The Optimality of (Accelerated) SGD for High-Dimensional Quadratic Optimization

0

Sign in to get full access
Overview
- The paper discusses the optimality of (Accelerated) Stochastic Gradient Descent (SGD) for high-dimensional quadratic optimization.
- It analyzes the convergence rates of SGD and Accelerated SGD (ASGD) for solving quadratic optimization problems in high dimensions.
- The paper provides theoretical guarantees on the convergence rates of these algorithms and shows that they are optimal in certain regimes.
Plain English Explanation
The paper looks at a common machine learning problem called quadratic optimization. This involves finding the best set of parameters for a machine learning model that minimizes a quadratic cost function.
One popular way to solve this is to use Stochastic Gradient Descent (SGD) and its accelerated version, Accelerated SGD (ASGD). These algorithms iteratively update the model parameters in the direction of the negative gradient, which points towards the minimum of the cost function.
The key contribution of this paper is to show that SGD and ASGD are optimal for solving high-dimensional quadratic optimization problems. This means they achieve the best possible convergence rates that any algorithm can achieve for this type of problem.
The authors provide theoretical guarantees on the convergence rates of these algorithms. They show that in certain settings, SGD and ASGD converge at the fastest possible rates, meaning they are the most efficient algorithms for these problems.
This is an important result because quadratic optimization is a fundamental building block of many machine learning methods. Knowing that SGD and ASGD are optimal algorithms for this task can help machine learning practitioners select the best optimization techniques for their models.
Technical Explanation
The paper analyzes the convergence rates of Stochastic Gradient Descent (SGD) and Accelerated Stochastic Gradient Descent (ASGD) for solving high-dimensional quadratic optimization problems.
The authors consider the problem of minimizing a quadratic cost function f(x) = (1/2)x^T A x - b^T x, where A is a positive semi-definite matrix and b is a vector. They show that for this problem:
-
SGD: Under certain assumptions, SGD achieves an optimal convergence rate of
O(d/T), wheredis the problem dimension andTis the number of iterations. -
ASGD: The authors also analyze an accelerated variant of SGD, known as ASGD. They show that ASGD achieves an optimal convergence rate of
O(√(d/T)), which is better than the rate for SGD.
The key technical contributions are:
- Establishing lower bounds on the convergence rates of any algorithm for high-dimensional quadratic optimization. These lower bounds show the fastest possible rates that any algorithm can achieve.
- Proving that SGD and ASGD match these lower bounds, meaning they are optimal algorithms for this problem class.
- Providing explicit convergence rate bounds for SGD and ASGD in terms of the problem dimension
dand the number of iterationsT.
These results demonstrate the optimality of (Accelerated) SGD for high-dimensional quadratic optimization, suggesting they are the algorithms of choice for solving such problems in practice.
Critical Analysis
The paper provides a strong theoretical analysis of the convergence rates of SGD and ASGD for high-dimensional quadratic optimization problems. The authors carefully establish lower bounds on the achievable convergence rates and then show that SGD and ASGD match these lower bounds, proving their optimality.
One potential limitation of the work is that it focuses solely on quadratic optimization problems. While quadratic functions are important in many machine learning applications, real-world problems often involve more complex, non-convex objective functions. It would be interesting to see if similar optimality results could be obtained for a broader class of optimization problems.
Additionally, the analysis assumes the problem parameters (the matrix A and vector b) are known. In practice, these quantities may need to be estimated from data, which could affect the convergence rates. Incorporating such estimation errors into the analysis could provide additional insights.
Finally, the paper does not discuss the practical considerations of implementing SGD and ASGD, such as the choice of step sizes, mini-batch sizes, and other hyperparameters. While the theoretical results are compelling, understanding how these algorithms perform in realistic settings would be valuable for practitioners.
Overall, this paper makes an important contribution by establishing the optimality of (Accelerated) SGD for high-dimensional quadratic optimization. The results provide a strong theoretical foundation for the use of these algorithms in machine learning and optimization tasks.
Conclusion
This paper analyzes the convergence rates of Stochastic Gradient Descent (SGD) and Accelerated Stochastic Gradient Descent (ASGD) for high-dimensional quadratic optimization problems. The authors prove that these algorithms achieve optimal convergence rates, meaning they are the most efficient algorithms for solving this class of problems.
The key findings are:
- SGD: Under certain assumptions, SGD achieves an optimal convergence rate of
O(d/T), wheredis the problem dimension andTis the number of iterations. - ASGD: The accelerated variant, ASGD, achieves an optimal convergence rate of
O(√(d/T)), which is better than the rate for SGD.
