Optimization Hyper-parameter Laws for Large Language Models

0

Sign in to get full access
Overview
- This paper explores the optimization hyper-parameter laws that govern the training of large language models.
- The authors investigate how the choice of optimization hyper-parameters, such as learning rate and batch size, affects the performance and training dynamics of these models.
- They aim to establish universal laws that describe the optimal scaling of these hyper-parameters as a function of model size.
Plain English Explanation
The researchers in this paper are studying how the settings used to train large language models, like the ones that power things like chatbots and virtual assistants, affect the models' performance. Specifically, they're looking at the optimization hyper-parameters - the knobs and dials that control how the training process works.
Things like the learning rate, which determines how quickly the model updates its internal parameters, and the batch size, which controls how much data the model looks at in each training step, can have a big impact on how well the final model performs. The researchers wanted to find universal "laws" that describe how these hyper-parameters should be set as the models get larger and more complex.
By understanding these optimization laws, the researchers hope to make it easier to train high-performing large language models in the future. This could lead to better and more capable AI systems that can understand and generate human-like language.
Technical Explanation
The paper begins by reviewing related work on scaling laws for language models, which have established power-law relationships between model size and performance. The authors hypothesize that similar scaling laws may govern the optimal setting of optimization hyper-parameters.
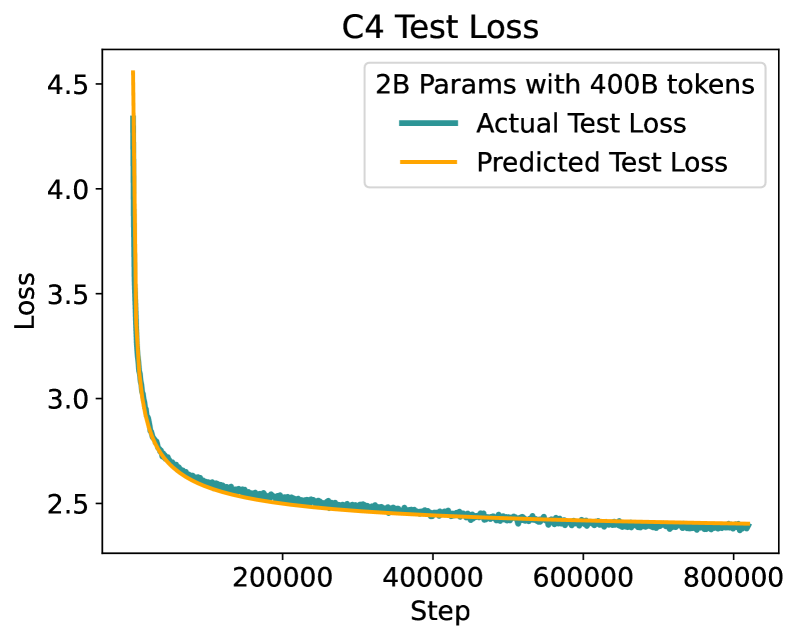
To test this, they train a wide range of large transformer-based language models, varying the learning rate, batch size, and other hyper-parameters. They then analyze how these choices impact the models' perplexity (a measure of language modeling quality) and convergence speed during training.
The key finding is that the optimal learning rate and batch size scale as power-laws of the model size, with exponents around 0.25 and 0.5 respectively. This means that as models get larger, the optimal learning rate increases more slowly, while the optimal batch size increases more rapidly.
The authors provide a theoretical framework to explain these scaling laws, rooted in the statistical properties of high-dimensional optimization landscapes. They also demonstrate how these laws can be used to guide the hyperparameter selection process for new language models.
Critical Analysis
The paper makes a valuable contribution by uncovering fundamental optimization principles that govern the training of large language models. The authors' rigorous empirical and theoretical approach lends credibility to their findings.
However, the study is limited to a specific class of transformer-based models and a narrow set of optimization hyper-parameters. It's possible that other architectural choices or training techniques could lead to different scaling laws. Additionally, the authors note that their analysis assumes the models are trained to convergence, which may not always be the case in practice.
Further research is needed to validate the generalizability of these optimization hyper-parameter laws, as well as to explore their implications for other types of large-scale neural networks. It would also be interesting to see how these findings could inform the development of more efficient and robust training algorithms for AI systems.
Conclusion
This paper provides important insights into the optimization principles underlying the training of large language models. By establishing universal scaling laws for key hyper-parameters, the authors have taken a step towards a more principled and systematic approach to developing high-performing AI systems that can understand and generate human-like language. These findings could have far-reaching implications for the future of natural language processing and the broader field of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimization Hyper-parameter Laws for Large Language Models
Xingyu Xie, Kuangyu Ding, Shuicheng Yan, Kim-Chuan Toh, Tianwen Wei
Large Language Models have driven significant AI advancements, yet their training is resource-intensive and highly sensitive to hyper-parameter selection. While scaling laws provide valuable guidance on model size and data requirements, they fall short in choosing dynamic hyper-parameters, such as learning-rate (LR) schedules, that evolve during training. To bridge this gap, we present Optimization Hyper-parameter Laws (Opt-Laws), a framework that effectively captures the relationship between hyper-parameters and training outcomes, enabling the pre-selection of potential optimal schedules. Grounded in stochastic differential equations, Opt-Laws introduce novel mathematical interpretability and offer a robust theoretical foundation for some popular LR schedules. Our extensive validation across diverse model sizes and data scales demonstrates Opt-Laws' ability to accurately predict training loss and identify optimal LR schedule candidates in pre-training, continual training, and fine-tuning scenarios. This approach significantly reduces computational costs while enhancing overall model performance.
Read more9/10/2024
0
Unraveling the Mystery of Scaling Laws: Part I
Hui Su, Zhi Tian, Xiaoyu Shen, Xunliang Cai
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
Read more4/8/2024

