Optimization of DNN-based speaker verification model through efficient quantization technique

0
🛠️
Sign in to get full access
Overview
- Deep Neural Networks (DNNs) are widely used in various fields, including speech verification, but they often require high computational resources and memory.
- Quantization, a technique to reduce the precision of model parameters, can help address these challenges by reducing computational and memory costs.
- This research proposes an optimization framework for quantizing a speaker verification model, aiming to minimize performance degradation while significantly reducing the model size.
Plain English Explanation
Deep learning models, such as those used for speech verification, have become incredibly powerful in recent years. However, these models often require a lot of computing power and memory to run, which can be a problem when using them on mobile devices or other resource-constrained systems.
To address this issue, the researchers in this study have developed a new way to [object Object] their speaker verification model. Quantization involves reducing the precision of the model's internal parameters, which can significantly reduce the model's size and computational requirements.
The key innovation in this work is the optimization framework they used to perform the quantization. By carefully analyzing how the model's performance changes as each layer is quantized, they were able to find a way to minimize the performance degradation while still achieving a substantial reduction in the model's size. In fact, they were able to reduce the model size by half, with only a 0.07% increase in the [object Object].
This is an important breakthrough, as it allows for more efficient deployment of high-quality speech verification models on resource-constrained devices, such as smartphones or embedded systems. By [object Object] without significantly impacting its accuracy, the researchers have made it possible to use these advanced models in a wider range of applications.
Technical Explanation
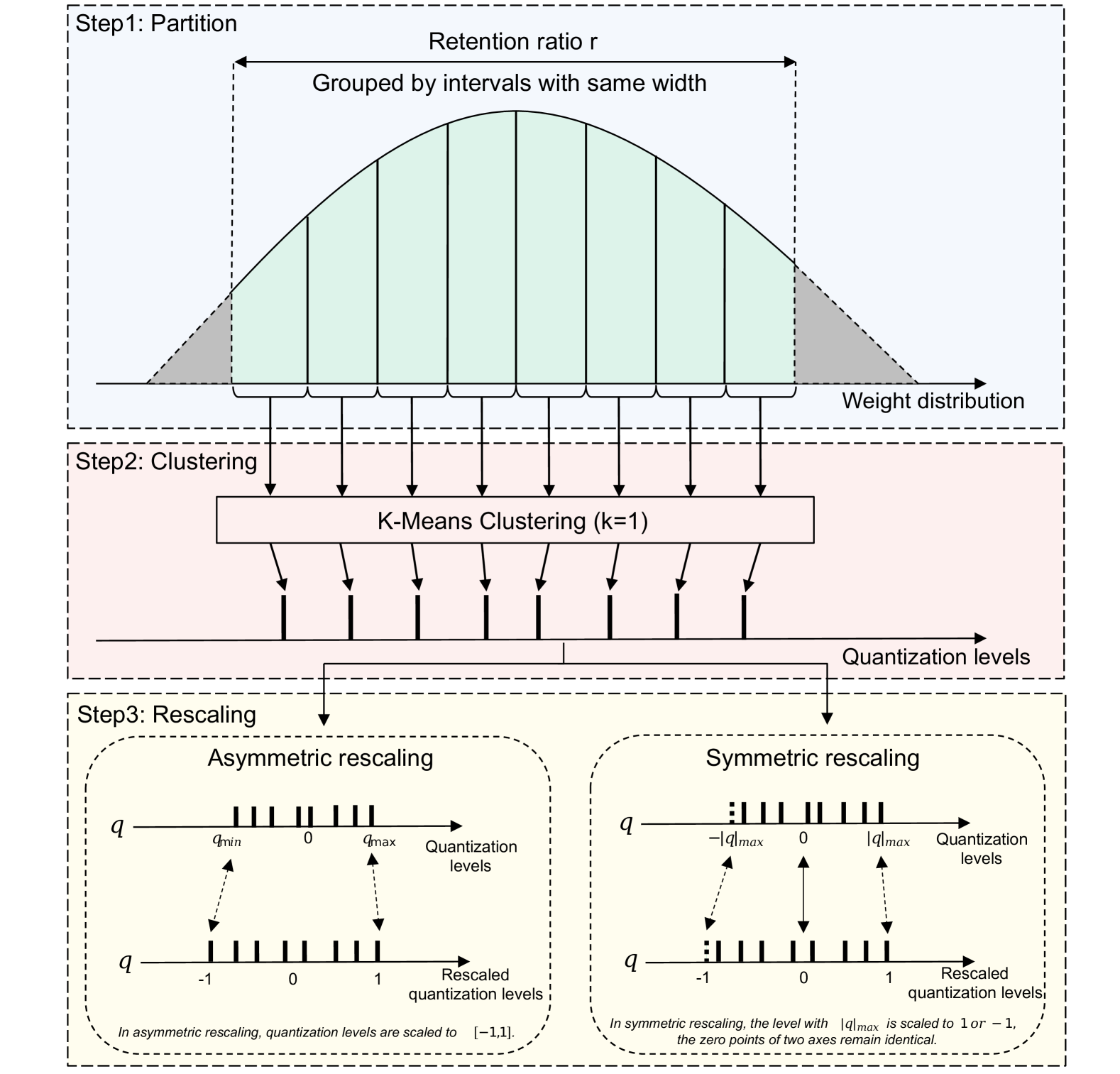
The researchers in this study focused on quantizing the [object Object] speaker verification model, which is considered a state-of-the-art pre-trained model. They developed an optimization framework to analyze the performance changes and model size reductions in each layer of the pre-trained model, allowing them to find the optimal quantization strategy.
The key steps in their quantization approach were:
- Analyzing the impact of quantizing each layer of the pre-trained model, both in terms of performance degradation and model size reduction.
- Using this analysis to develop an optimization algorithm that could find the best combination of quantization parameters to minimise performance loss while maximizing model size reduction.
- Applying the optimized quantization to the pre-trained ECAPA-TDNN model, resulting in a 50% reduction in model size with only a 0.07% increase in the Equal Error Rate (EER) metric.
This is the first attempt to maintain the performance of the state-of-the-art ECAPA-TDNN speaker verification model while significantly [object Object]. The researchers' quantization algorithm represents an important advance in making high-quality speech verification models more resource-efficient and deployable on a wider range of devices.
Critical Analysis
The researchers have done a commendable job in developing an effective quantization strategy for the ECAPA-TDNN speaker verification model. By carefully analyzing the impact of quantization on each layer of the pre-trained model, they were able to find an optimal balance between performance and model size reduction.
However, the paper does not provide a detailed analysis of the computational and memory savings achieved through the quantization process. While the 50% model size reduction is impressive, it would be helpful to understand the actual runtime and memory improvements on different hardware platforms.
Additionally, the researchers only evaluated their quantization approach on a single speaker verification model, the ECAPA-TDNN. It would be valuable to see how their framework performs when applied to other state-of-the-art speech models, or even models in other domains, to assess its broader applicability.
Another potential area for further research could be exploring the use of [object Object], where different layers of the model are quantized to different precisions. This could potentially lead to even greater model size reductions without significant performance degradation.
Overall, this research represents an important step forward in making high-quality speech verification models more efficient and deployable on a wider range of devices. The researchers' optimization-based quantization approach is a promising technique that could have applications beyond just speaker verification.
Conclusion
This research proposes an effective optimization framework for quantizing a state-of-the-art speaker verification model, the ECAPA-TDNN. By carefully analyzing the impact of quantization on each layer of the pre-trained model, the researchers were able to significantly reduce the model size (by 50%) while maintaining a high level of accuracy (with only a 0.07% increase in the Equal Error Rate).
This breakthrough in [object Object] is an important step forward in making advanced speech verification models more resource-efficient and deployable on a wider range of devices, including mobile phones and embedded systems. The researchers' quantization algorithm represents a valuable contribution to the field of speech recognition and could have broader applications in other domains as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Optimization of DNN-based speaker verification model through efficient quantization technique
Yeona Hong, Woo-Jin Chung, Hong-Goo Kang
As Deep Neural Networks (DNNs) rapidly advance in various fields, including speech verification, they typically involve high computational costs and substantial memory consumption, which can be challenging to manage on mobile systems. Quantization of deep models offers a means to reduce both computational and memory expenses. Our research proposes an optimization framework for the quantization of the speaker verification model. By analyzing performance changes and model size reductions in each layer of a pre-trained speaker verification model, we have effectively minimized performance degradation while significantly reducing the model size. Our quantization algorithm is the first attempt to maintain the performance of the state-of-the-art pre-trained speaker verification model, ECAPATDNN, while significantly compressing its model size. Overall, our quantization approach resulted in reducing the model size by half, with an increase in EER limited to 0.07%.
Read more7/15/2024
0
Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
Bei Liu, Haoyu Wang, Yanmin Qian
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
Read more7/23/2024

