Unraveling the Mystery of Scaling Laws: Part I
2403.06563
0
0
Abstract
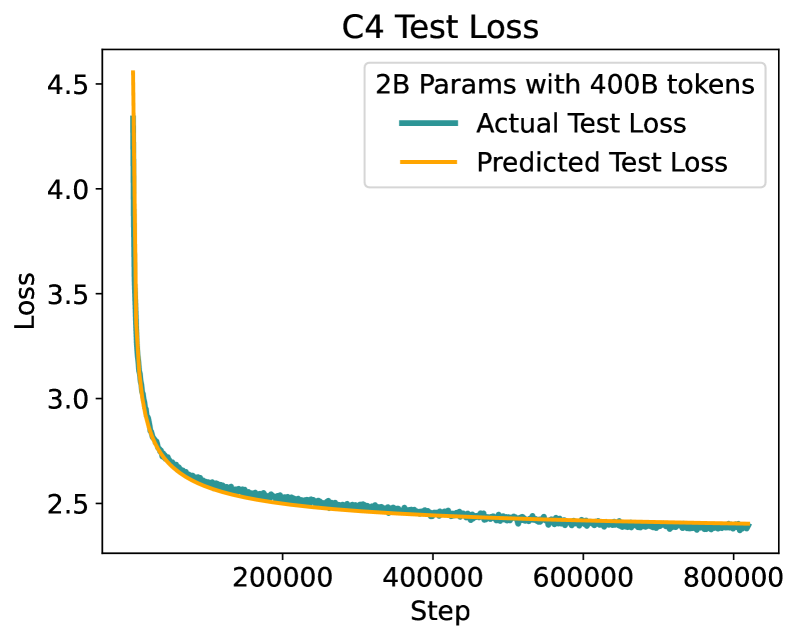
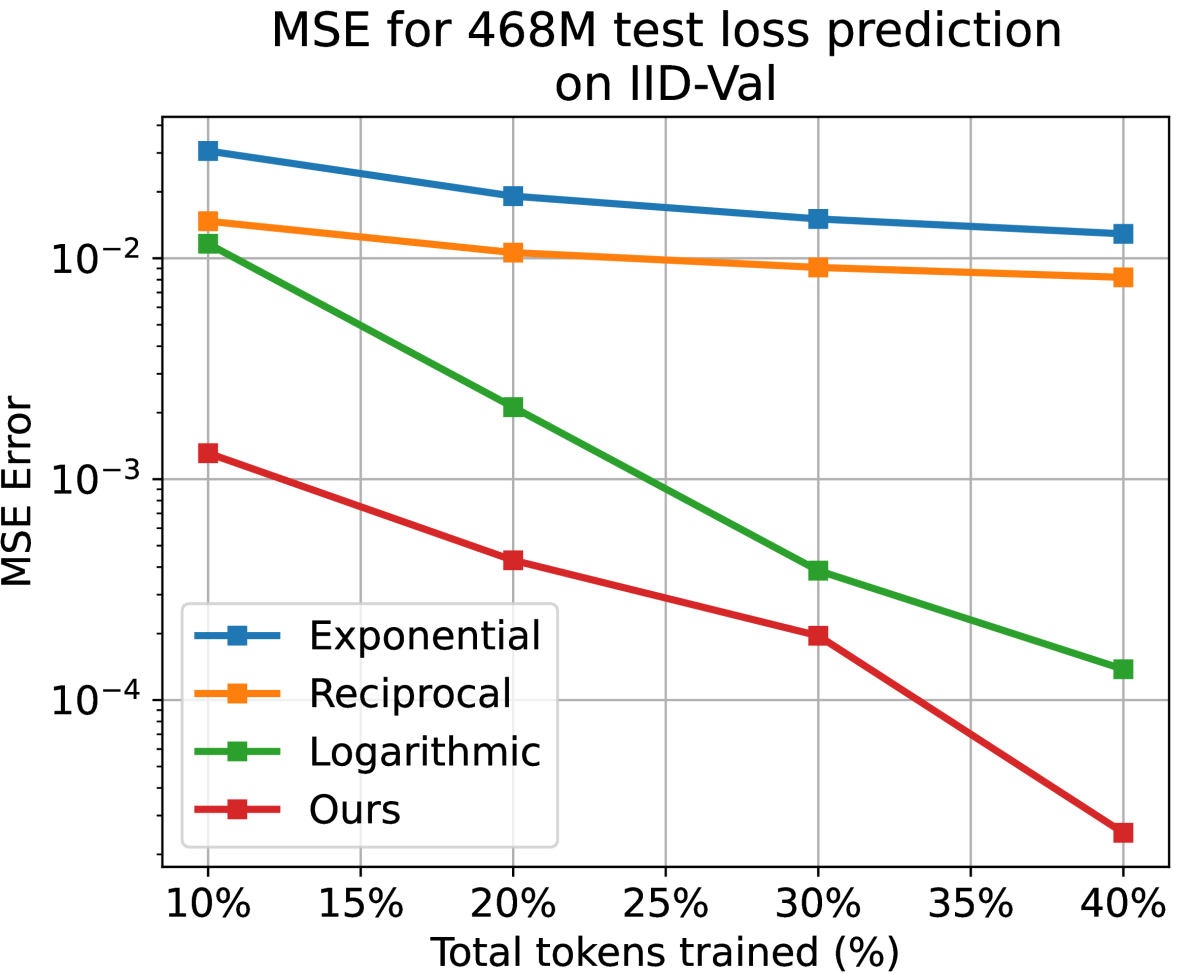
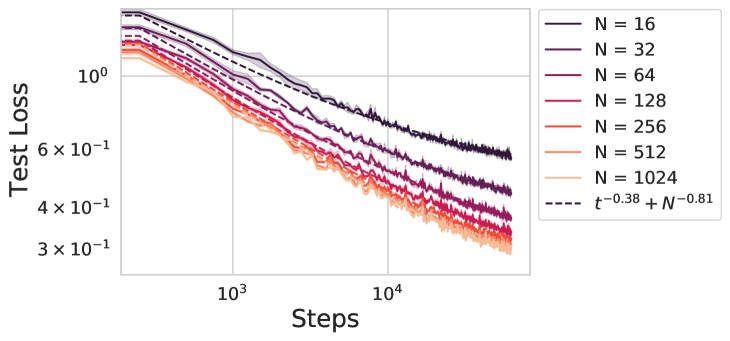
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores the scaling properties of deep learning models, examining how their performance and capabilities scale with model size and dataset size.
- Investigates the emergence of new abilities in large language models as they scale.
- Discusses the potential implications and limitations of these scaling laws for the development of increasingly capable AI systems.
Plain English Explanation
Scaling laws are the mathematical relationships that describe how the performance and capabilities of deep learning models change as their size and the amount of training data increases. This paper aims to unravel the mysteries behind these scaling laws, exploring how they apply to different types of AI models, from language models to image generators.
The researchers looked at how factors like the number of model parameters and the size of the training dataset can influence a model's ability to perform various tasks. They found that as models get larger and have access to more data, they often develop new and unexpected capabilities. For example, large language models can begin to display a better understanding of the world and common sense reasoning as they scale up.
However, the paper also cautions that "bigger is not always better" when it comes to AI models. The scaling properties of some models may have limits, where additional size and data do not always lead to proportional improvements in performance. Understanding these scaling laws can help researchers and developers design more efficient and effective AI systems.
Technical Explanation
The paper investigates the scaling properties of deep learning models across a variety of domains, including image recognition, text generation, and common sense reasoning. The researchers collect empirical data on model performance and capabilities as a function of model size (i.e., number of parameters) and dataset size.
They find that many deep learning models exhibit power-law scaling, where performance scales as a power function of the model and dataset size. This suggests the existence of underlying universal scaling laws that govern the behavior of complex AI systems. The exponents of these power laws can vary depending on the specific task and model architecture, providing insights into the fundamental limits and tradeoffs of different approaches.