These results demonstrate the optimality of (Accelerated) SGD for high-dimensional quadratic optimization, suggesting they are the algorithms of choice for solving such problems in practice. The theoretical guarantees provided in this paper can help guide the selection of optimization techniques for machine learning models and other optimization tasks involving quadratic objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Optimality of (Accelerated) SGD for High-Dimensional Quadratic Optimization
Haihan Zhang, Yuanshi Liu, Qianwen Chen, Cong Fang
Stochastic gradient descent (SGD) is a widely used algorithm in machine learning, particularly for neural network training. Recent studies on SGD for canonical quadratic optimization or linear regression show it attains well generalization under suitable high-dimensional settings. However, a fundamental question -- for what kinds of high-dimensional learning problems SGD and its accelerated variants can achieve optimality has yet to be well studied. This paper investigates SGD with two essential components in practice: exponentially decaying step size schedule and momentum. We establish the convergence upper bound for momentum accelerated SGD (ASGD) and propose concrete classes of learning problems under which SGD or ASGD achieves min-max optimal convergence rates. The characterization of the target function is based on standard power-law decays in (functional) linear regression. Our results unveil new insights for understanding the learning bias of SGD: (i) SGD is efficient in learning ``dense'' features where the corresponding weights are subject to an infinity norm constraint; (ii) SGD is efficient for easy problem without suffering from the saturation effect; (iii) momentum can accelerate the convergence rate by order when the learning problem is relatively hard. To our knowledge, this is the first work to clearly identify the optimal boundary of SGD versus ASGD for the problem under mild settings.
Read more9/17/2024
0
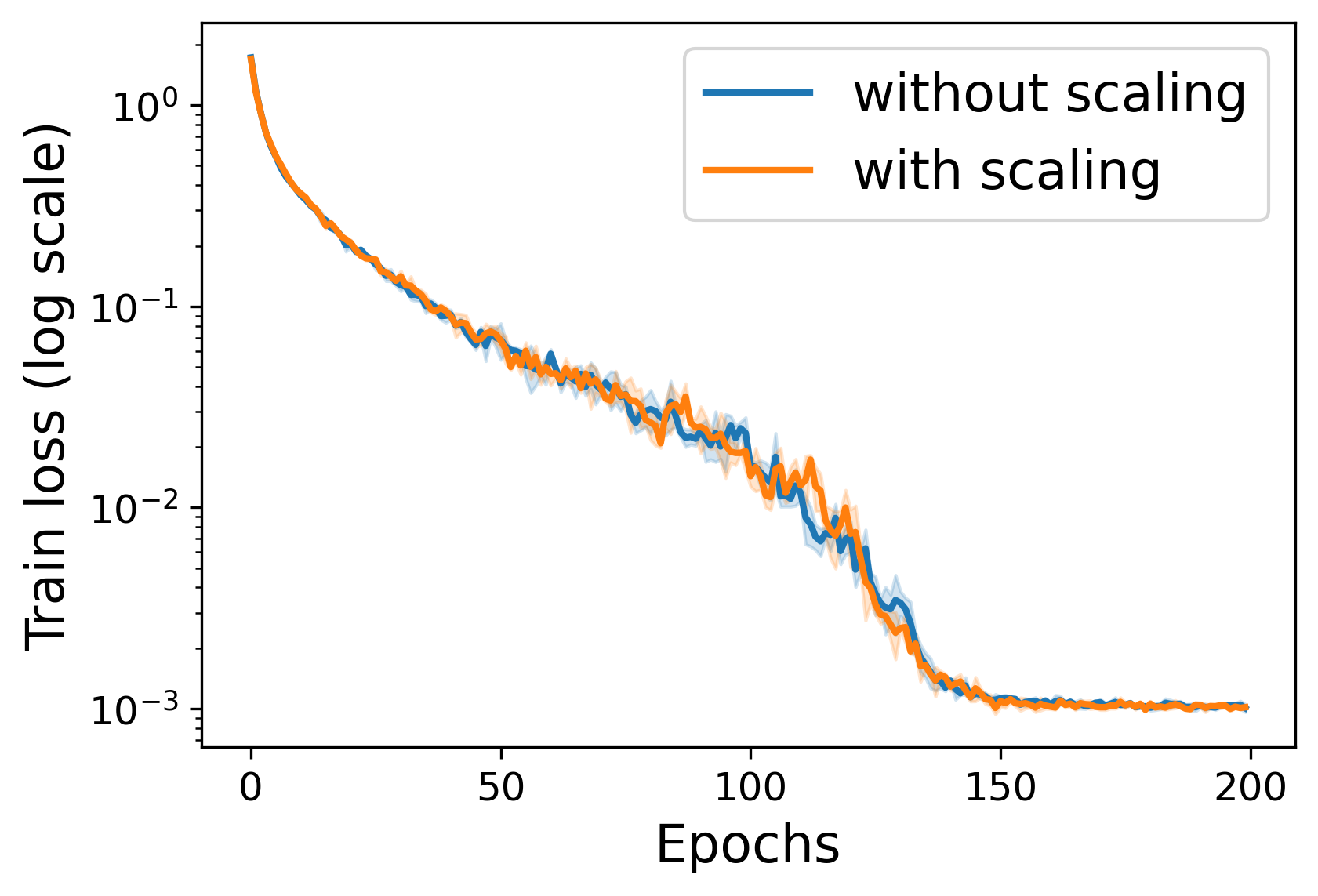
Random Scaling and Momentum for Non-smooth Non-convex Optimization
Qinzi Zhang, Ashok Cutkosky
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
Read more5/17/2024
⛏️
0
Convergence rates of stochastic gradient method with independent sequences of step-size and momentum weight
Wen-Liang Hwang
In large-scale learning algorithms, the momentum term is usually included in the stochastic sub-gradient method to improve the learning speed because it can navigate ravines efficiently to reach a local minimum. However, step-size and momentum weight hyper-parameters must be appropriately tuned to optimize convergence. We thus analyze the convergence rate using stochastic programming with Polyak's acceleration of two commonly used step-size learning rates: ``diminishing-to-zero and ``constant-and-drop (where the sequence is divided into stages and a constant step-size is applied at each stage) under strongly convex functions over a compact convex set with bounded sub-gradients. For the former, we show that the convergence rate can be written as a product of exponential in step-size and polynomial in momentum weight. Our analysis justifies the convergence of using the default momentum weight setting and the diminishing-to-zero step-size sequence in large-scale machine learning software. For the latter, we present the condition for the momentum weight sequence to converge at each stage.
