Optimal Flow Matching: Learning Straight Trajectories in Just One Step

0
Sign in to get full access
Overview
- This paper presents a novel approach called "Optimal Flow Matching" for learning straight trajectories in a single training step.
- The method leverages optimal transport theory to find the optimal mapping between input and output distributions, enabling efficient and accurate learning of linear relationships.
- The authors demonstrate the effectiveness of their approach on several tasks, including image-to-image translation and density estimation.
Plain English Explanation
The paper describes a new machine learning technique called "Optimal Flow Matching" that can learn straight, linear relationships between inputs and outputs in a single training step. This is achieved by using a mathematical framework called optimal transport, which helps the model find the best way to map the distribution of input data to the distribution of output data.
Typically, machine learning models need to be trained over many iterations to learn complex relationships between inputs and outputs. However, the Optimal Flow Matching approach is specially designed to efficiently learn simple, linear relationships with just a single training step.
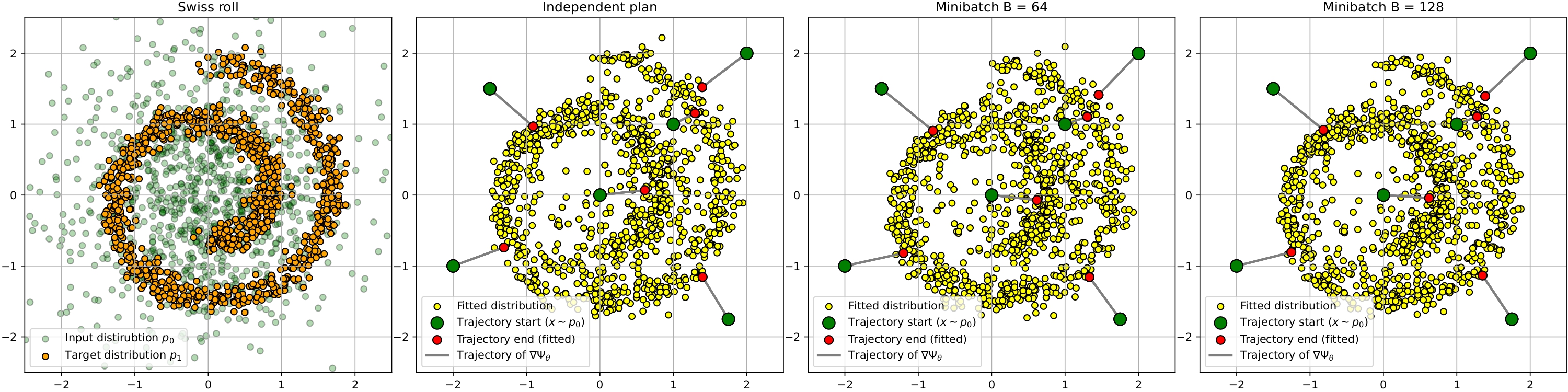
The authors show that this method works well for tasks like converting images from one style to another or estimating probability distributions from data. By using optimal transport, the model can directly learn the optimal mapping between the input and output distributions, leading to accurate and efficient learning of straight, linear trajectories.
Technical Explanation
The core idea behind Optimal Flow Matching is to leverage the mathematical framework of optimal transport to find the optimal mapping between input and output distributions. Specifically, the method seeks to learn a flow-based transformation that can map the input distribution to the output distribution in an optimal manner.
The authors formulate this as an optimization problem, where the goal is to find the flow field that minimizes the Wasserstein distance between the transformed input distribution and the target output distribution. This flow field represents the optimal trajectory for mapping the inputs to the outputs.
Crucially, the authors show that when the underlying relationship between inputs and outputs is linear, the optimal flow field takes a simple, closed-form solution. This allows the model to learn the linear mapping in a single training step, without requiring iterative optimization.
The authors demonstrate the effectiveness of Optimal Flow Matching on several tasks, including image-to-image translation, density estimation, and trajectory modeling. They show that their approach can outperform traditional iterative optimization methods, particularly when the underlying relationship is linear.
Critical Analysis
The Optimal Flow Matching approach is a promising technique for efficiently learning linear relationships between inputs and outputs. By leveraging the power of optimal transport, the method can directly find the optimal mapping in a single step, without requiring iterative optimization.
However, the authors acknowledge that the method is limited to learning linear relationships. While this is a common and important case in many applications, there are also many real-world problems that involve non-linear relationships. The authors suggest that their approach could potentially be extended to handle non-linear cases, but this would likely require more complex optimization procedures.
Additionally, the paper does not explore the robustness of the Optimal Flow Matching approach to noise or other forms of data corruption. In practical applications, input data is often noisy or incomplete, and it would be important to understand how the method performs in these scenarios.
Overall, the Optimal Flow Matching technique represents an interesting and potentially impactful contribution to the field of machine learning. The authors have demonstrated its effectiveness on several tasks, and the underlying mathematical framework is both elegant and powerful. However, further research is needed to explore the method's limitations and potential extensions to more complex, non-linear settings.
