Optimal Group Fair Classifiers from Linear Post-Processing
2405.04025
0
0

Abstract
We propose a post-processing algorithm for fair classification that mitigates model bias under a unified family of group fairness criteria covering statistical parity, equal opportunity, and equalized odds, applicable to multi-class problems and both attribute-aware and attribute-blind settings. It achieves fairness by re-calibrating the output score of the given base model with a fairness cost -- a linear combination of the (predicted) group memberships. Our algorithm is based on a representation result showing that the optimal fair classifier can be expressed as a linear post-processing of the loss function and the group predictor, derived via using these as sufficient statistics to reformulate the fair classification problem as a linear program. The parameters of the post-processor are estimated by solving the empirical LP. Experiments on benchmark datasets show the efficiency and effectiveness of our algorithm at reducing disparity compared to existing algorithms, including in-processing, especially on larger problems.
Create account to get full access
Overview
- Presents a method for training classifiers that are fair to different demographic groups
- Proposes a linear post-processing step to adjust the outputs of any pre-trained classifier
- Aims to achieve optimal fairness while maintaining high accuracy
Plain English Explanation
This research paper introduces a new approach for building fair machine learning models. The key idea is to start with a standard, high-performing classifier, and then apply a post-processing step to adjust the model's outputs in a way that makes the predictions more fair across different demographic groups.
The researchers show that this linear post-processing approach can achieve an optimal trade-off between fairness and accuracy. By modifying the classifier's outputs rather than retraining the entire model from scratch, they can preserve the model's strong predictive performance while ensuring fairer outcomes for different populations.
This is an important contribution, as achieving fairness in machine learning can be challenging, especially when there are complex trade-offs between accuracy and fairness. The proposed technique provides a principled way to balance these competing objectives.
Technical Explanation
The paper presents a framework for learning "group-fair" classifiers, where the goal is to ensure similar predictive performance across different demographic subgroups. The key innovation is a linear post-processing step that can be applied to the outputs of any pre-trained classifier.
Specifically, the authors formulate the problem as an optimization task to find the optimal linear transformation of the classifier's outputs that minimizes a fairness metric (such as demographic parity or equal opportunity) while preserving high accuracy. They show that this optimization problem has a closed-form solution, making the approach computationally efficient.
The experiments demonstrate that this linear post-processing approach can outperform other state-of-the-art fairness-aware training methods in terms of the fairness-accuracy trade-off. The method is also flexible, as it can be applied to a wide range of base classifiers and fairness metrics.
Critical Analysis
A strength of this research is the principled optimization-based approach to balancing fairness and accuracy. By decoupling the fairness concerns from the base classifier training, the method is broadly applicable and can leverage any high-performing model.
However, a potential limitation is that the linear post-processing may not be able to fully correct for complex, non-linear biases in the base classifier's outputs. In some cases, more expressive, non-linear transformations may be required to achieve the desired level of fairness.
Additionally, the paper focuses on group-level notions of fairness, such as demographic parity and equal opportunity. While these are important considerations, the authors acknowledge that individual-level fairness is also a crucial aspect that is not directly addressed by their approach.
Further research could explore hybrid techniques that combine this linear post-processing with more sophisticated, non-linear fairness-aware training methods, or investigate ways to incorporate individual-level fairness considerations into the optimization framework.
Conclusion
This paper presents a novel approach for training machine learning classifiers that are fair to different demographic groups. By applying a linear post-processing step to the outputs of any pre-trained model, the method can achieve an optimal trade-off between fairness and accuracy.
The flexibility and computational efficiency of this approach make it a promising technique for building fairer AI systems in a wide range of real-world applications. As machine learning models become more widely deployed, techniques like this will be crucial for ensuring fair and equitable outcomes for all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Differentially Private Post-Processing for Fair Regression
Ruicheng Xian, Qiaobo Li, Gautam Kamath, Han Zhao
0
0
This paper describes a differentially private post-processing algorithm for learning fair regressors satisfying statistical parity, addressing privacy concerns of machine learning models trained on sensitive data, as well as fairness concerns of their potential to propagate historical biases. Our algorithm can be applied to post-process any given regressor to improve fairness by remapping its outputs. It consists of three steps: first, the output distributions are estimated privately via histogram density estimation and the Laplace mechanism, then their Wasserstein barycenter is computed, and the optimal transports to the barycenter are used for post-processing to satisfy fairness. We analyze the sample complexity of our algorithm and provide fairness guarantee, revealing a trade-off between the statistical bias and variance induced from the choice of the number of bins in the histogram, in which using less bins always favors fairness at the expense of error.
5/8/2024

FRAPPE: A Group Fairness Framework for Post-Processing Everything
Alexandru Tifrea, Preethi Lahoti, Ben Packer, Yoni Halpern, Ahmad Beirami, Flavien Prost
0
0
Despite achieving promising fairness-error trade-offs, in-processing mitigation techniques for group fairness cannot be employed in numerous practical applications with limited computation resources or no access to the training pipeline of the prediction model. In these situations, post-processing is a viable alternative. However, current methods are tailored to specific problem settings and fairness definitions and hence, are not as broadly applicable as in-processing. In this work, we propose a framework that turns any regularized in-processing method into a post-processing approach. This procedure prescribes a way to obtain post-processing techniques for a much broader range of problem settings than the prior post-processing literature. We show theoretically and through extensive experiments that our framework preserves the good fairness-error trade-offs achieved with in-processing and can improve over the effectiveness of prior post-processing methods. Finally, we demonstrate several advantages of a modular mitigation strategy that disentangles the training of the prediction model from the fairness mitigation, including better performance on tasks with partial group labels.
