Optimal Data Driven Resource Allocation under Multi-Armed Bandit Observations

0
📊
Sign in to get full access
Overview
- This paper introduces a new strategy for the multi-armed bandit (MAB) problem under side constraints.
- Side constraints model situations where bandit activations are limited by the availability of certain resources that are replenished at a constant rate.
- The main result is the derivation of an asymptotic lower bound for the regret of feasible uniformly fast policies and the construction of policies that achieve this lower bound.
- The paper also provides the explicit form of such policies for different distribution types, including Normal with unknown means and known/unknown variances, and arbitrary discrete distributions with finite support.
Plain English Explanation
The multi-armed bandit (MAB) problem is a fundamental challenge in machine learning and decision-making. It involves a decision-maker who must choose which "arm" (option) to pull from a set of arms, where each arm has an unknown reward distribution. The goal is to maximize the total rewards obtained over time.
In this paper, the researchers introduce a new version of the MAB problem that includes side constraints. Side constraints model situations where the decision-maker's choices are limited by the availability of certain resources, which are replenished at a constant rate. For example, a company might have a limited number of sales representatives that can be assigned to different product lines.
The key contribution of this paper is the development of an asymptotically optimal strategy for the constrained MAB problem. The researchers derive a mathematical lower bound on the "regret" (the difference between the optimal rewards and the actual rewards obtained) that any feasible policy must achieve. They then construct policies that match this lower bound, meaning they are as close to optimal as possible.
The paper also provides the specific form of these optimal policies for different types of reward distributions, including Normal distributions (with known or unknown variances) and discrete distributions with finite support. These results give decision-makers practical tools for navigating MAB problems with resource constraints.
Technical Explanation
The researchers consider a multi-armed bandit (MAB) problem with side constraints, which model situations where the decision-maker's choices are limited by the availability of certain resources. These resources are replenished at a constant rate, introducing an additional layer of complexity compared to the standard MAB problem.
The main technical contribution is the derivation of an asymptotic lower bound for the regret of any feasible uniformly fast policy in the constrained MAB setting. The researchers then construct policies that match this lower bound, making them asymptotically optimal.
Specifically, the paper considers three cases for the unknown reward distributions:
- Normal distributions with unknown means and known variances
- Normal distributions with unknown means and unknown variances
- Arbitrary discrete distributions with finite support
For each case, the researchers provide the explicit form of the asymptotically optimal policies, which can be used by decision-makers to navigate the constrained MAB problem in practice.
The technical analysis involves advanced mathematical tools from stochastic optimization and reinforcement learning, including martingale theory and Lagrangian optimization.
Critical Analysis
The paper introduces an important extension of the classic multi-armed bandit problem by incorporating side constraints, which captures real-world scenarios more accurately. The asymptotic optimality of the proposed policies is a significant theoretical achievement.
However, the paper does not address the finite-time performance of the policies, which is crucial for practical applications. Additionally, the assumptions of known or bounded variances, and finite support for the reward distributions, may not always hold in practice.
Further research could explore the robustness of the policies to model misspecification, as well as the computational complexity of implementing the optimal policies in real-time decision-making. Empirical evaluations on realistic use cases would also help validate the practical utility of the proposed approach.
Conclusion
This paper introduces the first asymptotically optimal strategy for the multi-armed bandit problem under side constraints, which model situations where the decision-maker's choices are limited by the availability of certain resources. The researchers derive a mathematical lower bound on the regret of any feasible policy and construct policies that match this bound, making them as close to optimal as possible.
The explicit forms of the optimal policies provided in the paper for different types of reward distributions offer decision-makers practical tools for navigating constrained MAB problems. While the theoretical results are significant, further research is needed to address the finite-time performance and robustness of these policies in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Optimal Data Driven Resource Allocation under Multi-Armed Bandit Observations
Apostolos N. Burnetas, Odysseas Kanavetas, Michael N. Katehakis
This paper introduces the first asymptotically optimal strategy for a multi armed bandit (MAB) model under side constraints. The side constraints model situations in which bandit activations are limited by the availability of certain resources that are replenished at a constant rate. The main result involves the derivation of an asymptotic lower bound for the regret of feasible uniformly fast policies and the construction of policies that achieve this lower bound, under pertinent conditions. Further, we provide the explicit form of such policies for the case in which the unknown distributions are Normal with unknown means and known variances, for the case of Normal distributions with unknown means and unknown variances and for the case of arbitrary discrete distributions with finite support.