0
Resolving Discrepancies in Compute-Optimal Scaling of Language Models
Tomer Porian, Mitchell Wortsman, Jenia Jitsev, Ludwig Schmidt, Yair Carmon
Kaplan et al. and Hoffmann et al. developed influential scaling laws for the optimal model size as a function of the compute budget, but these laws yield substantially different predictions. We explain the discrepancy by reproducing the Kaplan scaling law on two datasets (OpenWebText2 and RefinedWeb) and identifying three factors causing the difference: last layer computational cost, warmup duration, and scale-dependent optimizer tuning. With these factors corrected, we obtain excellent agreement with the Hoffmann et al. (i.e., Chinchilla) scaling law. Counter to a hypothesis of Hoffmann et al., we find that careful learning rate decay is not essential for the validity of their scaling law. As a secondary result, we derive scaling laws for the optimal learning rate and batch size, finding that tuning the AdamW $beta_2$ parameter is essential at lower batch sizes.
Read more7/26/2024
📈
0
Navigating Scaling Laws: Compute Optimality in Adaptive Model Training
Sotiris Anagnostidis, Gregor Bachmann, Imanol Schlag, Thomas Hofmann
In recent years, the state-of-the-art in deep learning has been dominated by very large models that have been pre-trained on vast amounts of data. The paradigm is very simple: investing more computational resources (optimally) leads to better performance, and even predictably so; neural scaling laws have been derived that accurately forecast the performance of a network for a desired level of compute. This leads to the notion of a `compute-optimal' model, i.e. a model that allocates a given level of compute during training optimally to maximize performance. In this work, we extend the concept of optimality by allowing for an `adaptive' model, i.e. a model that can change its shape during training. By doing so, we can design adaptive models that optimally traverse between the underlying scaling laws and outpace their `static' counterparts, leading to a significant reduction in the required compute to reach a given target performance. We show that our approach generalizes across modalities and different shape parameters.
Read more5/24/2024