Multi-Armed Bandits with Interference

0

Sign in to get full access
Overview
- This paper explores the problem of Multi-Armed Bandits with Interference, where the rewards obtained by one agent can affect the rewards of other agents due to interference in a network.
- The authors propose a new algorithm called Interference-Aware Upper Confidence Bound (IA-UCB) that takes into account the interference between agents to improve decision-making.
- Experiments show that IA-UCB outperforms existing algorithms in various network interference scenarios, demonstrating the importance of considering interference in multi-agent decision-making problems.
Plain English Explanation
Imagine you're running an online advertising campaign, and each ad is like an "arm" you can pull on a slot machine (a "multi-armed bandit"). The goal is to figure out which ads are the most effective so you can show them more often and make more money.
However, the success of one ad can actually affect the success of other ads, kind of like how a popular product in a store might make other products nearby less appealing to customers. This "interference" between the ads makes it harder to figure out which ones are truly the best.
The researchers in this paper came up with a new algorithm called IA-UCB that tries to account for this interference between the ads. By understanding how the ads influence each other, IA-UCB can make smarter choices about which ads to show more often, leading to better overall performance compared to existing algorithms that don't consider interference.
Technical Explanation
The paper introduces the Multi-Armed Bandits with Interference problem, where the reward obtained by one agent can affect the rewards of other agents due to interference in a network. The authors propose a new algorithm called Interference-Aware Upper Confidence Bound (IA-UCB) that incorporates information about the interference structure to improve decision-making.
IA-UCB works by maintaining estimates of both the mean rewards and the interference effects between agents. It then uses these estimates to compute an upper confidence bound (UCB) for each arm, which balances exploration (trying new arms) and exploitation (focusing on the best arms). By considering the interference, IA-UCB can make more informed decisions about which arms to pull.
The authors evaluate IA-UCB on various network interference scenarios, including collaborative multi-agent heterogeneous multi-armed bandits, adversarial attacks on combinatorial multi-armed bandits, and federated multi-armed bandits under Byzantine attacks. The results show that IA-UCB outperforms existing algorithms, demonstrating the importance of considering interference in multi-agent decision-making problems.
Critical Analysis
The paper provides a thorough theoretical analysis of the IA-UCB algorithm, including regret bounds and convergence guarantees. However, the practical implications of the research could be further explored.
For example, the paper does not discuss how to estimate the interference parameters in real-world scenarios, where the interference structure may not be known a priori. Additionally, the experiments are limited to synthetic network topologies, and it would be valuable to see how IA-UCB performs on more realistic combinatorial multivariant multi-armed bandit applications.
Furthermore, the paper does not address the potential computational complexity of IA-UCB, especially in large-scale multi-agent systems. Exploring efficient implementation strategies and scalability concerns would be an important next step.
Conclusion
This paper presents a novel algorithm, IA-UCB, for addressing the Multi-Armed Bandits with Interference problem, where the rewards of agents are affected by interference in a network. The authors demonstrate the superiority of IA-UCB over existing approaches through extensive experiments, highlighting the importance of considering interference in multi-agent decision-making.
The research has implications for a wide range of applications, from online advertising to resource allocation in wireless networks. By explicitly modeling and accounting for interference, IA-UCB can lead to more efficient and effective decision-making in these domains. As the complexity of multi-agent systems continues to grow, the insights from this paper may inspire further advancements in the field of multi-armed bandits with interference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Armed Bandits with Interference
Su Jia, Peter Frazier, Nathan Kallus
Experimentation with interference poses a significant challenge in contemporary online platforms. Prior research on experimentation with interference has concentrated on the final output of a policy. The cumulative performance, while equally crucial, is less well understood. To address this gap, we introduce the problem of {em Multi-armed Bandits with Interference} (MABI), where the learner assigns an arm to each of $N$ experimental units over a time horizon of $T$ rounds. The reward of each unit in each round depends on the treatments of {em all} units, where the influence of a unit decays in the spatial distance between units. Furthermore, we employ a general setup wherein the reward functions are chosen by an adversary and may vary arbitrarily across rounds and units. We first show that switchback policies achieve an optimal {em expected} regret $tilde O(sqrt T)$ against the best fixed-arm policy. Nonetheless, the regret (as a random variable) for any switchback policy suffers a high variance, as it does not account for $N$. We propose a cluster randomization policy whose regret (i) is optimal in {em expectation} and (ii) admits a high probability bound that vanishes in $N$.
Read more7/17/2024
0
Multi-Armed Bandits with Network Interference
Abhineet Agarwal, Anish Agarwal, Lorenzo Masoero, Justin Whitehouse
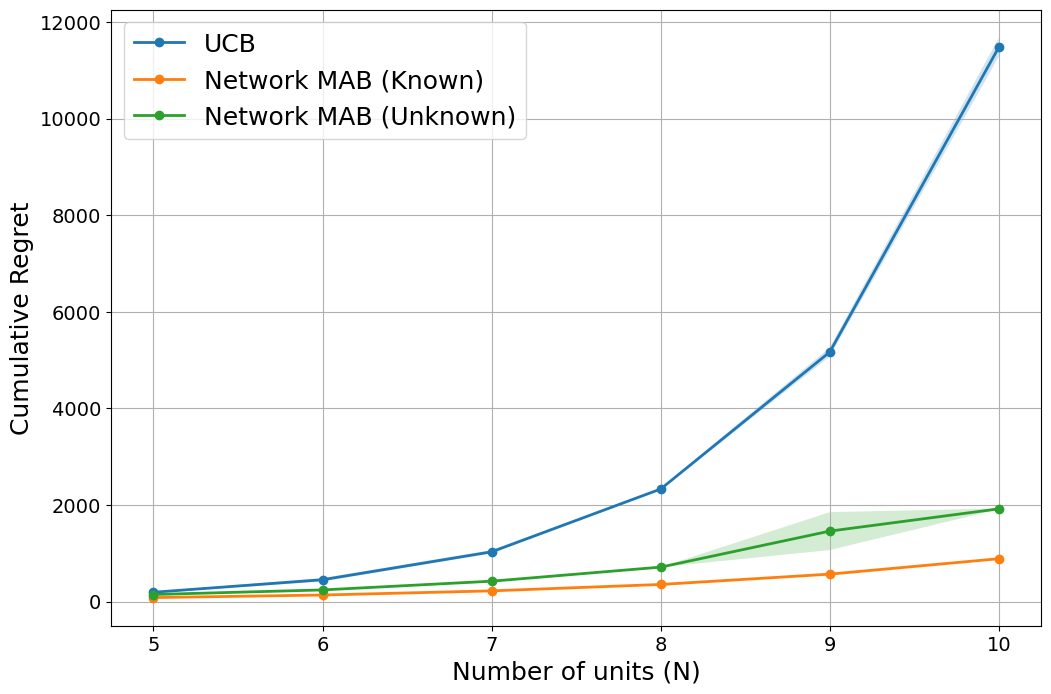
Online experimentation with interference is a common challenge in modern applications such as e-commerce and adaptive clinical trials in medicine. For example, in online marketplaces, the revenue of a good depends on discounts applied to competing goods. Statistical inference with interference is widely studied in the offline setting, but far less is known about how to adaptively assign treatments to minimize regret. We address this gap by studying a multi-armed bandit (MAB) problem where a learner (e-commerce platform) sequentially assigns one of possible $mathcal{A}$ actions (discounts) to $N$ units (goods) over $T$ rounds to minimize regret (maximize revenue). Unlike traditional MAB problems, the reward of each unit depends on the treatments assigned to other units, i.e., there is interference across the underlying network of units. With $mathcal{A}$ actions and $N$ units, minimizing regret is combinatorially difficult since the action space grows as $mathcal{A}^N$. To overcome this issue, we study a sparse network interference model, where the reward of a unit is only affected by the treatments assigned to $s$ neighboring units. We use tools from discrete Fourier analysis to develop a sparse linear representation of the unit-specific reward $r_n: [mathcal{A}]^N rightarrow mathbb{R} $, and propose simple, linear regression-based algorithms to minimize regret. Importantly, our algorithms achieve provably low regret both when the learner observes the interference neighborhood for all units and when it is unknown. This significantly generalizes other works on this topic which impose strict conditions on the strength of interference on a known network, and also compare regret to a markedly weaker optimal action. Empirically, we corroborate our theoretical findings via numerical simulations.
Read more5/30/2024

