OpFlowTalker: Realistic and Natural Talking Face Generation via Optical Flow Guidance

0
🌿
Sign in to get full access
Overview
- Generating realistic and natural-looking talking face videos remains a significant challenge.
- Previous research has focused on generating and aligning single-frame images, often compromising visual quality and effects.
- This paper introduces the use of optical flow to guide facial image generation, enhancing inter-frame continuity and semantic consistency.
Plain English Explanation
Creating believable and easy-to-understand talking face videos is still a difficult problem to solve. Past research has mainly worked on generating and lining up individual images, but this often led to videos that looked choppy or didn't match up well with the audio.
To address these issues, this paper proposes a new approach called OpFlowTalker. Instead of predicting each frame directly, OpFlowTalker uses predicted optical flow changes from the audio to guide the facial image generation. This helps smooth out the transitions between frames and keep the visuals aligned with the audio content.
The paper also introduces a technique to replace generating frames independently, which helps maintain the overall context and timing of the video. Additionally, it includes a module to synchronize the movements of the full face and lips, optimizing the visual quality.
Finally, the researchers developed a new way to measure how well the lip movements match the audio, called the Visual Text Consistency Score (VTCS). This allows them to objectively evaluate how easy the synthesized videos are to read.
Technical Explanation
The key innovation in this paper is the use of optical flow to guide the facial image generation process. Optical flow refers to the pattern of apparent motion of objects in a visual scene caused by the relative movement between the observer and the scene.
Rather than directly predicting each frame of the talking face video, the OpFlowTalker model uses the predicted optical flow changes from the audio input to control the facial image generation. This helps ensure that the transitions between frames are smooth and that the visual changes align with the semantic content of the audio.
The paper also introduces a sequence fusion technique to replace the independent generation of single frames. This preserves the contextual information and maintains the temporal coherence of the video.
Additionally, the researchers developed an optical flow synchronization module that regulates both full-face and lip movements. This helps balance the regional dynamics and optimize the overall visual synthesis.
To evaluate the quality of the synthesized videos, the authors introduce a new metric called the Visual Text Consistency Score (VTCS). This measure specifically focuses on how well the lip movements match the audio, providing a more accurate assessment of lip-readability.
Critical Analysis
The paper presents a promising approach to generating more natural and lip-readable talking face videos. By leveraging optical flow to guide the image generation process, the OpFlowTalker model addresses some of the key limitations of previous research, which often resulted in disjointed or semantically incongruent visual output.
However, the paper does not extensively discuss the potential limitations or drawbacks of the proposed method. For example, it is not clear how the approach would scale to handle more complex facial expressions, emotions, or diverse speaking styles. Additionally, the paper does not address potential biases or fairness considerations that may arise from the training data or model design.
Further research could also explore the integration of the OpFlowTalker approach with other state-of-the-art techniques, such as those used in Faces That Speak, SwapTalk, or Listen, Disentangle, Control, to further enhance the realism and versatility of the generated talking face videos.
Conclusion
This paper introduces a novel approach, OpFlowTalker, that leverages optical flow to generate more natural and lip-readable talking face videos. By using predicted optical flow changes from audio inputs to guide the facial image generation process, the model is able to maintain smooth transitions and semantic consistency between frames.
The inclusion of a sequence fusion technique and an optical flow synchronization module further enhances the temporal coherence and regional dynamics of the synthesized videos. Additionally, the introduction of the Visual Text Consistency Score (VTCS) provides a valuable metric for evaluating lip-readability.
While the paper demonstrates promising results, further research is needed to explore the scalability and potential limitations of the approach, as well as opportunities for integration with other state-of-the-art techniques in this rapidly evolving field of video synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
OpFlowTalker: Realistic and Natural Talking Face Generation via Optical Flow Guidance
Shuheng Ge, Haoyu Xing, Li Zhang, Xiangqian Wu
Creating realistic, natural, and lip-readable talking face videos remains a formidable challenge. Previous research primarily concentrated on generating and aligning single-frame images while overlooking the smoothness of frame-to-frame transitions and temporal dependencies. This often compromised visual quality and effects in practical settings, particularly when handling complex facial data and audio content, which frequently led to semantically incongruent visual illusions. Specifically, synthesized videos commonly featured disorganized lip movements, making them difficult to understand and recognize. To overcome these limitations, this paper introduces the application of optical flow to guide facial image generation, enhancing inter-frame continuity and semantic consistency. We propose OpFlowTalker, a novel approach that utilizes predicted optical flow changes from audio inputs rather than direct image predictions. This method smooths image transitions and aligns changes with semantic content. Moreover, it employs a sequence fusion technique to replace the independent generation of single frames, thus preserving contextual information and maintaining temporal coherence. We also developed an optical flow synchronization module that regulates both full-face and lip movements, optimizing visual synthesis by balancing regional dynamics. Furthermore, we introduce a Visual Text Consistency Score (VTCS) that accurately measures lip-readability in synthesized videos. Extensive empirical evidence validates the effectiveness of our approach.