6/21/2024
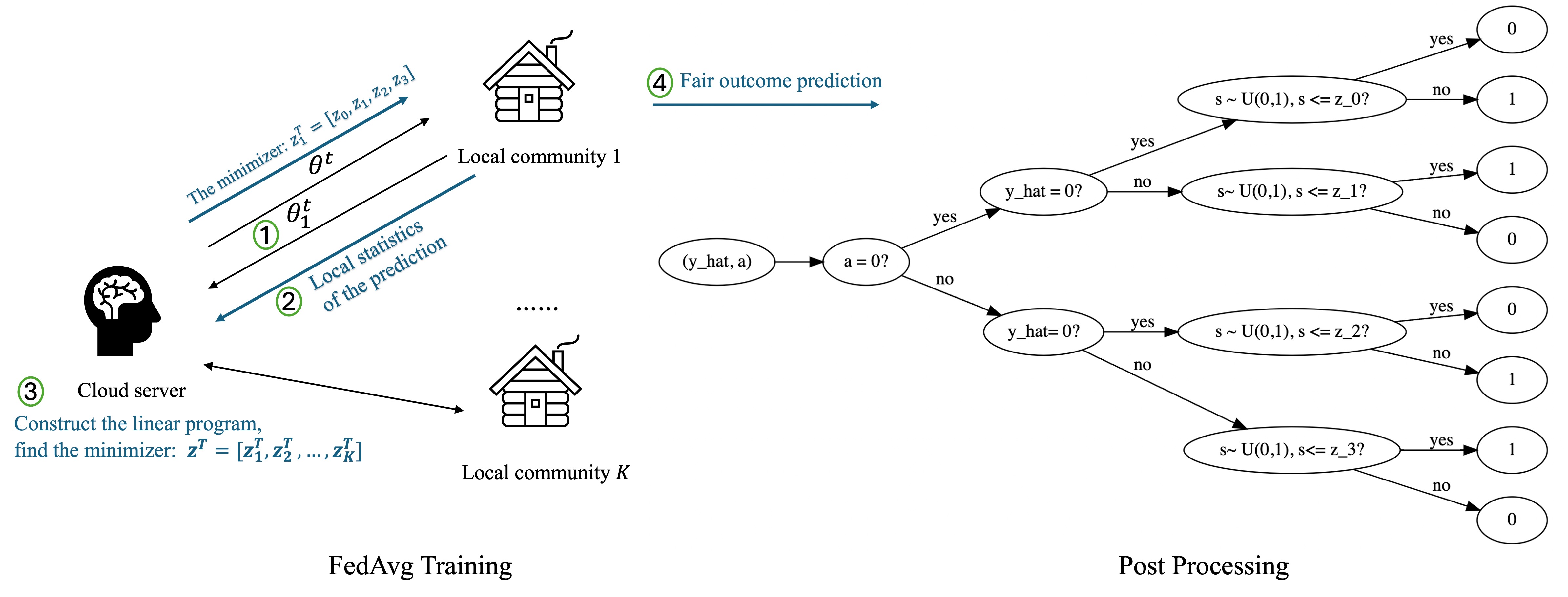
Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing
Yuying Duan, Yijun Tian, Nitesh Chawla, Michael Lemmon
0
0
Federated Learning (FL) is a distributed machine learning framework in which a set of local communities collaboratively learn a shared global model while retaining all training data locally within each community. Two notions of fairness have recently emerged as important issues for federated learning: group fairness and community fairness. Group fairness requires that a model's decisions do not favor any particular group based on a set of legally protected attributes such as race or gender. Community fairness requires that global models exhibit similar levels of performance (accuracy) across all collaborating communities. Both fairness concepts can coexist within an FL framework, but the existing literature has focused on either one concept or the other. This paper proposes and analyzes a post-processing fair federated learning (FFL) framework called post-FFL. Post-FFL uses a linear program to simultaneously enforce group and community fairness while maximizing the utility of the global model. Because Post-FFL is a post-processing approach, it can be used with existing FL training pipelines whose convergence properties are well understood. This paper uses post-FFL on real-world datasets to mimic how hospital networks, for example, use federated learning to deliver community health care. Theoretical results bound the accuracy lost when post-FFL enforces both notion of fairness. Experimental results illustrate that post-FFL simultaneously improves both group and community fairness in FL. Moreover, post-FFL outperforms the existing in-processing fair federated learning in terms of improving both notions of fairness, communication efficiency and computation cost.
5/29/2024
🤖
Equalised Odds is not Equal Individual Odds: Post-processing for Group and Individual Fairness
Edward A. Small, Kacper Sokol, Daniel Manning, Flora D. Salim, Jeffrey Chan
0
0
Group fairness is achieved by equalising prediction distributions between protected sub-populations; individual fairness requires treating similar individuals alike. These two objectives, however, are incompatible when a scoring model is calibrated through discontinuous probability functions, where individuals can be randomly assigned an outcome determined by a fixed probability. This procedure may provide two similar individuals from the same protected group with classification odds that are disparately different -- a clear violation of individual fairness. Assigning unique odds to each protected sub-population may also prevent members of one sub-population from ever receiving equal chances of a positive outcome to another, which we argue is another type of unfairness called individual odds. We reconcile all this by constructing continuous probability functions between group thresholds that are constrained by their Lipschitz constant. Our solution preserves the model's predictive power, individual fairness and robustness while ensuring group fairness.
4/22/2024