The paper also explores the emergence of new abilities in large language models as they scale, such as improved common sense reasoning and understanding. This suggests that scaling up models can lead to the spontaneous development of novel capabilities, rather than just incremental improvements.
Critical Analysis
The paper provides a comprehensive and detailed analysis of scaling laws in deep learning, drawing insights from a wide range of model types and tasks. However, it also acknowledges several caveats and limitations to the research:
- The scaling laws observed may not hold for all possible model architectures and tasks, and further research is needed to understand the scope and boundaries of these laws.
- The paper focuses primarily on empirical observations and does not offer a complete theoretical framework to explain the underlying mechanisms driving the observed scaling phenomena.
- The research is limited to the specific datasets and model configurations studied, and the generalizability of the findings to real-world applications may be constrained.
Additionally, while the paper highlights the emergence of new capabilities in large language models, it does not fully address the potential risks and ethical considerations associated with the development of such powerful AI systems. Further research and discussion on the societal implications of scaling laws in AI would be valuable.
Conclusion
This paper offers important insights into the scaling properties of deep learning models, shedding light on the fundamental relationships between model size, dataset size, and model performance and capabilities. The findings suggest the existence of universal scaling laws that govern the behavior of complex AI systems, with potentially far-reaching implications for the development of increasingly capable and efficient AI models.
By understanding these scaling laws, researchers and developers can work towards designing more effective and scalable AI systems, while also considering the ethical and societal implications of these technologies as they continue to advance. The exploration of scaling laws in AI is a crucial step towards unlocking the full potential of these transformative technologies.
Related Papers
Temporal Scaling Law for Large Language Models
Yizhe Xiong, Xiansheng Chen, Xin Ye, Hui Chen, Zijia Lin, Haoran Lian, Jianwei Niu, Guiguang Ding
0
0
Recently, Large Language Models (LLMs) are widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed as Scaling Laws, have discovered that the loss of LLMs scales as power laws with model size, computational budget, and dataset size. However, the performance of LLMs throughout the training process remains untouched. In this paper, we propose the novel concept of Temporal Scaling Law and study the loss of LLMs from the temporal dimension. We first investigate the imbalance of loss on each token positions and develop a reciprocal-law across model scales and training stages. We then derive the temporal scaling law by studying the temporal patterns of the reciprocal-law parameters. Results on both in-distribution (IID) data and out-of-distribution (OOD) data demonstrate that our temporal scaling law accurately predicts the performance of LLMs in future training stages. Moreover, the temporal scaling law reveals that LLMs learn uniformly on different token positions, despite the loss imbalance. Experiments on pre-training LLMs in various scales show that this phenomenon verifies the default training paradigm for generative language models, in which no re-weighting strategies are attached during training. Overall, the temporal scaling law provides deeper insight into LLM pre-training.
4/30/2024
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
0
0
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
4/15/2024
🧠
Explaining Neural Scaling Laws
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, Utkarsh Sharma
0
0
The population loss of trained deep neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains the origins of and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents under modifications of task and architecture aspect ratio. Our work provides a taxonomy for classifying different scaling regimes, underscores that there can be different mechanisms driving improvements in loss, and lends insight into the microscopic origins of and relationships between scaling exponents.
4/30/2024
✅
More Compute Is What You Need
Zhen Guo
0
0
Large language model pre-training has become increasingly expensive, with most practitioners relying on scaling laws to allocate compute budgets for model size and training tokens, commonly referred to as Compute-Optimal or Chinchilla Optimal. In this paper, we hypothesize a new scaling law that suggests model performance depends mostly on the amount of compute spent for transformer-based models, independent of the specific allocation to model size and dataset size. Using this unified scaling law, we predict that (a) for inference efficiency, training should prioritize smaller model sizes and larger training datasets, and (b) assuming the exhaustion of available web datasets, scaling the model size might be the only way to further improve model performance.
5/3/2024