Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing

0
Sign in to get full access
Overview
- Introduces a post-processing approach to achieve group and community fairness in federated learning
- Aims to address fairness issues that can arise in federated learning due to data heterogeneity and differences across client devices
- Proposes methods to adjust the final model's predictions to ensure fairness for different demographic groups and communities
Plain English Explanation
The paper presents a new approach to making federated learning more fair and equitable. Federated learning is a way of training machine learning models by combining data from many different devices, rather than centralizing all the data in one place. This can be helpful for privacy and efficiency, but it can also lead to unfairness if some groups are underrepresented in the training data.
The researchers' solution is to apply a post-processing step after the federated learning process is complete. This allows them to adjust the model's predictions to ensure that the outcomes are fair for different demographic groups and communities, even if the original training data was imbalanced. By doing this, they can help make sure the final model doesn't discriminate or perform poorly for certain populations.
The key ideas are to define fairness metrics that capture group-level and community-level disparities, and then use optimization techniques to "correct" the model's outputs and make them more equitable. This builds on previous work on fair machine learning, but applies it specifically to the federated learning setting.
Technical Explanation
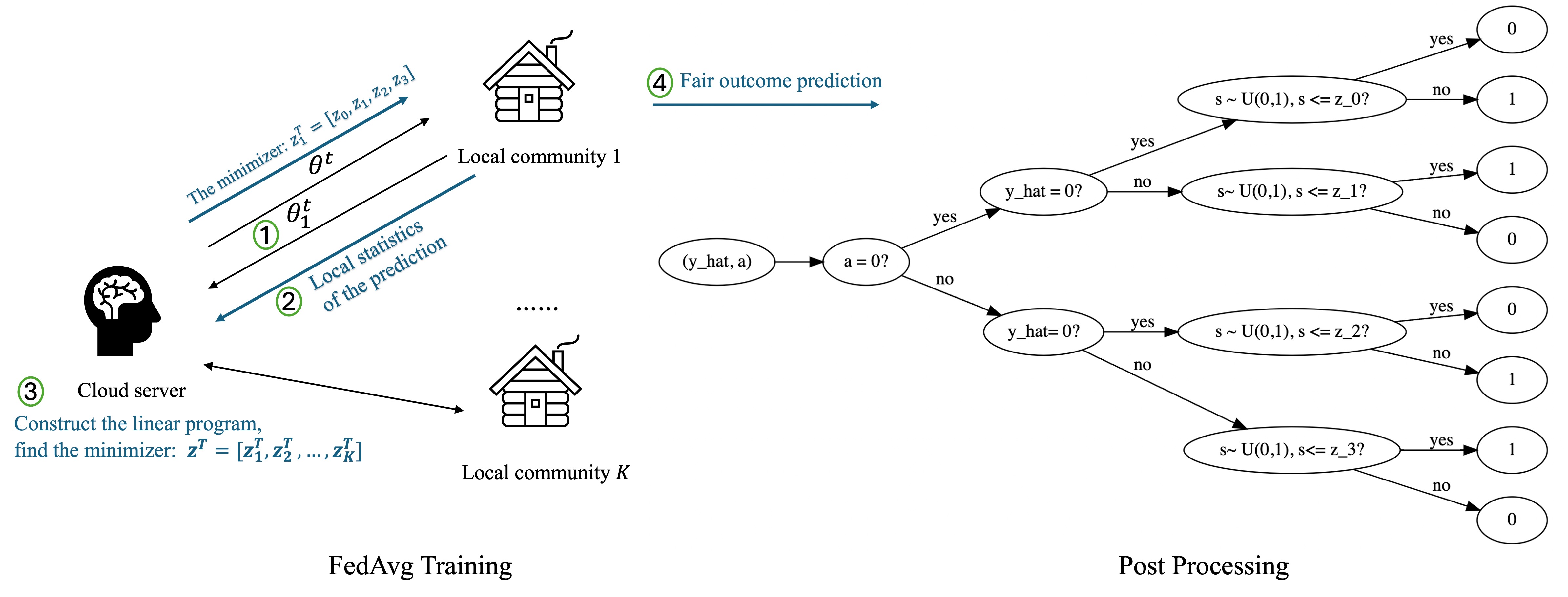
The paper proposes a post-processing approach to achieve group and community fairness in federated learning. The authors first define fairness metrics to capture group-level disparities (e.g., performance gaps between demographic groups) and community-level disparities (e.g., performance differences for geographically-defined communities).
