Language Model Cascades: Token-level uncertainty and beyond
2404.10136
0
0
Abstract
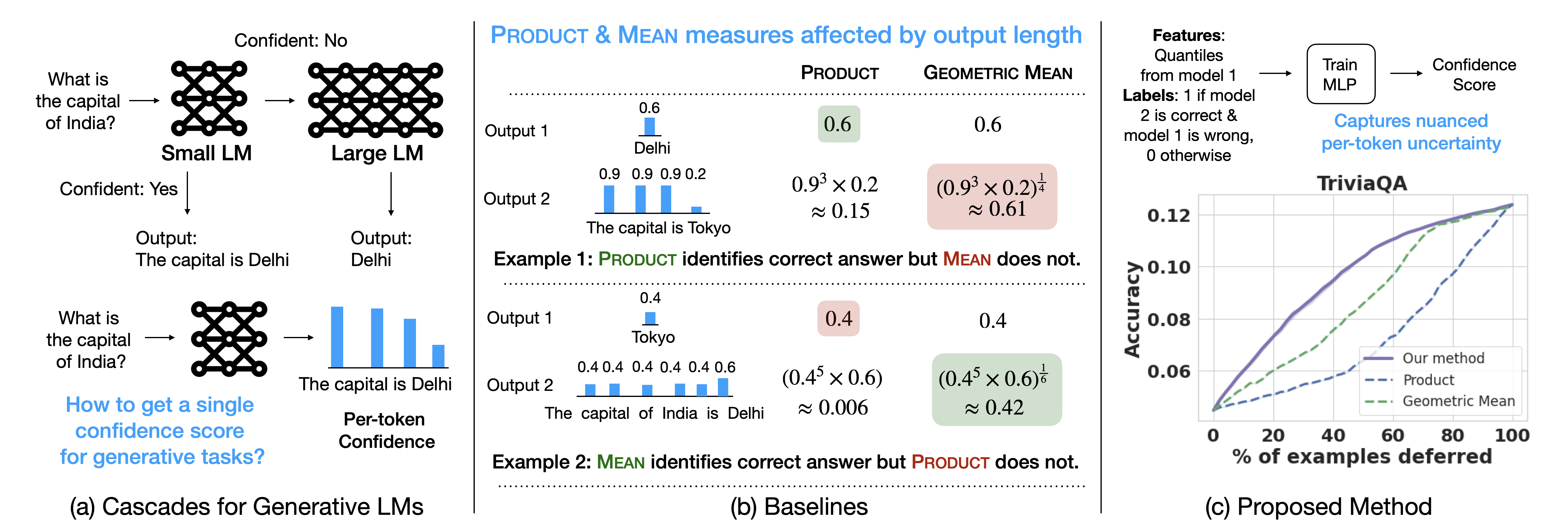
Recent advances in language models (LMs) have led to significant improvements in quality on complex NLP tasks, but at the expense of increased inference costs. Cascading offers a simple strategy to achieve more favorable cost-quality tradeoffs: here, a small model is invoked for most easy instances, while a few hard instances are deferred to the large model. While the principles underpinning cascading are well-studied for classification tasks - with deferral based on predicted class uncertainty favored theoretically and practically - a similar understanding is lacking for generative LM tasks. In this work, we initiate a systematic study of deferral rules for LM cascades. We begin by examining the natural extension of predicted class uncertainty to generative LM tasks, namely, the predicted sequence uncertainty. We show that this measure suffers from the length bias problem, either over- or under-emphasizing outputs based on their lengths. This is because LMs produce a sequence of uncertainty values, one for each output token; and moreover, the number of output tokens is variable across examples. To mitigate this issue, we propose to exploit the richer token-level uncertainty information implicit in generative LMs. We argue that naive predicted sequence uncertainty corresponds to a simple aggregation of these uncertainties. By contrast, we show that incorporating token-level uncertainty through learned post-hoc deferral rules can significantly outperform such simple aggregation strategies, via experiments on a range of natural language benchmarks with FLAN-T5 models. We further show that incorporating embeddings from the smaller model and intermediate layers of the larger model can give an additional boost in the overall cost-quality tradeoff.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of token-level uncertainty in language models, and how it can be leveraged to improve their performance.
- The authors propose a "Language Model Cascade" approach, which combines multiple language models to handle different levels of uncertainty.
- The research aims to address the challenges of uncertainty quantification in large language models and the importance of uncertainty-aware language models for improved decision-making.
Plain English Explanation
Language models are powerful artificial intelligence systems that can generate human-like text. However, these models often struggle with uncertainty - they may not always be confident in the text they produce. This paper explores a new approach to address this issue.
The researchers propose a "Language Model Cascade," which combines multiple language models to handle different levels of uncertainty. The idea is that the system can switch between these models depending on how confident it is in the text it's generating.
For example, when the system is highly confident, it can use a powerful language model to generate the text. But when it's less certain, it can switch to a more conservative model that is better at expressing uncertainty. This allows the system to produce text that is both fluent and transparent about its uncertainty.
The authors believe this approach can lead to better decision-making by language models, as users can better understand the model's confidence in its outputs. It also builds on previous research on uncertainty quantification and uncertainty-aware language models.
