Optimal Flow Admission Control in Edge Computing via Safe Reinforcement Learning
2404.05564
0
0
Abstract
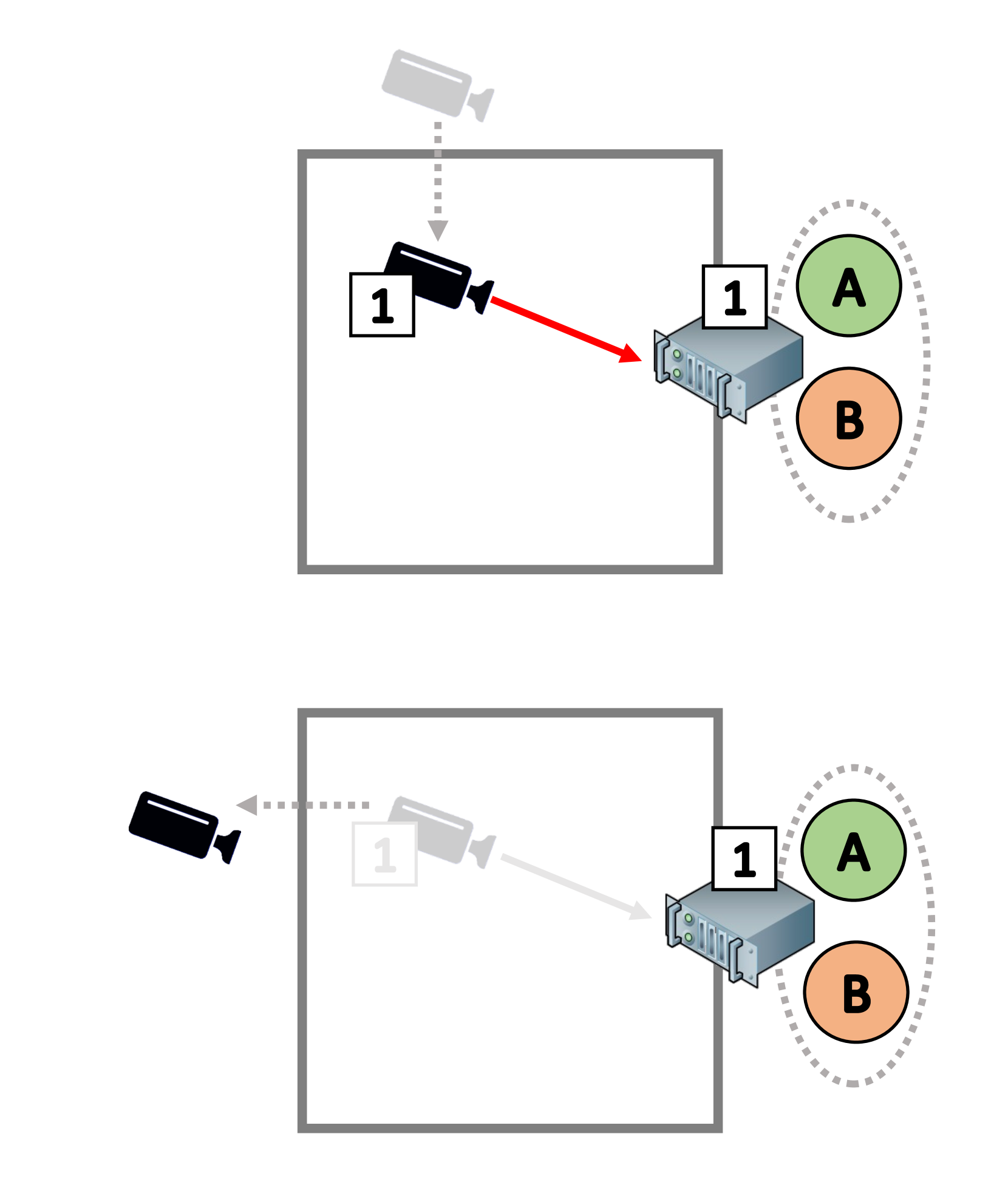
With the uptake of intelligent data-driven applications, edge computing infrastructures necessitate a new generation of admission control algorithms to maximize system performance under limited and highly heterogeneous resources. In this paper, we study how to optimally select information flows which belong to different classes and dispatch them to multiple edge servers where deployed applications perform flow analytic tasks. The optimal policy is obtained via constrained Markov decision process (CMDP) theory accounting for the demand of each edge application for specific classes of flows, the constraints on computing capacity of edge servers and of the access network. We develop DR-CPO, a specialized primal-dual Safe Reinforcement Learning (SRL) method which solves the resulting optimal admission control problem by reward decomposition. DR-CPO operates optimal decentralized control and mitigates effectively state-space explosion while preserving optimality. Compared to existing Deep Reinforcement Learning (DRL) solutions, extensive results show that DR-CPO achieves 15% higher reward on a wide variety of environments, while requiring on average only 50% of the amount of learning episodes to converge. Finally, we show how to match DR-CPO and load-balancing to dispatch optimally information streams to available edge servers and further improve system performance.