Read more9/14/2024
0
Data-Driven Upper Confidence Bounds with Near-Optimal Regret for Heavy-Tailed Bandits
Ambrus Tam'as, Szabolcs Szentp'eteri, Bal'azs Csan'ad Cs'aji
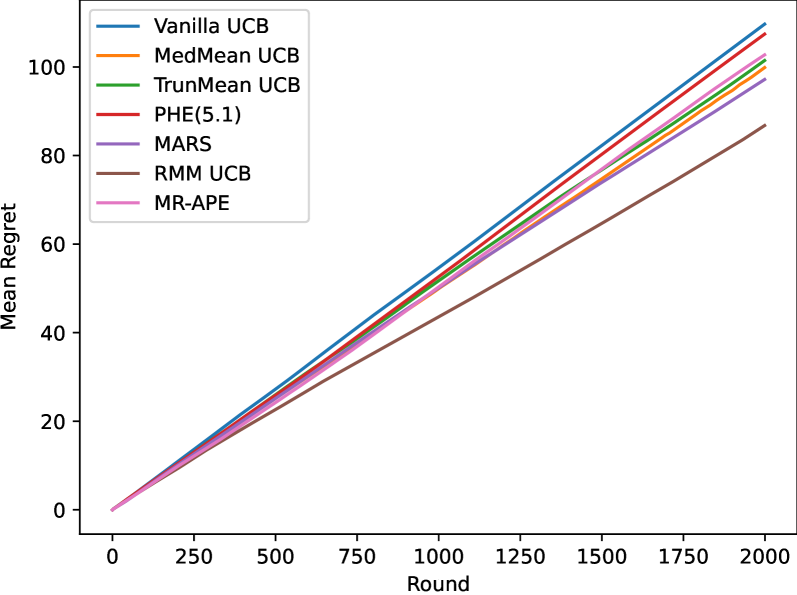
Stochastic multi-armed bandits (MABs) provide a fundamental reinforcement learning model to study sequential decision making in uncertain environments. The upper confidence bounds (UCB) algorithm gave birth to the renaissance of bandit algorithms, as it achieves near-optimal regret rates under various moment assumptions. Up until recently most UCB methods relied on concentration inequalities leading to confidence bounds which depend on moment parameters, such as the variance proxy, that are usually unknown in practice. In this paper, we propose a new distribution-free, data-driven UCB algorithm for symmetric reward distributions, which needs no moment information. The key idea is to combine a refined, one-sided version of the recently developed resampled median-of-means (RMM) method with UCB. We prove a near-optimal regret bound for the proposed anytime, parameter-free RMM-UCB method, even for heavy-tailed distributions.
Read more6/11/2024
🌀
0
Blocking Bandits
Soumya Basu, Rajat Sen, Sujay Sanghavi, Sanjay Shakkottai
We consider a novel stochastic multi-armed bandit setting, where playing an arm makes it unavailable for a fixed number of time slots thereafter. This models situations where reusing an arm too often is undesirable (e.g. making the same product recommendation repeatedly) or infeasible (e.g. compute job scheduling on machines). We show that with prior knowledge of the rewards and delays of all the arms, the problem of optimizing cumulative reward does not admit any pseudo-polynomial time algorithm (in the number of arms) unless randomized exponential time hypothesis is false, by mapping to the PINWHEEL scheduling problem. Subsequently, we show that a simple greedy algorithm that plays the available arm with the highest reward is asymptotically $(1-1/e)$ optimal. When the rewards are unknown, we design a UCB based algorithm which is shown to have $c log T + o(log T)$ cumulative regret against the greedy algorithm, leveraging the free exploration of arms due to the unavailability. Finally, when all the delays are equal the problem reduces to Combinatorial Semi-bandits providing us with a lower bound of $c' log T+ omega(log T)$.
Read more7/31/2024
🏅
0
Provably Efficient Reinforcement Learning for Adversarial Restless Multi-Armed Bandits with Unknown Transitions and Bandit Feedback
Guojun Xiong, Jian Li
Restless multi-armed bandits (RMAB) play a central role in modeling sequential decision making problems under an instantaneous activation constraint that at most B arms can be activated at any decision epoch. Each restless arm is endowed with a state that evolves independently according to a Markov decision process regardless of being activated or not. In this paper, we consider the task of learning in episodic RMAB with unknown transition functions and adversarial rewards, which can change arbitrarily across episodes. Further, we consider a challenging but natural bandit feedback setting that only adversarial rewards of activated arms are revealed to the decision maker (DM). The goal of the DM is to maximize its total adversarial rewards during the learning process while the instantaneous activation constraint must be satisfied in each decision epoch. We develop a novel reinforcement learning algorithm with two key contributors: a novel biased adversarial reward estimator to deal with bandit feedback and unknown transitions, and a low-complexity index policy to satisfy the instantaneous activation constraint. We show $tilde{mathcal{O}}(Hsqrt{T})$ regret bound for our algorithm, where $T$ is the number of episodes and $H$ is the episode length. To our best knowledge, this is the first algorithm to ensure $tilde{mathcal{O}}(sqrt{T})$ regret for adversarial RMAB in our considered challenging settings.
Read more5/3/2024