Read more5/29/2024

0
RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network
Xiaozhong Ji, Chuming Lin, Zhonggan Ding, Ying Tai, Jian Yang, Junwei Zhu, Xiaobin Hu, Jiangning Zhang, Donghao Luo, Chengjie Wang
Person-generic audio-driven face generation is a challenging task in computer vision. Previous methods have achieved remarkable progress in audio-visual synchronization, but there is still a significant gap between current results and practical applications. The challenges are two-fold: 1) Preserving unique individual traits for achieving high-precision lip synchronization. 2) Generating high-quality facial renderings in real-time performance. In this paper, we propose a novel generalized audio-driven framework RealTalk, which consists of an audio-to-expression transformer and a high-fidelity expression-to-face renderer. In the first component, we consider both identity and intra-personal variation features related to speaking lip movements. By incorporating cross-modal attention on the enriched facial priors, we can effectively align lip movements with audio, thus attaining greater precision in expression prediction. In the second component, we design a lightweight facial identity alignment (FIA) module which includes a lip-shape control structure and a face texture reference structure. This novel design allows us to generate fine details in real-time, without depending on sophisticated and inefficient feature alignment modules. Our experimental results, both quantitative and qualitative, on public datasets demonstrate the clear advantages of our method in terms of lip-speech synchronization and generation quality. Furthermore, our method is efficient and requires fewer computational resources, making it well-suited to meet the needs of practical applications.
Read more6/27/2024

0
Make Your Actor Talk: Generalizable and High-Fidelity Lip Sync with Motion and Appearance Disentanglement
Runyi Yu, Tianyu He, Ailing Zhang, Yuchi Wang, Junliang Guo, Xu Tan, Chang Liu, Jie Chen, Jiang Bian
We aim to edit the lip movements in talking video according to the given speech while preserving the personal identity and visual details. The task can be decomposed into two sub-problems: (1) speech-driven lip motion generation and (2) visual appearance synthesis. Current solutions handle the two sub-problems within a single generative model, resulting in a challenging trade-off between lip-sync quality and visual details preservation. Instead, we propose to disentangle the motion and appearance, and then generate them one by one with a speech-to-motion diffusion model and a motion-conditioned appearance generation model. However, there still remain challenges in each stage, such as motion-aware identity preservation in (1) and visual details preservation in (2). Therefore, to preserve personal identity, we adopt landmarks to represent the motion, and further employ a landmark-based identity loss. To capture motion-agnostic visual details, we use separate encoders to encode the lip, non-lip appearance and motion, and then integrate them with a learned fusion module. We train MyTalk on a large-scale and diverse dataset. Experiments show that our method generalizes well to the unknown, even out-of-domain person, in terms of both lip sync and visual detail preservation. We encourage the readers to watch the videos on our project page (https://Ingrid789.github.io/MyTalk/).