Conclusion
The Optimal Flow Matching paper presents a novel approach for learning linear relationships between inputs and outputs in a single training step. By leveraging the power of optimal transport, the method can directly find the optimal mapping between input and output distributions, leading to efficient and accurate learning of straight trajectories.
The authors have demonstrated the effectiveness of their approach on several tasks, including image-to-image translation and density estimation. While the method is currently limited to linear relationships, the underlying mathematical framework suggests that there may be opportunities to extend it to more complex, non-linear settings in the future.
Overall, the Optimal Flow Matching technique represents an intriguing contribution to the field of machine learning, with the potential to improve the efficiency and accuracy of learning in a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimal Flow Matching: Learning Straight Trajectories in Just One Step
Nikita Kornilov, Petr Mokrov, Alexander Gasnikov, Alexander Korotin
Over the several recent years, there has been a boom in development of Flow Matching (FM) methods for generative modeling. One intriguing property pursued by the community is the ability to learn flows with straight trajectories which realize the Optimal Transport (OT) displacements. Straightness is crucial for the fast integration (inference) of the learned flow's paths. Unfortunately, most existing flow straightening methods are based on non-trivial iterative FM procedures which accumulate the error during training or exploit heuristics based on minibatch OT. To address these issues, we develop and theoretically justify the novel Optimal Flow Matching approach which allows recovering the straight OT displacement for the quadratic transport in just one FM step. The main idea of our approach is the employment of vector field for FM which are parameterized by convex functions.
Read more5/28/2024
🏷️
0
Switched Flow Matching: Eliminating Singularities via Switching ODEs
Qunxi Zhu, Wei Lin
Continuous-time generative models, such as Flow Matching (FM), construct probability paths to transport between one distribution and another through the simulation-free learning of the neural ordinary differential equations (ODEs). During inference, however, the learned model often requires multiple neural network evaluations to accurately integrate the flow, resulting in a slow sampling speed. We attribute the reason to the inherent (joint) heterogeneity of source and/or target distributions, namely the singularity problem, which poses challenges for training the neural ODEs effectively. To address this issue, we propose a more general framework, termed Switched FM (SFM), that eliminates singularities via switching ODEs, as opposed to using a uniform ODE in FM. Importantly, we theoretically show that FM cannot transport between two simple distributions due to the existence and uniqueness of initial value problems of ODEs, while these limitations can be well tackled by SFM. From an orthogonal perspective, our framework can seamlessly integrate with the existing advanced techniques, such as minibatch optimal transport, to further enhance the straightness of the flow, yielding a more efficient sampling process with reduced costs. We demonstrate the effectiveness of the newly proposed SFM through several numerical examples.
Read more5/24/2024

0
Flow Map Matching
Nicholas M. Boffi, Michael S. Albergo, Eric Vanden-Eijnden
Generative models based on dynamical transport of measure, such as diffusion models, flow matching models, and stochastic interpolants, learn an ordinary or stochastic differential equation whose trajectories push initial conditions from a known base distribution onto the target. While training is cheap, samples are generated via simulation, which is more expensive than one-step models like GANs. To close this gap, we introduce flow map matching -- an algorithm that learns the two-time flow map of an underlying ordinary differential equation. The approach leads to an efficient few-step generative model whose step count can be chosen a-posteriori to smoothly trade off accuracy for computational expense. Leveraging the stochastic interpolant framework, we introduce losses for both direct training of flow maps and distillation from pre-trained (or otherwise known) velocity fields. Theoretically, we show that our approach unifies many existing few-step generative models, including consistency models, consistency trajectory models, progressive distillation, and neural operator approaches, which can be obtained as particular cases of our formalism. With experiments on CIFAR-10 and ImageNet 32x32, we show that flow map matching leads to high-quality samples with significantly reduced sampling cost compared to diffusion or stochastic interpolant methods.
Read more6/12/2024
0
Flow matching achieves minimax optimal convergence
Kenji Fukumizu, Taiji Suzuki, Noboru Isobe, Kazusato Oko, Masanori Koyama
Flow matching (FM) has gained significant attention as a simulation-free generative model. Unlike diffusion models, which are based on stochastic differential equations, FM employs a simpler approach by solving an ordinary differential equation with an initial condition from a normal distribution, thus streamlining the sample generation process. This paper discusses the convergence properties of FM in terms of the $p$-Wasserstein distance, a measure of distributional discrepancy. We establish that FM can achieve the minmax optimal convergence rate for $1 leq p leq 2$, presenting the first theoretical evidence that FM can reach convergence rates comparable to those of diffusion models. Our analysis extends existing frameworks by examining a broader class of mean and variance functions for the vector fields and identifies specific conditions necessary to attain these optimal rates.
Read more6/3/2024