Constraint-Conditioned Policy Optimization for Versatile Safe Reinforcement Learning
2310.03718
0
0
🛠️
Abstract
Safe reinforcement learning (RL) focuses on training reward-maximizing agents subject to pre-defined safety constraints. Yet, learning versatile safe policies that can adapt to varying safety constraint requirements during deployment without retraining remains a largely unexplored and challenging area. In this work, we formulate the versatile safe RL problem and consider two primary requirements: training efficiency and zero-shot adaptation capability. To address them, we introduce the Conditioned Constrained Policy Optimization (CCPO) framework, consisting of two key modules: (1) Versatile Value Estimation (VVE) for approximating value functions under unseen threshold conditions, and (2) Conditioned Variational Inference (CVI) for encoding arbitrary constraint thresholds during policy optimization. Our extensive experiments demonstrate that CCPO outperforms the baselines in terms of safety and task performance while preserving zero-shot adaptation capabilities to different constraint thresholds data-efficiently. This makes our approach suitable for real-world dynamic applications.
Create account to get full access
Overview
- This paper focuses on the problem of "versatile safe reinforcement learning (RL)," which aims to train agents that can adapt to varying safety constraint requirements during deployment without retraining.
- The key requirements addressed are training efficiency and zero-shot adaptation capability, which the authors address through their proposed "Conditioned Constrained Policy Optimization (CCPO)" framework.
- CCPO consists of two main modules: Versatile Value Estimation (VVE) for approximating value functions under unseen threshold conditions, and Conditioned Variational Inference (CVI) for encoding arbitrary constraint thresholds during policy optimization.
Plain English Explanation
Reinforcement learning (RL) is a powerful technique for training agents to accomplish tasks by rewarding desired behaviors. However, in many real-world applications, it's crucial that these agents also adhere to certain safety constraints, such as not harming humans or damaging property.
The challenge addressed in this paper is how to train RL agents that can flexibly adapt to different safety requirements during actual use, without having to retrain the agent from scratch each time. The authors propose a framework called CCPO that aims to solve this problem.
At a high level, CCPO has two key components:
-
Versatile Value Estimation (VVE): This module allows the agent to estimate the "value" (i.e., expected future reward) of its actions, even in situations with safety constraints it hasn't encountered during training. This enables the agent to adapt to new constraint requirements without retraining.
-
Conditioned Variational Inference (CVI): This component helps the agent learn a policy (i.e., decision-making strategy) that can be easily "conditioned" on different safety constraint thresholds. This allows the agent to quickly adjust its behavior to comply with new constraints, again without the need for retraining.
By combining these two innovations, the authors show that their CCPO framework can train RL agents that are both efficient at learning and highly adaptable to changing safety requirements in real-world deployments.
Technical Explanation
The key idea behind the Conditioned Constrained Policy Optimization (CCPO) framework is to decouple the policy learning process from the specifics of the safety constraints. This allows the agent to learn a versatile policy that can be efficiently adapted to different constraint thresholds during deployment, without the need for expensive retraining.
The first module, Versatile Value Estimation (VVE), approximates the value function (i.e., expected future reward) under different constraint thresholds, even those not seen during training. This is achieved by conditioning the value function on the constraint threshold, allowing the agent to reason about the consequences of its actions under unseen constraint conditions.
The second module, Conditioned Variational Inference (CVI), encodes the constraint threshold as a latent variable in the agent's policy. This enables the policy to be conditioned on the constraint threshold, allowing the agent to quickly adapt its behavior to comply with new constraints during deployment, without the need for retraining.
The authors evaluate CCPO on a range of simulated environments and demonstrate that it outperforms baseline methods in terms of safety and task performance, while preserving zero-shot adaptation capabilities to different constraint thresholds in a data-efficient manner. This makes CCPO a promising approach for real-world applications where safety and adaptability are crucial, such as robotics or resource allocation optimization.
Critical Analysis
The CCPO framework presented in this paper addresses an important and relevant problem in the field of safe reinforcement learning. The authors' approach of decoupling policy learning from specific constraint thresholds is a clever and promising solution to the challenge of versatile safe RL.
One potential limitation of the research is the reliance on simulated environments, which may not fully capture the complexity and uncertainty of real-world scenarios. While the authors demonstrate strong zero-shot adaptation capabilities, further validation in more realistic settings would be valuable to assess the approach's practical viability.
Additionally, the paper does not delve deeply into the potential computational and sample efficiency trade-offs between the VVE and CVI modules. Understanding the relative importance and interplay of these components could help inform future refinements and optimizations of the CCPO framework.
Overall, the CCPO framework represents an important step forward in the field of safe reinforcement learning. By enabling agents to adapt to varying safety constraints without the need for costly retraining, this research has the potential to unlock new applications and real-world deployments of RL systems where safety is a critical concern.
Conclusion
This paper presents the Conditioned Constrained Policy Optimization (CCPO) framework, a novel approach to the problem of versatile safe reinforcement learning. CCPO addresses the key requirements of training efficiency and zero-shot adaptation capability, allowing RL agents to flexibly adapt to changing safety constraint requirements during deployment without the need for retraining.
The two core innovations of CCPO – Versatile Value Estimation (VVE) and Conditioned Variational Inference (CVI) – enable the agent to reason about the consequences of its actions under unseen constraint conditions and quickly adjust its policy to comply with new constraints, respectively. The authors' extensive experiments demonstrate the effectiveness of CCPO in balancing safety and task performance, making it a promising solution for real-world applications where adaptability and safety are crucial.
