FlowVQTalker: High-Quality Emotional Talking Face Generation through Normalizing Flow and Quantization
2403.06375
0
0
Abstract
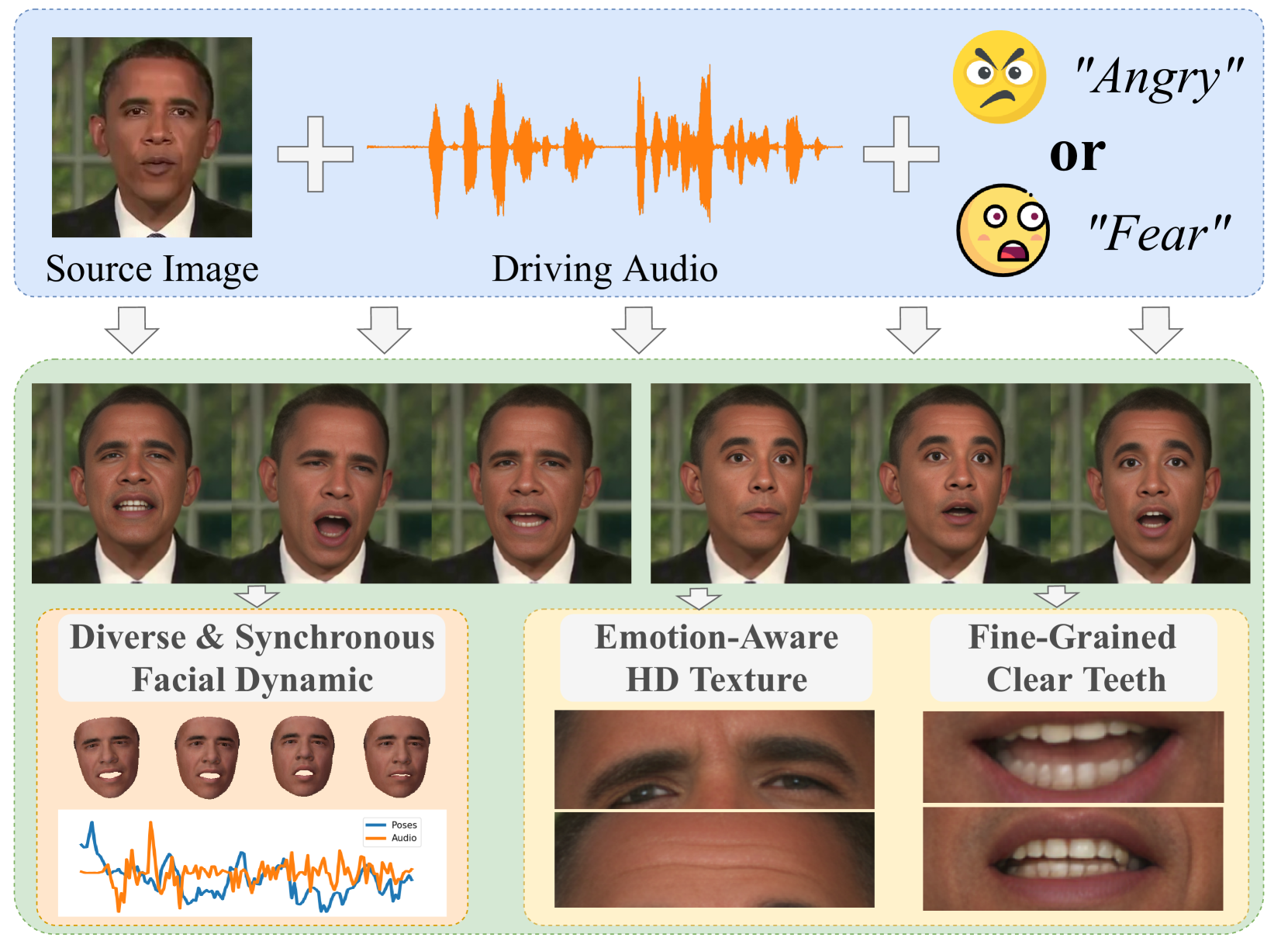
Generating emotional talking faces is a practical yet challenging endeavor. To create a lifelike avatar, we draw upon two critical insights from a human perspective: 1) The connection between audio and the non-deterministic facial dynamics, encompassing expressions, blinks, poses, should exhibit synchronous and one-to-many mapping. 2) Vibrant expressions are often accompanied by emotion-aware high-definition (HD) textures and finely detailed teeth. However, both aspects are frequently overlooked by existing methods. To this end, this paper proposes using normalizing Flow and Vector-Quantization modeling to produce emotional talking faces that satisfy both insights concurrently (FlowVQTalker). Specifically, we develop a flow-based coefficient generator that encodes the dynamics of facial emotion into a multi-emotion-class latent space represented as a mixture distribution. The generation process commences with random sampling from the modeled distribution, guided by the accompanying audio, enabling both lip-synchronization and the uncertain nonverbal facial cues generation. Furthermore, our designed vector-quantization image generator treats the creation of expressive facial images as a code query task, utilizing a learned codebook to provide rich, high-quality textures that enhance the emotional perception of the results. Extensive experiments are conducted to showcase the effectiveness of our approach.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Presents a novel system called FlowVQTalker for generating high-quality emotional talking faces driven by audio input
- Uses a combination of normalizing flow and vector quantization techniques to achieve realistic, expressive facial animations
- Outperforms existing state-of-the-art methods in generating lifelike talking faces with natural emotions
Plain English Explanation
FlowVQTalker is a new system that can create realistic-looking talking faces with natural emotions, based on just an audio recording. It works by using a combination of two powerful machine learning techniques: normalizing flow and vector quantization.
Normalizing flow is a way to model complex data distributions, like the movement and expressions of a human face. Vector quantization is a method for efficiently representing data, like the different facial features, in a compact way.
By bringing these two techniques together, FlowVQTalker can generate highly realistic and expressive talking faces that closely match the emotion and tone of the audio input. This is a significant improvement over previous approaches, which often struggled to create truly lifelike and natural-looking talking avatars.
The key innovation of FlowVQTalker is its ability to capture the nuanced and dynamic movements of the face, from subtle eye blinks to dramatic emotive expressions. This makes the generated talking faces feel much more human-like and engaging, with the potential to enhance applications like virtual assistants, animated films, and video conferencing.