0
Multi-agent Multi-armed Bandits with Stochastic Sharable Arm Capacities
Hong Xie, Jinyu Mo, Defu Lian, Jie Wang, Enhong Chen
Motivated by distributed selection problems, we formulate a new variant of multi-player multi-armed bandit (MAB) model, which captures stochastic arrival of requests to each arm, as well as the policy of allocating requests to players. The challenge is how to design a distributed learning algorithm such that players select arms according to the optimal arm pulling profile (an arm pulling profile prescribes the number of players at each arm) without communicating to each other. We first design a greedy algorithm, which locates one of the optimal arm pulling profiles with a polynomial computational complexity. We also design an iterative distributed algorithm for players to commit to an optimal arm pulling profile with a constant number of rounds in expectation. We apply the explore then commit (ETC) framework to address the online setting when model parameters are unknown. We design an exploration strategy for players to estimate the optimal arm pulling profile. Since such estimates can be different across different players, it is challenging for players to commit. We then design an iterative distributed algorithm, which guarantees that players can arrive at a consensus on the optimal arm pulling profile in only M rounds. We conduct experiments to validate our algorithm.
Read more8/21/2024
🌀
0
Blocking Bandits
Soumya Basu, Rajat Sen, Sujay Sanghavi, Sanjay Shakkottai
We consider a novel stochastic multi-armed bandit setting, where playing an arm makes it unavailable for a fixed number of time slots thereafter. This models situations where reusing an arm too often is undesirable (e.g. making the same product recommendation repeatedly) or infeasible (e.g. compute job scheduling on machines). We show that with prior knowledge of the rewards and delays of all the arms, the problem of optimizing cumulative reward does not admit any pseudo-polynomial time algorithm (in the number of arms) unless randomized exponential time hypothesis is false, by mapping to the PINWHEEL scheduling problem. Subsequently, we show that a simple greedy algorithm that plays the available arm with the highest reward is asymptotically $(1-1/e)$ optimal. When the rewards are unknown, we design a UCB based algorithm which is shown to have $c log T + o(log T)$ cumulative regret against the greedy algorithm, leveraging the free exploration of arms due to the unavailability. Finally, when all the delays are equal the problem reduces to Combinatorial Semi-bandits providing us with a lower bound of $c' log T+ omega(log T)$.
Read more7/31/2024