Optimization Solution Functions as Deterministic Policies for Offline Reinforcement Learning

0

Sign in to get full access
Overview
- The paper proposes a new approach for offline reinforcement learning (RL) where the optimization solution functions are used as deterministic policies.
- This contrasts with typical RL methods that learn stochastic policies through iterative interactions with the environment.
- The key idea is to directly leverage the solutions from offline optimization problems as effective policies, without the need for explicit policy learning.
Plain English Explanation
The paper introduces a novel way to do offline reinforcement learning. Typically, reinforcement learning involves an agent interacting with an environment, learning through trial and error to find an optimal policy - a set of rules for making decisions.
However, in many real-world scenarios, it's not possible or practical to have the agent directly interact with the environment. This is where offline RL comes in - the agent learns from a fixed dataset of past experiences, rather than exploring the environment live.
The key insight in this paper is that we can skip the explicit policy learning step altogether. Instead of having the agent learn a stochastic policy through iterative updates, the authors propose using the
In other words, they leverage the power of optimization techniques to find high-performing policies, without needing the agent to learn them from scratch. This offers potential benefits in terms of sample efficiency and performance, as the optimization solutions can provide a strong starting point.
Technical Explanation
The paper presents a novel approach for offline RL, where the optimization solution functions are used as deterministic policies, in contrast to the typical RL framework of learning stochastic policies.
The key technical contributions are:
-
Optimization-based Policy Generation: The authors propose directly using the solutions to offline optimization problems as deterministic policies, without the need for explicit policy learning. This leverages the power of optimization to find high-performing policies.
-
Provable Policy Improvement: They provide theoretical analysis showing that under certain conditions, the proposed approach can provably improve upon the performance of the initial optimization solutions.
-
Experiments: The authors demonstrate the effectiveness of their approach on several benchmark control tasks, showing improved sample efficiency and performance compared to standard RL methods.
The proposed approach offers an alternative to the traditional RL paradigm, potentially providing benefits in terms of sample efficiency and policy quality by directly utilizing optimization solutions as effective deterministic policies.
Critical Analysis
The paper presents a promising direction for offline RL, but some potential limitations and areas for further research are worth considering:
-
Applicability to Complex Environments: The experiments in the paper focus on relatively simple control tasks. It's unclear how well the optimization-based policy generation approach would scale to more complex, high-dimensional environments typically encountered in real-world applications.
-
Sensitivity to Optimization Quality: The performance of the proposed method relies heavily on the quality of the initial optimization solutions. If the optimization process fails to find good solutions, the resulting policies may not be effective.
-
Exploration-Exploitation Tradeoff: By using deterministic policies, the proposed approach may struggle to balance exploration and exploitation, which is a crucial aspect of effective RL. Incorporating some degree of stochasticity or exploration could be an area for future research.
-
Generalization and Transfer Learning: The paper does not extensively investigate the generalization capabilities of the optimization-based policies or their potential for transfer learning to related tasks or environments.
Overall, the paper presents an interesting and potentially impactful approach to offline RL, but further research is needed to address the identified limitations and explore the broader applicability of the method.
Conclusion
This paper introduces a novel approach for offline reinforcement learning that directly uses optimization solution functions as deterministic policies, instead of the typical iterative process of learning stochastic policies.
The key idea is to leverage the power of optimization techniques to find high-performing policies, without the need for explicit policy learning. The authors provide theoretical analysis and experimental results demonstrating the potential benefits of this approach in terms of sample efficiency and policy performance.
While the proposed method shows promise, further research is needed to address potential limitations, such as scaling to more complex environments, ensuring robustness to optimization quality, and exploring generalization and transfer learning capabilities. Nonetheless, this paper offers a thought-provoking alternative to the traditional reinforcement learning paradigm, with implications for improving the efficiency and effectiveness of offline RL systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimization Solution Functions as Deterministic Policies for Offline Reinforcement Learning
Vanshaj Khattar, Ming Jin
Offline reinforcement learning (RL) is a promising approach for many control applications but faces challenges such as limited data coverage and value function overestimation. In this paper, we propose an implicit actor-critic (iAC) framework that employs optimization solution functions as a deterministic policy (actor) and a monotone function over the optimal value of optimization as a critic. By encoding optimality in the actor policy, we show that the learned policies are robust to the suboptimality of the learned actor parameters via the exponentially decaying sensitivity (EDS) property. We obtain performance guarantees for the proposed iAC framework and show its benefits over general function approximation schemes. Finally, we validate the proposed framework on two real-world applications and show a significant improvement over state-of-the-art (SOTA) offline RL methods.