Technical Explanation
The paper presents a "Language Model Cascade" approach to leverage token-level uncertainty in language models. The key idea is to combine multiple language models, each specialized for different levels of uncertainty.
The system first uses a powerful "base" language model to generate text. However, it also calculates a token-level uncertainty score for the generated text. If the uncertainty is below a certain threshold, the system uses the base model's output. But if the uncertainty is higher, the system switches to a more conservative "fallback" language model that is better at expressing uncertainty.
The authors explore different ways of calculating the token-level uncertainty, such as using the model's output probability distribution or incorporating external uncertainty estimation methods like Bayesian neural networks.
They evaluate their approach on various language generation tasks and find that the Language Model Cascade outperforms using a single language model, especially in situations where uncertainty is high. The cascade model is able to produce text that is both fluent and transparent about its confidence.
Critical Analysis
The authors acknowledge several limitations and areas for future work. For example, the performance of the cascade model is dependent on the quality and suitability of the fallback language model, which may be challenging to obtain or train.
Additionally, the paper does not address the potential computational overhead of running multiple language models in parallel. This could be a concern, especially for real-time applications that require fast response times.
The authors also note that their uncertainty estimation methods may not fully capture the true uncertainty of the language models, as they rely on proxy measures rather than a more rigorous uncertainty quantification approach.
Overall, the Language Model Cascade is a promising approach to addressing the challenges of uncertainty in language models. However, further research is needed to fully understand its limitations, optimize its performance, and develop more robust uncertainty estimation techniques.
Conclusion
This paper presents a novel "Language Model Cascade" approach to leveraging token-level uncertainty in language models. By combining multiple language models, the system can dynamically switch between them based on the level of uncertainty, producing text that is both fluent and transparent about its confidence.
The research builds on previous work in uncertainty-aware language models and uncertainty quantification, with the ultimate goal of improving decision-making by language models. While the approach has some limitations, it represents an important step forward in addressing the challenges of uncertainty in large language models.
Related Papers
💬
Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection
Guillem Ram'irez, Alexandra Birch, Ivan Titov
0
0
Researchers and practitioners operating on a limited budget face the cost-performance trade-off dilemma. The challenging decision often centers on whether to use a large LLM with better performance or a smaller one with reduced costs. This has motivated recent research in the optimisation of LLM calls. Either a cascading strategy is used, where a smaller LLM or both are called sequentially, or a routing strategy is used, where only one model is ever called. Both scenarios are dependent on a decision criterion which is typically implemented by an extra neural model. In this work, we propose a simpler solution; we use only the uncertainty of the generations of the small LLM as the decision criterion. We compare our approach with both cascading and routing strategies using three different pairs of pre-trained small and large LLMs, on nine different tasks and against approaches that require an additional neural model. Our experiments reveal this simple solution optimally balances cost and performance, outperforming existing methods on 25 out of 27 experimental setups.
5/6/2024

Can LLMs get help from other LLMs without revealing private information?
Florian Hartmann, Duc-Hieu Tran, Peter Kairouz, Victor Cu{a}rbune, Blaise Aguera y Arcas
0
0
Cascades are a common type of machine learning systems in which a large, remote model can be queried if a local model is not able to accurately label a user's data by itself. Serving stacks for large language models (LLMs) increasingly use cascades due to their ability to preserve task performance while dramatically reducing inference costs. However, applying cascade systems in situations where the local model has access to sensitive data constitutes a significant privacy risk for users since such data could be forwarded to the remote model. In this work, we show the feasibility of applying cascade systems in such setups by equipping the local model with privacy-preserving techniques that reduce the risk of leaking private information when querying the remote model. To quantify information leakage in such setups, we introduce two privacy measures. We then propose a system that leverages the recently introduced social learning paradigm in which LLMs collaboratively learn from each other by exchanging natural language. Using this paradigm, we demonstrate on several datasets that our methods minimize the privacy loss while at the same time improving task performance compared to a non-cascade baseline.
4/3/2024
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Zhenyu Qian, Yiming Qian, Yuting Song, Fei Gao, Hai Jin, Chen Yu, Xia Xie
0
0
Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
4/15/2024

Overconfidence is Key: Verbalized Uncertainty Evaluation in Large Language and Vision-Language Models
Tobias Groot, Matias Valdenegro-Toro
0
0
Language and Vision-Language Models (LLMs/VLMs) have revolutionized the field of AI by their ability to generate human-like text and understand images, but ensuring their reliability is crucial. This paper aims to evaluate the ability of LLMs (GPT4, GPT-3.5, LLaMA2, and PaLM 2) and VLMs (GPT4V and Gemini Pro Vision) to estimate their verbalized uncertainty via prompting. We propose the new Japanese Uncertain Scenes (JUS) dataset, aimed at testing VLM capabilities via difficult queries and object counting, and the Net Calibration Error (NCE) to measure direction of miscalibration. Results show that both LLMs and VLMs have a high calibration error and are overconfident most of the time, indicating a poor capability for uncertainty estimation. Additionally we develop prompts for regression tasks, and we show that VLMs have poor calibration when producing mean/standard deviation and 95% confidence intervals.
5/7/2024