Create account to get full access
Overview
- This paper proposes a safe reinforcement learning approach for optimal flow admission control in edge computing.
- The goal is to develop a system that can efficiently manage the admission of data flows to edge computing resources, while ensuring safety and reliability.
- The authors leverage concepts from intervention-assisted policy gradient methods, queue-aware network control algorithms, and multi-agent reinforcement learning for control-theoretic safety to achieve this.
Plain English Explanation
Edge computing is an emerging technology that brings computing resources closer to the devices and sensors that generate data, rather than relying on distant cloud servers. This can improve performance and reduce latency for certain applications. However, managing the flow of data to these edge computing resources can be challenging, as there are often more requests than the system can handle at any given time.
This paper proposes a solution using machine learning, specifically reinforcement learning. The idea is to train an intelligent system to decide which data flows should be admitted to the edge computing resources and which should be rejected or delayed. This system would learn from experience to make these decisions in an optimal way, balancing factors like performance, resource utilization, and user satisfaction.
The key innovation is that the system is designed to be "safe" - it has mechanisms to ensure that it doesn't make decisions that could lead to unacceptable outcomes, like the system crashing or users experiencing severe delays. This is achieved by incorporating ideas from related research on intervention-assisted policy gradient methods, queue-aware network control algorithms, and multi-agent reinforcement learning for control-theoretic safety.
The ultimate goal is to create a more reliable and efficient edge computing system that can handle the growing demand for low-latency, high-performance computing at the edge of the network.
Technical Explanation
The paper presents a reinforcement learning-based approach for optimal flow admission control in edge computing environments. The key components of the system include:
-
Edge Computing Model: The authors define an edge computing system with multiple edge servers, each with limited computing resources. Data flows, representing applications or services, arrive at the edge and must be admitted for processing.
-
Reinforcement Learning Agent: The core of the system is a reinforcement learning agent that learns to make optimal decisions about which data flows to admit and which to reject or delay. The agent's goal is to maximize a reward function that captures factors like resource utilization, user experience, and system stability.
-
Safety Mechanisms: To ensure the system operates safely, the authors incorporate techniques from intervention-assisted policy gradient methods, queue-aware network control algorithms, and multi-agent reinforcement learning for control-theoretic safety. These include constraints on the agent's actions, safety monitors to detect potential issues, and intervention mechanisms to override the agent's decisions if necessary.
-
Training and Evaluation: The authors train and evaluate the reinforcement learning agent using simulations of the edge computing environment. They compare the performance of their approach to baseline admission control strategies and demonstrate improvements in metrics like resource utilization, user experience, and system stability.
Critical Analysis
The paper presents a well-designed and promising approach to the challenge of optimal flow admission control in edge computing. The incorporation of safety mechanisms is a particularly important contribution, as it helps to address a crucial concern in real-world deployment of such systems.
However, the paper does not explore the potential challenges and limitations of this approach. For example, it would be helpful to understand how the system might perform under extreme conditions, such as sudden spikes in demand or hardware failures. Additionally, the authors could have discussed the scalability of their approach as the number of edge servers and data flows increases.
It would also be valuable to see a more thorough exploration of the trade-offs between different performance metrics, such as resource utilization and user experience. The paper focuses on optimizing a single reward function, but in practice, there may be conflicting objectives that need to be balanced.
Overall, the research presented in this paper is a significant step forward in the field of edge computing and reinforcement learning. With further development and testing, this approach could potentially be applied to a wide range of real-world scenarios, such as solving real-world optimization problems using proximal algorithms or proximal policy optimization-based intelligent home solar control.
Conclusion
This paper proposes a safe reinforcement learning approach for optimal flow admission control in edge computing environments. The key innovation is the incorporation of safety mechanisms to ensure the system operates reliably, even in the face of complex and dynamic conditions.
The results demonstrate the potential of this approach to improve resource utilization, user experience, and system stability in edge computing scenarios. While the paper does not address all possible challenges and limitations, it represents a significant advancement in the field and lays the groundwork for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Constraint-Conditioned Policy Optimization for Versatile Safe Reinforcement Learning
Yihang Yao, Zuxin Liu, Zhepeng Cen, Jiacheng Zhu, Wenhao Yu, Tingnan Zhang, Ding Zhao
0
0
Safe reinforcement learning (RL) focuses on training reward-maximizing agents subject to pre-defined safety constraints. Yet, learning versatile safe policies that can adapt to varying safety constraint requirements during deployment without retraining remains a largely unexplored and challenging area. In this work, we formulate the versatile safe RL problem and consider two primary requirements: training efficiency and zero-shot adaptation capability. To address them, we introduce the Conditioned Constrained Policy Optimization (CCPO) framework, consisting of two key modules: (1) Versatile Value Estimation (VVE) for approximating value functions under unseen threshold conditions, and (2) Conditioned Variational Inference (CVI) for encoding arbitrary constraint thresholds during policy optimization. Our extensive experiments demonstrate that CCPO outperforms the baselines in terms of safety and task performance while preserving zero-shot adaptation capabilities to different constraint thresholds data-efficiently. This makes our approach suitable for real-world dynamic applications.