As the field of reinforcement learning continues to advance, the ability to deploy RL agents in dynamic, safety-critical environments will become increasingly important. The CCPO framework represents an important step forward in addressing this challenge, and its potential impact extends across domains such as robotics, resource optimization, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

State-wise Constrained Policy Optimization
Weiye Zhao, Rui Chen, Yifan Sun, Tianhao Wei, Changliu Liu
0
0
Reinforcement Learning (RL) algorithms have shown tremendous success in simulation environments, but their application to real-world problems faces significant challenges, with safety being a major concern. In particular, enforcing state-wise constraints is essential for many challenging tasks such as autonomous driving and robot manipulation. However, existing safe RL algorithms under the framework of Constrained Markov Decision Process (CMDP) do not consider state-wise constraints. To address this gap, we propose State-wise Constrained Policy Optimization (SCPO), the first general-purpose policy search algorithm for state-wise constrained reinforcement learning. SCPO provides guarantees for state-wise constraint satisfaction in expectation. In particular, we introduce the framework of Maximum Markov Decision Process, and prove that the worst-case safety violation is bounded under SCPO. We demonstrate the effectiveness of our approach on training neural network policies for extensive robot locomotion tasks, where the agent must satisfy a variety of state-wise safety constraints. Our results show that SCPO significantly outperforms existing methods and can handle state-wise constraints in high-dimensional robotics tasks.
6/19/2024
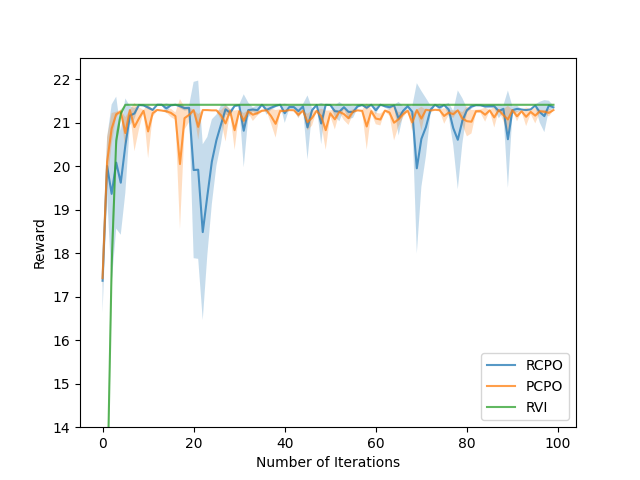
Constrained Reinforcement Learning Under Model Mismatch
Zhongchang Sun, Sihong He, Fei Miao, Shaofeng Zou
0
0
Existing studies on constrained reinforcement learning (RL) may obtain a well-performing policy in the training environment. However, when deployed in a real environment, it may easily violate constraints that were originally satisfied during training because there might be model mismatch between the training and real environments. To address the above challenge, we formulate the problem as constrained RL under model uncertainty, where the goal is to learn a good policy that optimizes the reward and at the same time satisfy the constraint under model mismatch. We develop a Robust Constrained Policy Optimization (RCPO) algorithm, which is the first algorithm that applies to large/continuous state space and has theoretical guarantees on worst-case reward improvement and constraint violation at each iteration during the training. We demonstrate the effectiveness of our algorithm on a set of RL tasks with constraints.
5/6/2024
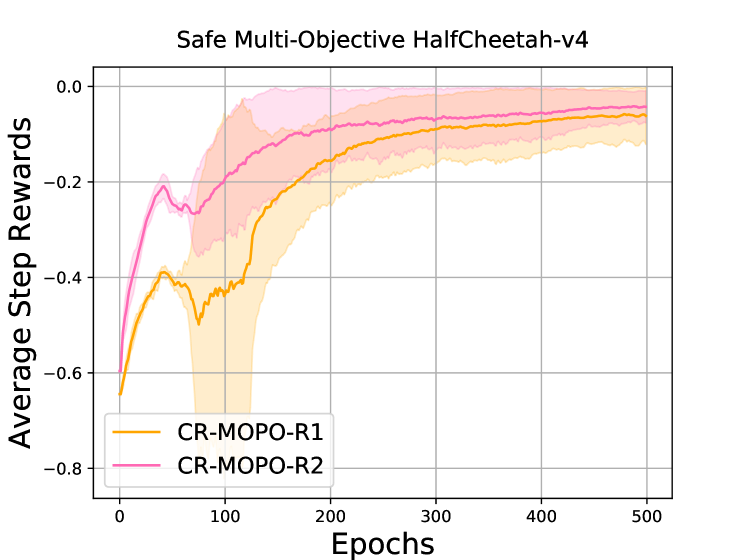
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
0
0
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
5/28/2024
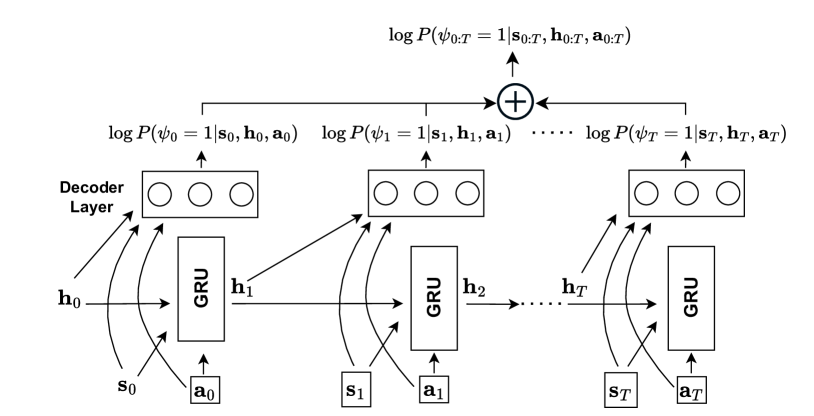
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
0
0
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
5/7/2024