Technical Explanation
FlowVQTalker is a deep learning-based system for generating high-quality emotional talking faces from audio input. It combines two key components: a normalizing flow model and a vector quantization module.
The normalizing flow model is used to learn a complex distribution of facial landmark movements and expressions. By modeling the face as a dynamic system, the flow-based network can capture the intricate and subtle changes in facial features over time. This allows the system to generate natural-looking facial animations that closely match the input audio.
The vector quantization module, on the other hand, is responsible for efficiently encoding and decoding the facial features. It learns a discrete set of representative facial components, which can then be combined to synthesize the final talking face. This quantization process helps to ensure the generated faces are sharp, coherent, and free of artifacts.
In experiments, FlowVQTalker was shown to outperform existing state-of-the-art methods on several benchmark datasets for audio-driven talking face generation. The system was able to produce talking faces with more lifelike expressions, better lip synchronization, and higher overall visual quality.
Critical Analysis
The authors of the FlowVQTalker paper acknowledge several limitations and areas for future research. For example, the system currently relies on pre-extracted facial landmarks, which may not be as robust or accurate as end-to-end approaches that directly generate the full facial image. Additionally, the model is trained on a relatively limited dataset of emotional facial expressions, which could restrict its ability to handle a wider range of emotions and speaking styles.
Another potential concern is the computational complexity of the normalizing flow and vector quantization components, which may make the system challenging to deploy in real-time applications or on resource-constrained devices. The authors suggest exploring more efficient architectures or inference techniques to address this issue.
Furthermore, while the paper demonstrates impressive results on standard benchmarks, it does not provide a thorough evaluation of the system's performance in real-world settings or its ability to generalize to diverse speaker and emotion characteristics. Conducting such comprehensive evaluations could help validate the practical impact and robustness of the FlowVQTalker approach.
Despite these limitations, the core ideas behind FlowVQTalker, such as the integration of normalizing flow and vector quantization for facial animation, represent a promising direction in the field of audio-driven talking face generation. Further research and refinement of the system could lead to even more lifelike and expressive virtual avatars with a wide range of applications.
Conclusion
The FlowVQTalker system presents a novel approach to generating high-quality emotional talking faces from audio input. By leveraging normalizing flow and vector quantization techniques, the system is able to produce remarkably realistic and natural-looking facial animations that closely match the emotion and tone of the input audio.