They then formulate an optimization problem to adjust the final federated learning model's predictions and make them more equitable with respect to these fairness metrics. This involves solving a constrained optimization problem to find the optimal "correction" to apply to the model's outputs.
The key technical contributions include:
- Formalizing group and community fairness objectives for federated learning
- Developing a post-processing algorithm to adjust model predictions and satisfy these fairness constraints
- Proving theoretical guarantees about the algorithm's effectiveness
- Evaluating the approach on several real-world federated learning benchmarks, demonstrating improvements in fairness without sacrificing overall model performance
The post-processing nature of this approach means it can be applied as a "plug-in" to improve the fairness of any federated learning system, without requiring changes to the core training process. This makes it a flexible and practical solution for deploying fair federated learning in real-world applications.
Critical Analysis
The paper makes a compelling case for the importance of fairness in federated learning, and proposes a novel post-processing solution to address it. The authors provide thoughtful definitions of group and community fairness, and develop a rigorous optimization-based method to enforce these fairness criteria.
One potential limitation is that the post-processing approach relies on having access to demographic and community information for each client device participating in the federated learning process. In some real-world scenarios, this information may not be readily available or easy to obtain.
Additionally, the paper focuses on fairness in the context of the final model's predictions, but does not address potential unfairness that could arise during the iterative federated learning process itself. There may be value in exploring fairness-aware federated learning algorithms that tackle these issues at the training stage, rather than just in post-processing.
Overall, however, this work represents an important step forward in making federated learning more equitable and inclusive. The ideas presented here could be further built upon and extended in future research, for example by exploring federated learning approaches that inherently promote fairness or incorporating structural information to enhance fairness.
Conclusion
This paper introduces a post-processing approach to achieve group and community fairness in federated learning. By defining appropriate fairness metrics and formulating an optimization problem to adjust the final model's predictions, the authors demonstrate how to improve the equity of federated learning systems without sacrificing overall performance.
This work is an important contribution to the growing body of research on fair machine learning, with specific applications to the federated learning domain. As federated learning continues to gain traction for privacy-preserving AI, ensuring fairness and inclusivity will be critical to responsible deployment. The ideas presented in this paper provide a promising step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing
Yuying Duan, Yijun Tian, Nitesh Chawla, Michael Lemmon
Federated Learning (FL) is a distributed machine learning framework in which a set of local communities collaboratively learn a shared global model while retaining all training data locally within each community. Two notions of fairness have recently emerged as important issues for federated learning: group fairness and community fairness. Group fairness requires that a model's decisions do not favor any particular group based on a set of legally protected attributes such as race or gender. Community fairness requires that global models exhibit similar levels of performance (accuracy) across all collaborating communities. Both fairness concepts can coexist within an FL framework, but the existing literature has focused on either one concept or the other. This paper proposes and analyzes a post-processing fair federated learning (FFL) framework called post-FFL. Post-FFL uses a linear program to simultaneously enforce group and community fairness while maximizing the utility of the global model. Because Post-FFL is a post-processing approach, it can be used with existing FL training pipelines whose convergence properties are well understood. This paper uses post-FFL on real-world datasets to mimic how hospital networks, for example, use federated learning to deliver community health care. Theoretical results bound the accuracy lost when post-FFL enforces both notion of fairness. Experimental results illustrate that post-FFL simultaneously improves both group and community fairness in FL. Moreover, post-FFL outperforms the existing in-processing fair federated learning in terms of improving both notions of fairness, communication efficiency and computation cost.