5/1/2024
🏅
End-to-End Reinforcement Learning of Curative Curtailment with Partial Measurement Availability
Hinrikus Wolf, Luis Bottcher, Sarra Bouchkati, Philipp Lutat, Jens Breitung, Bastian Jung, Tina Mollemann, Viktor Todosijevi'c, Jan Schiefelbein-Lach, Oliver Pohl, Andreas Ulbig, Martin Grohe
0
0
In the course of the energy transition, the expansion of generation and consumption will change, and many of these technologies, such as PV systems, electric cars and heat pumps, will influence the power flow, especially in the distribution grids. Scalable methods that can make decisions for each grid connection are needed to enable congestion-free grid operation in the distribution grids. This paper presents a novel end-to-end approach to resolving congestion in distribution grids with deep reinforcement learning. Our architecture learns to curtail power and set appropriate reactive power to determine a non-congested and, thus, feasible grid state. State-of-the-art methods such as the optimal power flow (OPF) demand high computational costs and detailed measurements of every bus in a grid. In contrast, the presented method enables decisions under sparse information with just some buses observable in the grid. Distribution grids are generally not yet fully digitized and observable, so this method can be used for decision-making on the majority of low-voltage grids. On a real low-voltage grid the approach resolves 100% of violations in the voltage band and 98.8% of asset overloads. The results show that decisions can also be made on real grids that guarantee sufficient quality for congestion-free grid operation.
6/21/2024
🏅
Implementing Reinforcement Learning Datacenter Congestion Control in NVIDIA NICs
Benjamin Fuhrer, Yuval Shpigelman, Chen Tessler, Shie Mannor, Gal Chechik, Eitan Zahavi, Gal Dalal
0
0
As communication protocols evolve, datacenter network utilization increases. As a result, congestion is more frequent, causing higher latency and packet loss. Combined with the increasing complexity of workloads, manual design of congestion control (CC) algorithms becomes extremely difficult. This calls for the development of AI approaches to replace the human effort. Unfortunately, it is currently not possible to deploy AI models on network devices due to their limited computational capabilities. Here, we offer a solution to this problem by building a computationally-light solution based on a recent reinforcement learning CC algorithm [arXiv:2207.02295]. We reduce the inference time of RL-CC by x500 by distilling its complex neural network into decision trees. This transformation enables real-time inference within the $mu$-sec decision-time requirement, with a negligible effect on quality. We deploy the transformed policy on NVIDIA NICs in a live cluster. Compared to popular CC algorithms used in production, RL-CC is the only method that performs well on all benchmarks tested over a large range of number of flows. It balances multiple metrics simultaneously: bandwidth, latency, and packet drops. These results suggest that data-driven methods for CC are feasible, challenging the prior belief that handcrafted heuristics are necessary to achieve optimal performance.
6/4/2024
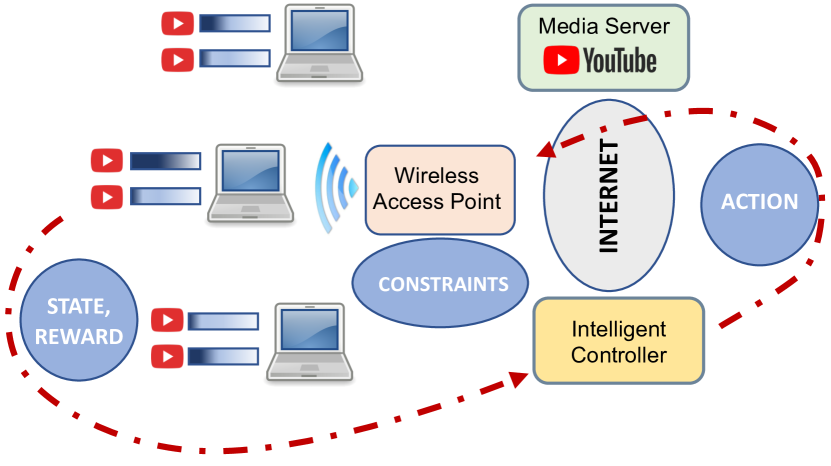
Structured Reinforcement Learning for Media Streaming at the Wireless Edge
Archana Bura, Sarat Chandra Bobbili, Shreyas Rameshkumar, Desik Rengarajan, Dileep Kalathil, Srinivas Shakkottai
0
0
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
4/12/2024