Read more6/18/2024
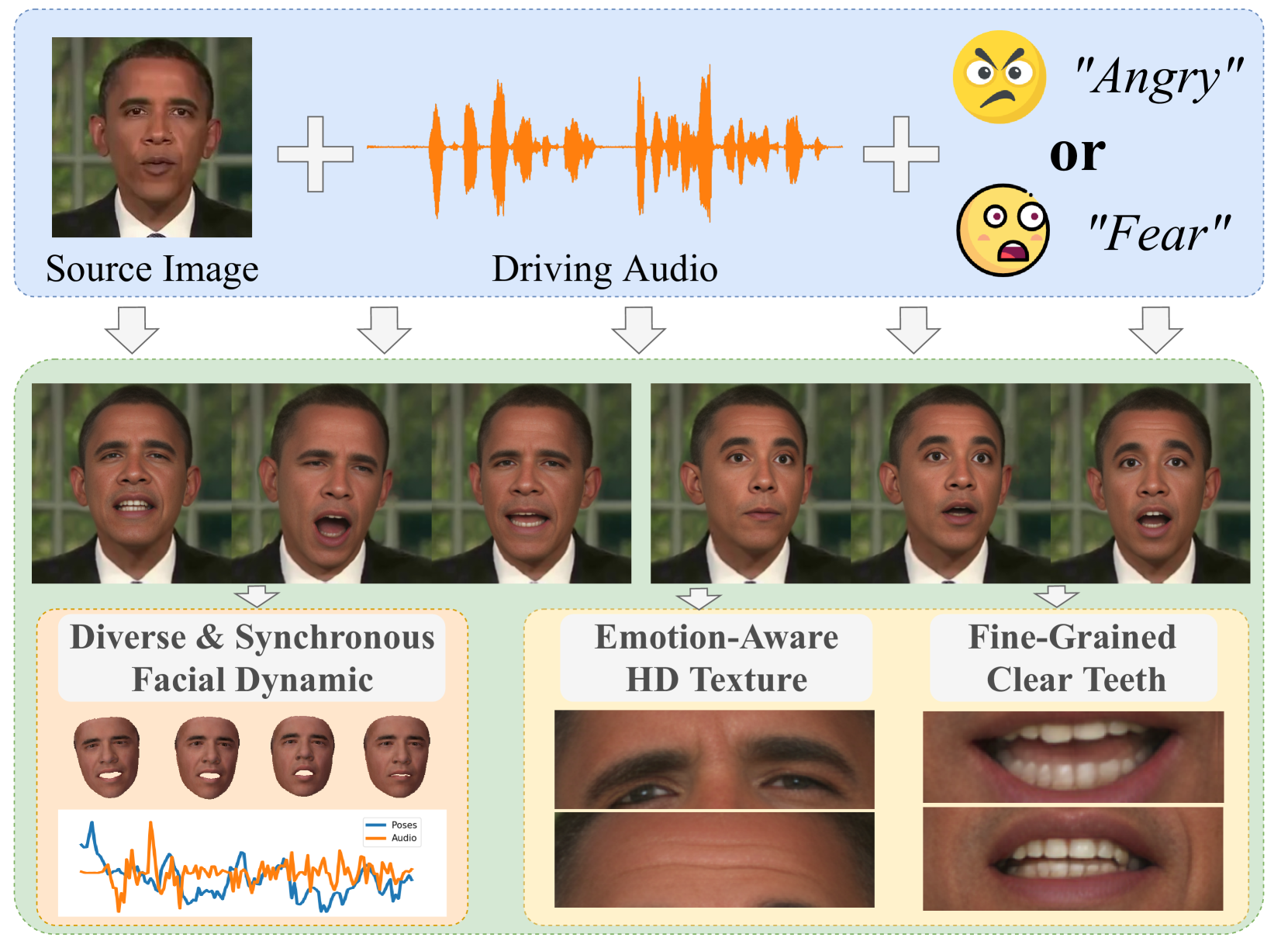
0
FlowVQTalker: High-Quality Emotional Talking Face Generation through Normalizing Flow and Quantization
Shuai Tan, Bin Ji, Ye Pan
Generating emotional talking faces is a practical yet challenging endeavor. To create a lifelike avatar, we draw upon two critical insights from a human perspective: 1) The connection between audio and the non-deterministic facial dynamics, encompassing expressions, blinks, poses, should exhibit synchronous and one-to-many mapping. 2) Vibrant expressions are often accompanied by emotion-aware high-definition (HD) textures and finely detailed teeth. However, both aspects are frequently overlooked by existing methods. To this end, this paper proposes using normalizing Flow and Vector-Quantization modeling to produce emotional talking faces that satisfy both insights concurrently (FlowVQTalker). Specifically, we develop a flow-based coefficient generator that encodes the dynamics of facial emotion into a multi-emotion-class latent space represented as a mixture distribution. The generation process commences with random sampling from the modeled distribution, guided by the accompanying audio, enabling both lip-synchronization and the uncertain nonverbal facial cues generation. Furthermore, our designed vector-quantization image generator treats the creation of expressive facial images as a code query task, utilizing a learned codebook to provide rich, high-quality textures that enhance the emotional perception of the results. Extensive experiments are conducted to showcase the effectiveness of our approach.
Read more4/24/2024