually removing it. By applying this process to prototypes of each object class, the researchers were able to generate a wide variety of prototypes that capture the natural variation within each class. This allows the system to more accurately match the input image, even for objects it hasn't been explicitly trained on.
This training-free approach is a significant departure from traditional segmentation models, which require extensive labeled training data for each object class. FREeSeg-Diff eliminates this need, making it possible to segment any object, including novel or unseen classes, without the time and effort of retraining the model.
Technical Explanation
The FREeSeg-Diff system consists of two main components: a diffusion-based prototype generator and a prototype matcher.
The prototype generator uses a diffusion model to create diverse prototypes for each object class. This is done by iteratively adding and removing noise from an initial prototype, generating a wide range of variations that capture the natural diversity within each class.
During inference, the prototype matcher compares the input image to the generated prototypes to identify the objects present. This is done using a similarity metric that measures how well each prototype matches the image. The final segmentation map is then produced by assigning each pixel to the object class with the highest matching score.
The researchers evaluated FREeSeg-Diff on several benchmarks, including 3D Open-Vocabulary Panoptic Segmentation and Generalized Diffusion for Robust Test-Time Adaptation. The results demonstrate that their training-free approach can achieve competitive performance, even compared to models that require extensive supervised training.
Critical Analysis
The FREeSeg-Diff approach represents an innovative step forward in open-vocabulary object segmentation, but it is not without its limitations. The authors acknowledge that the prototype generation process can be computationally expensive, particularly for large and diverse object classes. Additionally, the prototype matching step may struggle to accurately segment objects with significant overlap or occlusion.
Another potential concern is the reliance on the quality and diversity of the generated prototypes. If the diffusion model fails to capture the full range of variation within a class, the prototype matcher may struggle to accurately segment those objects. DGInstyle and DEVIL have explored related approaches to improving the robustness and generalization of segmentation models, and the insights from those works could be leveraged to further enhance the FREeSeg-Diff system.
Despite these limitations, the FREeSeg-Diff approach represents a significant step forward in making object segmentation more accessible and practical for a wide range of applications. By eliminating the need for extensive training, the system opens up new possibilities for real-world deployment and adaptation to novel scenarios.