0
Comprehensive Study on Performance Evaluation and Optimization of Model Compression: Bridging Traditional Deep Learning and Large Language Models
Aayush Saxena, Arit Kumar Bishwas, Ayush Ashok Mishra, Ryan Armstrong
Deep learning models have achieved tremendous success in most of the industries in recent years. The evolution of these models has also led to an increase in the model size and energy requirement, making it difficult to deploy in production on low compute devices. An increase in the number of connected devices around the world warrants compressed models that can be easily deployed at the local devices with low compute capacity and power accessibility. A wide range of solutions have been proposed by different researchers to reduce the size and complexity of such models, prominent among them are, Weight Quantization, Parameter Pruning, Network Pruning, low-rank representation, weights sharing, neural architecture search, knowledge distillation etc. In this research work, we investigate the performance impacts on various trained deep learning models, compressed using quantization and pruning techniques. We implemented both, quantization and pruning, compression techniques on popular deep learning models used in the image classification, object detection, language models and generative models-based problem statements. We also explored performance of various large language models (LLMs) after quantization and low rank adaptation. We used the standard evaluation metrics (model's size, accuracy, and inference time) for all the related problem statements and concluded this paper by discussing the challenges and future work.
Read more7/24/2024

0
Resource-Efficient Speech Quality Prediction through Quantization Aware Training and Binary Activation Maps
Mattias Nilsson, Riccardo Miccini, Cl'ement Laroche, Tobias Piechowiak, Friedemann Zenke
As speech processing systems in mobile and edge devices become more commonplace, the demand for unintrusive speech quality monitoring increases. Deep learning methods provide high-quality estimates of objective and subjective speech quality metrics. However, their significant computational requirements are often prohibitive on resource-constrained devices. To address this issue, we investigated binary activation maps (BAMs) for speech quality prediction on a convolutional architecture based on DNSMOS. We show that the binary activation model with quantization aware training matches the predictive performance of the baseline model. It further allows using other compression techniques. Combined with 8-bit weight quantization, our approach results in a 25-fold memory reduction during inference, while replacing almost all dot products with summations. Our findings show a path toward substantial resource savings by supporting mixed-precision binary multiplication in hard- and software.
Read more7/8/2024