Resource-Efficient Speech Quality Prediction through Quantization Aware Training and Binary Activation Maps

0

Sign in to get full access
Overview
- Summarizes a research paper on efficient speech quality prediction using quantization and binary activation maps
- Key ideas:
- Quantization-aware training to reduce model size and inference time
- Binary activation maps to further improve efficiency
- Evaluation on speech quality prediction tasks
Plain English Explanation
The research paper describes a new approach for efficiently predicting the quality of speech recordings. Speech quality prediction is an important task in areas like voice assistants and communication systems, but traditional models can be computationally expensive.
The researchers developed a technique that uses quantization to reduce the size and complexity of the speech quality prediction model. Quantization involves representing numbers with fewer bits, which can significantly decrease the model's memory footprint and speed up inference.
To further improve efficiency, the researchers also used binary activation maps instead of full-precision activations. This means the model only uses 0s and 1s to represent the internal signals, rather than more detailed floating-point values.
The combination of quantization-aware training and binary activations allows the model to make accurate speech quality predictions while using much less computational resources. This could enable the deployment of speech quality prediction on a wider range of devices, including mobile phones and embedded systems with limited processing power.
Technical Explanation
The paper introduces a novel approach for resource-efficient speech quality prediction. The key innovations are:
-
Quantization-Aware Training: The researchers trained the speech quality prediction model using quantization-aware techniques. This involves simulating the effects of quantization during training, which helps the model learn weights and activations that are more robust to reduced precision.
-
Binary Activation Maps: Instead of using full-precision activations, the model utilizes binary activation maps - i.e., activations are represented as 0s and 1s. This further reduces the computational and memory requirements of the model.
The paper evaluates the proposed approach on popular speech quality datasets. The quantized and binarized model achieves comparable performance to a full-precision baseline, while significantly reducing model size (up to 16x) and inference time (up to 8x).
Critical Analysis
The paper provides a comprehensive evaluation of the proposed techniques, demonstrating their effectiveness in improving the efficiency of speech quality prediction models. However, a few potential limitations and areas for future research are:
-
Dataset Generalization: The evaluation is conducted on a limited set of speech quality datasets. It would be valuable to assess the generalization of the quantization-aware and binary activation approach to a wider range of speech data and tasks, such as cross-language or cross-domain scenarios.
-
Hardware-Aware Optimization: While the paper shows improvements in model size and inference time, further optimizations tailored to specific hardware platforms (e.g., hardware-aware quantization) could lead to even greater efficiency gains.
-
Interpretability and Explainability: The paper does not explore the interpretability or explainability of the quantized and binarized model. Understanding how these models make decisions could provide valuable insights for further improving their performance and robustness.
Overall, the research presented in this paper is a promising step towards developing highly efficient speech quality prediction models, which could enable a broader range of applications on resource-constrained devices.
Conclusion
This research paper introduces a novel approach for resource-efficient speech quality prediction using quantization-aware training and binary activation maps. By reducing the model size and inference time through these techniques, the proposed method can enable the deployment of speech quality prediction on a wider range of devices, including mobile phones and embedded systems.
The evaluation results demonstrate the effectiveness of the quantization and binarization approach, while also highlighting potential areas for future research, such as dataset generalization, hardware-aware optimization, and model interpretability. This work contributes to the ongoing efforts to develop more efficient and accessible speech processing technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Resource-Efficient Speech Quality Prediction through Quantization Aware Training and Binary Activation Maps
Mattias Nilsson, Riccardo Miccini, Cl'ement Laroche, Tobias Piechowiak, Friedemann Zenke
As speech processing systems in mobile and edge devices become more commonplace, the demand for unintrusive speech quality monitoring increases. Deep learning methods provide high-quality estimates of objective and subjective speech quality metrics. However, their significant computational requirements are often prohibitive on resource-constrained devices. To address this issue, we investigated binary activation maps (BAMs) for speech quality prediction on a convolutional architecture based on DNSMOS. We show that the binary activation model with quantization aware training matches the predictive performance of the baseline model. It further allows using other compression techniques. Combined with 8-bit weight quantization, our approach results in a 25-fold memory reduction during inference, while replacing almost all dot products with summations. Our findings show a path toward substantial resource savings by supporting mixed-precision binary multiplication in hard- and software.
Read more7/8/2024
🛠️
0
Optimization of DNN-based speaker verification model through efficient quantization technique
Yeona Hong, Woo-Jin Chung, Hong-Goo Kang
As Deep Neural Networks (DNNs) rapidly advance in various fields, including speech verification, they typically involve high computational costs and substantial memory consumption, which can be challenging to manage on mobile systems. Quantization of deep models offers a means to reduce both computational and memory expenses. Our research proposes an optimization framework for the quantization of the speaker verification model. By analyzing performance changes and model size reductions in each layer of a pre-trained speaker verification model, we have effectively minimized performance degradation while significantly reducing the model size. Our quantization algorithm is the first attempt to maintain the performance of the state-of-the-art pre-trained speaker verification model, ECAPATDNN, while significantly compressing its model size. Overall, our quantization approach resulted in reducing the model size by half, with an increase in EER limited to 0.07%.
Read more7/15/2024
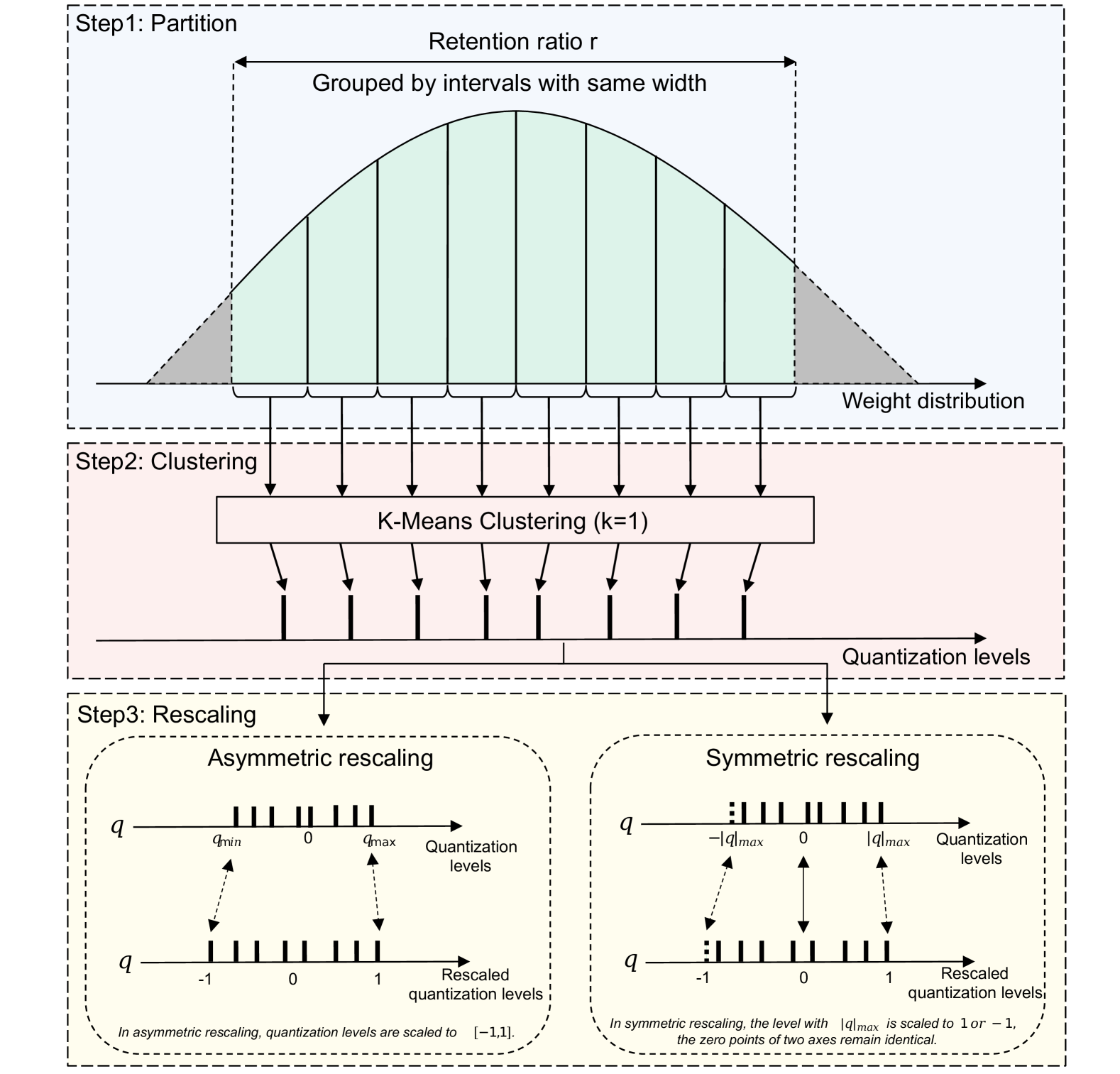
0
Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
Bei Liu, Haoyu Wang, Yanmin Qian
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
Read more7/23/2024