Read more5/29/2024

0
Federated Fairness Analytics: Quantifying Fairness in Federated Learning
Oscar Dilley, Juan Marcelo Parra-Ullauri, Rasheed Hussain, Dimitra Simeonidou
Federated Learning (FL) is a privacy-enhancing technology for distributed ML. By training models locally and aggregating updates - a federation learns together, while bypassing centralised data collection. FL is increasingly popular in healthcare, finance and personal computing. However, it inherits fairness challenges from classical ML and introduces new ones, resulting from differences in data quality, client participation, communication constraints, aggregation methods and underlying hardware. Fairness remains an unresolved issue in FL and the community has identified an absence of succinct definitions and metrics to quantify fairness; to address this, we propose Federated Fairness Analytics - a methodology for measuring fairness. Our definition of fairness comprises four notions with novel, corresponding metrics. They are symptomatically defined and leverage techniques originating from XAI, cooperative game-theory and networking engineering. We tested a range of experimental settings, varying the FL approach, ML task and data settings. The results show that statistical heterogeneity and client participation affect fairness and fairness conscious approaches such as Ditto and q-FedAvg marginally improve fairness-performance trade-offs. Using our techniques, FL practitioners can uncover previously unobtainable insights into their system's fairness, at differing levels of granularity in order to address fairness challenges in FL. We have open-sourced our work at: https://github.com/oscardilley/federated-fairness.
Read more8/16/2024

0
Enhancing Group Fairness in Federated Learning through Personalization
Yifan Yang, Ali Payani, Parinaz Naghizadeh
Personalized Federated Learning (FL) algorithms collaboratively train customized models for each client, enhancing the accuracy of the learned models on the client's local data (e.g., by clustering similar clients, or by fine-tuning models locally). In this paper, we investigate the impact of such personalization techniques on the group fairness of the learned models, and show that personalization can also lead to improved (local) fairness as an unintended benefit. We begin by illustrating these benefits of personalization through numerical experiments comparing two classes of personalized FL algorithms (clustering and fine-tuning) against a baseline FedAvg algorithm, elaborating on the reasons behind improved fairness using personalized FL, and then providing analytical support. Motivated by these, we further propose a new, Fairness-aware Federated Clustering Algorithm, Fair-FCA, in which clients can be clustered to obtain a (tuneable) fairness-accuracy tradeoff. Through numerical experiments, we demonstrate the ability of Fair-FCA to strike a balance between accuracy and fairness at the client level.
Read more7/30/2024

0
Fair Concurrent Training of Multiple Models in Federated Learning
Marie Siew, Haoran Zhang, Jong-Ik Park, Yuezhou Liu, Yichen Ruan, Lili Su, Stratis Ioannidis, Edmund Yeh, Carlee Joe-Wong
Federated learning (FL) enables collaborative learning across multiple clients. In most FL work, all clients train a single learning task. However, the recent proliferation of FL applications may increasingly require multiple FL tasks to be trained simultaneously, sharing clients' computing and communication resources, which we call Multiple-Model Federated Learning (MMFL). Current MMFL algorithms use naive average-based client-task allocation schemes that can lead to unfair performance when FL tasks have heterogeneous difficulty levels, e.g., tasks with larger models may need more rounds and data to train. Just as naively allocating resources to generic computing jobs with heterogeneous resource needs can lead to unfair outcomes, naive allocation of clients to FL tasks can lead to unfairness, with some tasks having excessively long training times, or lower converged accuracies. Furthermore, in the FL setting, since clients are typically not paid for their training effort, we face a further challenge that some clients may not even be willing to train some tasks, e.g., due to high computational costs, which may exacerbate unfairness in training outcomes across tasks. We address both challenges by firstly designing FedFairMMFL, a difficulty-aware algorithm that dynamically allocates clients to tasks in each training round. We provide guarantees on airness and FedFairMMFL's convergence rate. We then propose a novel auction design that incentivizes clients to train multiple tasks, so as to fairly distribute clients' training efforts across the tasks. We show how our fairness-based learning and incentive mechanisms impact training convergence and finally evaluate our algorithm with multiple sets of learning tasks on real world datasets.
Read more4/23/2024