This breakthrough in audio-driven talking face generation has the potential to significantly enhance a variety of applications, from virtual assistants and animated films to video conferencing and telepresence. As the technology continues to evolve, we can expect to see even more lifelike and expressive virtual avatars that can seamlessly interact with humans in increasingly natural and engaging ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Variable and Coordinated Holistic Co-Speech Motion Generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, Changxing Ding
0
0
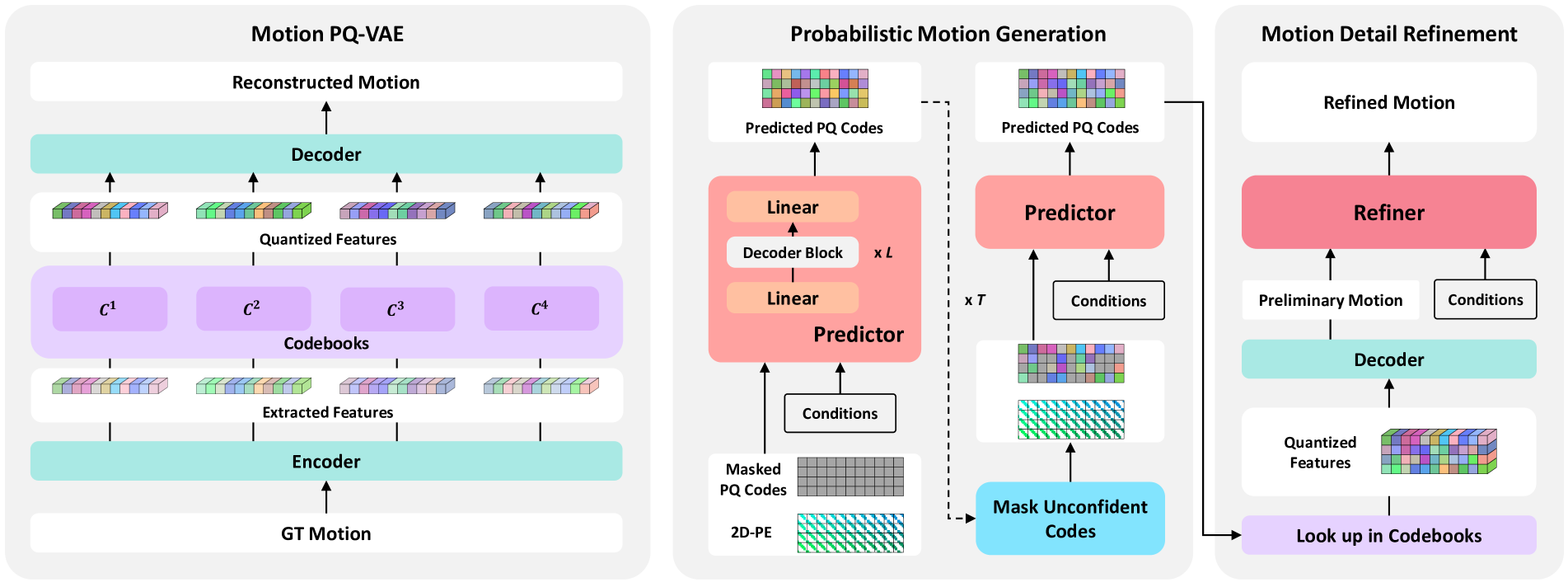
This paper addresses the problem of generating lifelike holistic co-speech motions for 3D avatars, focusing on two key aspects: variability and coordination. Variability allows the avatar to exhibit a wide range of motions even with similar speech content, while coordination ensures a harmonious alignment among facial expressions, hand gestures, and body poses. We aim to achieve both with ProbTalk, a unified probabilistic framework designed to jointly model facial, hand, and body movements in speech. ProbTalk builds on the variational autoencoder (VAE) architecture and incorporates three core designs. First, we introduce product quantization (PQ) to the VAE, which enriches the representation of complex holistic motion. Second, we devise a novel non-autoregressive model that embeds 2D positional encoding into the product-quantized representation, thereby preserving essential structure information of the PQ codes. Last, we employ a secondary stage to refine the preliminary prediction, further sharpening the high-frequency details. Coupling these three designs enables ProbTalk to generate natural and diverse holistic co-speech motions, outperforming several state-of-the-art methods in qualitative and quantitative evaluations, particularly in terms of realism. Our code and model will be released for research purposes at https://feifeifeiliu.github.io/probtalk/.