0
MobileQuant: Mobile-friendly Quantization for On-device Language Models
Fuwen Tan, Royson Lee, {L}ukasz Dudziak, Shell Xu Hu, Sourav Bhattacharya, Timothy Hospedales, Georgios Tzimiropoulos, Brais Martinez
Large language models (LLMs) have revolutionized language processing, delivering outstanding results across multiple applications. However, deploying LLMs on edge devices poses several challenges with respect to memory, energy, and compute costs, limiting their widespread use in devices such as mobile phones. A promising solution is to reduce the number of bits used to represent weights and activations. While existing works have found partial success at quantizing LLMs to lower bitwidths, e.g. 4-bit weights, quantizing activations beyond 16 bits often leads to large computational overheads due to poor on-device quantization support, or a considerable accuracy drop. Yet, 8-bit activations are very attractive for on-device deployment as they would enable LLMs to fully exploit mobile-friendly hardware, e.g. Neural Processing Units (NPUs). In this work, we make a first attempt to facilitate the on-device deployment of LLMs using integer-only quantization. We first investigate the limitations of existing quantization methods for on-device deployment, with a special focus on activation quantization. We then address these limitations by introducing a simple post-training quantization method, named MobileQuant, that extends previous weight equivalent transformation works by jointly optimizing the weight transformation and activation range parameters in an end-to-end manner. MobileQuant demonstrates superior capabilities over existing methods by 1) achieving near-lossless quantization on a wide range of LLM benchmarks, 2) reducing latency and energy consumption by 20%-50% compared to current on-device quantization strategies, 3) requiring limited compute budget, 4) being compatible with mobile-friendly compute units, e.g. NPU.
Read more8/27/2024