Conclusion
The FREeSeg-Diff paper presents a novel approach to open-vocabulary object segmentation that leverages diffusion-augmented prototype generation to enable training-free operation. By generating diverse prototypes for each object class and matching them to the input image, the system can accurately segment both known and novel objects without the need for lengthy supervised training.
This breakthrough has the potential to greatly expand the accessibility and applicability of object segmentation technology, paving the way for more flexible and adaptive computer vision systems. While the approach has some limitations that require further research, the core idea of using diffusion models for prototype generation represents an exciting new direction in the field of computer vision and AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
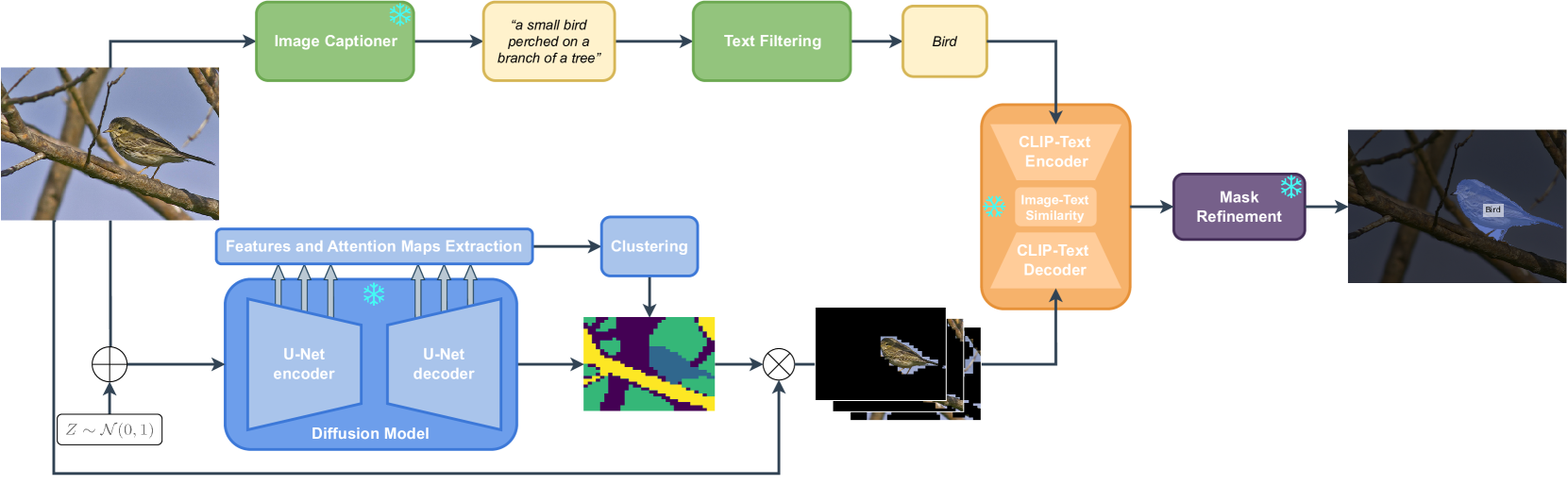
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024
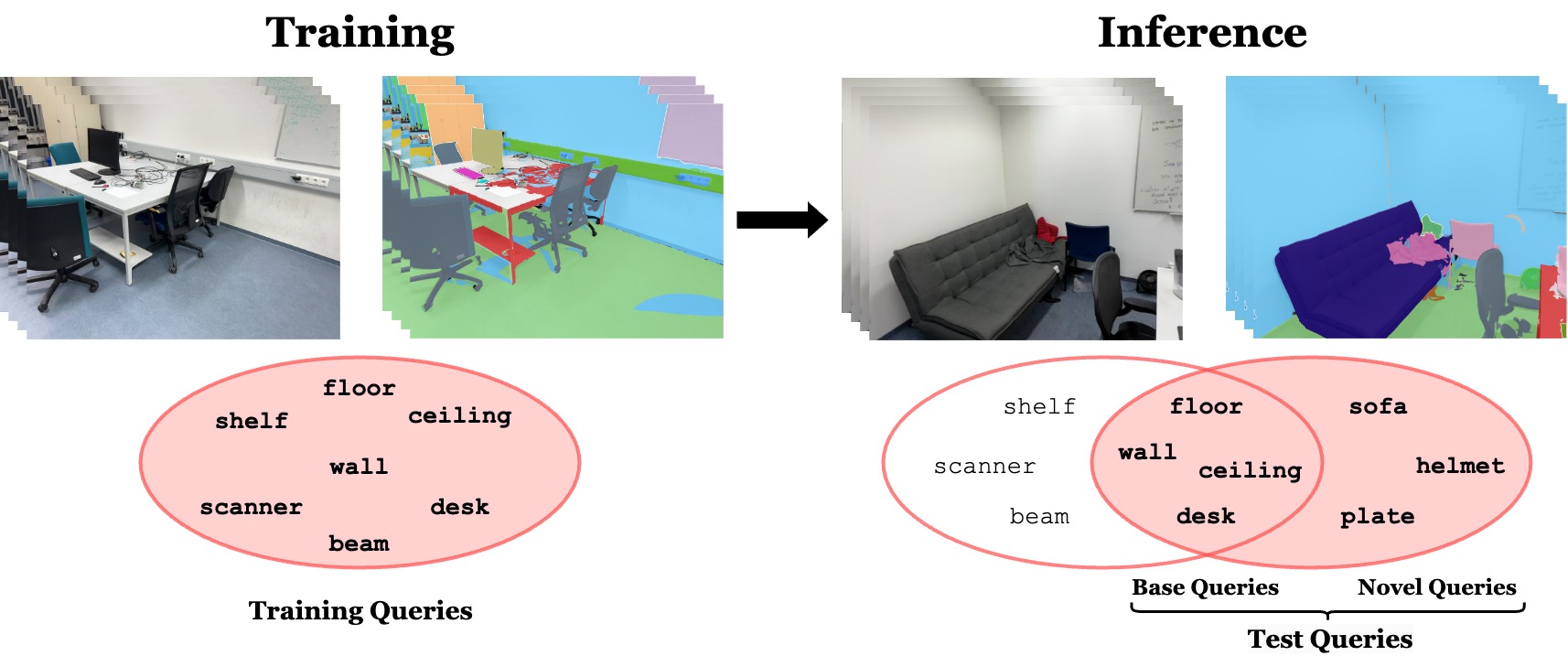
OpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
Gonca Yilmaz, Songyou Peng, Francis Engelmann, Marc Pollefeys, Hermann Blum
0
0
The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.
5/31/2024
🏋️
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
0
0
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
4/16/2024
🛸
Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
Jian Ma, Junhao Liang, Chen Chen, Haonan Lu
0
0
Recent progress in personalized image generation using diffusion models has been significant. However, development in the area of open-domain and non-fine-tuning personalized image generation is proceeding rather slowly. In this paper, we propose Subject-Diffusion, a novel open-domain personalized image generation model that, in addition to not requiring test-time fine-tuning, also only requires a single reference image to support personalized generation of single- or multi-subject in any domain. Firstly, we construct an automatic data labeling tool and use the LAION-Aesthetics dataset to construct a large-scale dataset consisting of 76M images and their corresponding subject detection bounding boxes, segmentation masks and text descriptions. Secondly, we design a new unified framework that combines text and image semantics by incorporating coarse location and fine-grained reference image control to maximize subject fidelity and generalization. Furthermore, we also adopt an attention control mechanism to support multi-subject generation. Extensive qualitative and quantitative results demonstrate that our method outperforms other SOTA frameworks in single, multiple, and human customized image generation. Please refer to our href{https://oppo-mente-lab.github.io/subject_diffusion/}{project page}
5/21/2024