4/16/2024
🛸
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
0
0
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
5/14/2024
👨🏫
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
0
0
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
4/30/2024
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
0
0
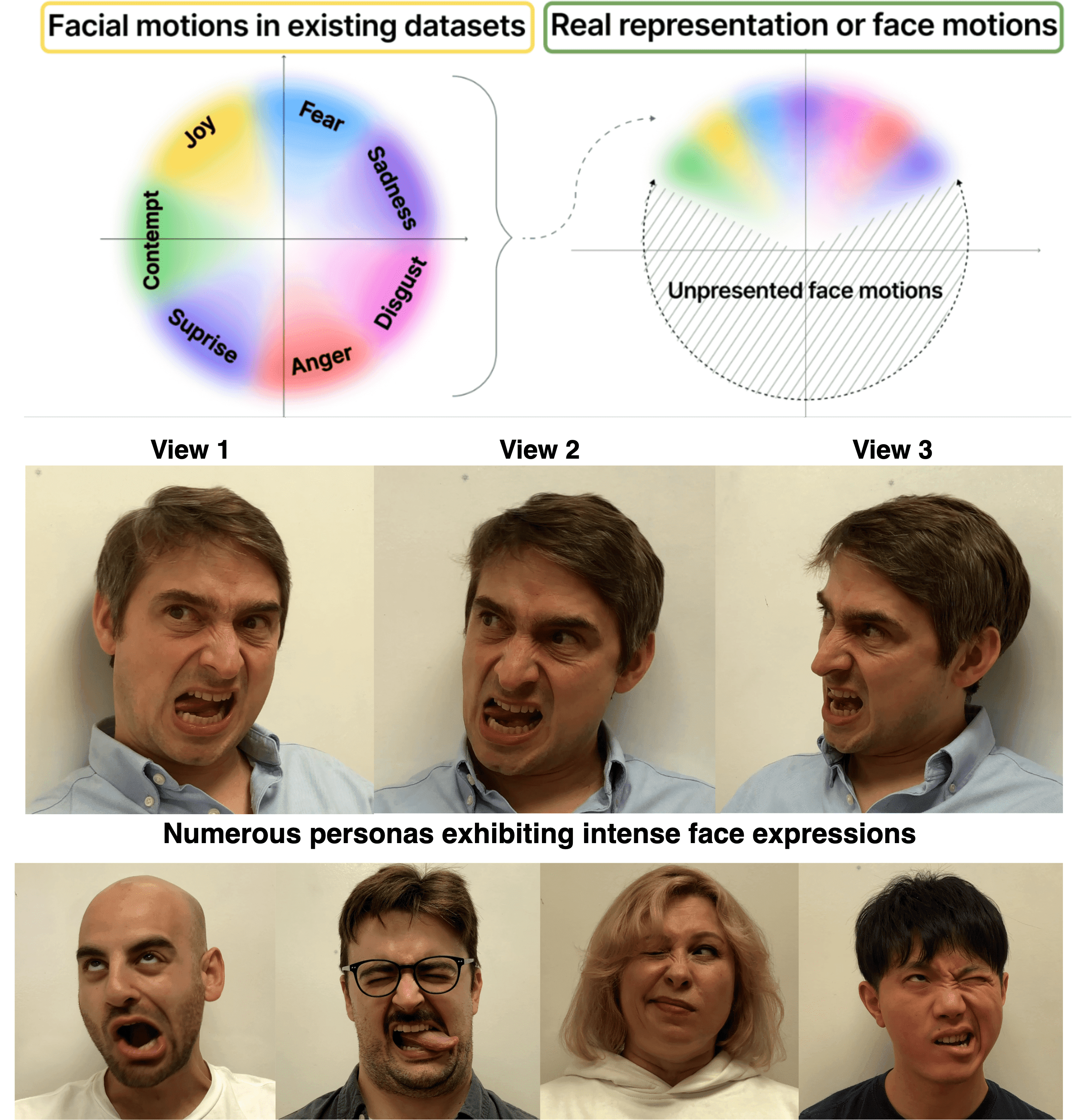
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
5/1/2024