Read more8/7/2024
0
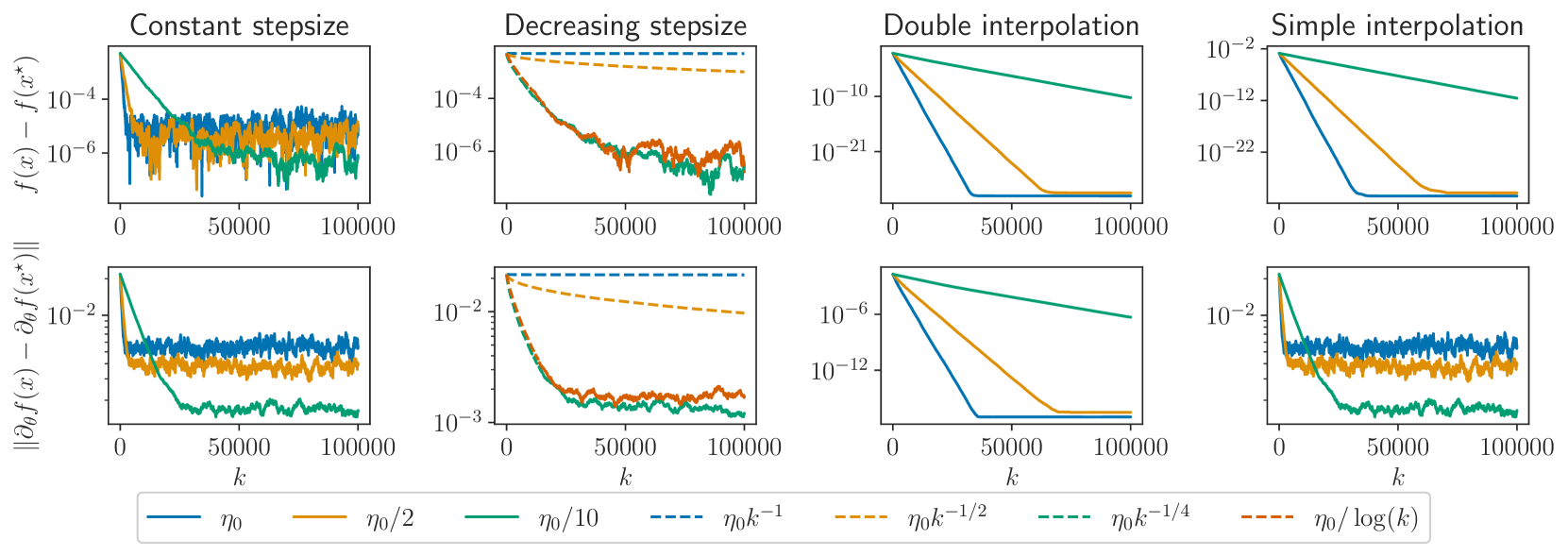
Derivatives of Stochastic Gradient Descent
Franck Iutzeler, Edouard Pauwels, Samuel Vaiter
We consider stochastic optimization problems where the objective depends on some parameter, as commonly found in hyperparameter optimization for instance. We investigate the behavior of the derivatives of the iterates of Stochastic Gradient Descent (SGD) with respect to that parameter and show that they are driven by an inexact SGD recursion on a different objective function, perturbed by the convergence of the original SGD. This enables us to establish that the derivatives of SGD converge to the derivative of the solution mapping in terms of mean squared error whenever the objective is strongly convex. Specifically, we demonstrate that with constant step-sizes, these derivatives stabilize within a noise ball centered at the solution derivative, and that with vanishing step-sizes they exhibit $O(log(k)^2 / k)$ convergence rates. Additionally, we prove exponential convergence in the interpolation regime. Our theoretical findings are illustrated by numerical experiments on synthetic tasks.
Read more5/28/2024