Read more8/29/2024
0
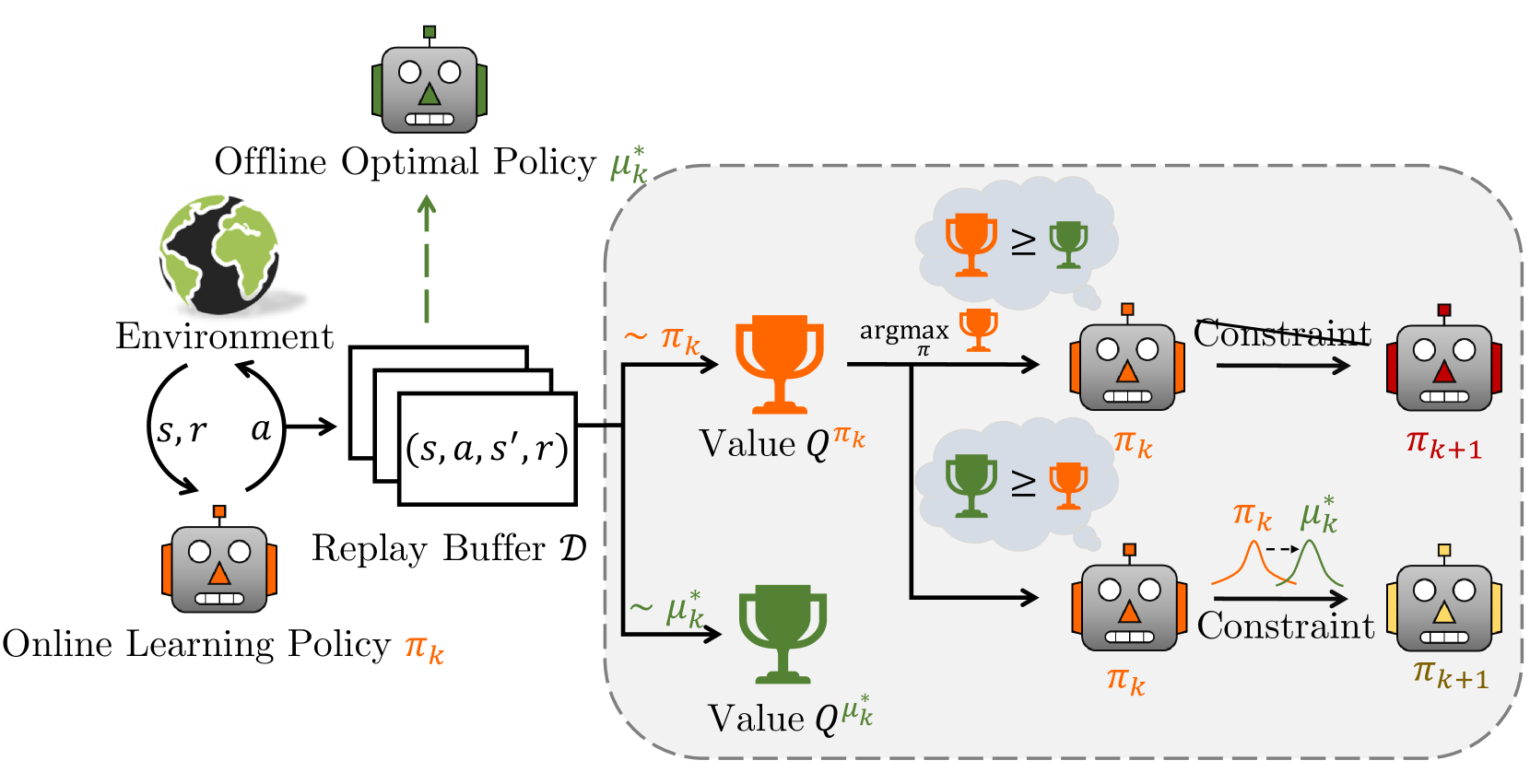
Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.
Read more5/30/2024
0
Efficient Offline Reinforcement Learning: The Critic is Critical
Adam Jelley, Trevor McInroe, Sam Devlin, Amos Storkey
Recent work has demonstrated both benefits and limitations from using supervised approaches (without temporal-difference learning) for offline reinforcement learning. While off-policy reinforcement learning provides a promising approach for improving performance beyond supervised approaches, we observe that training is often inefficient and unstable due to temporal difference bootstrapping. In this paper we propose a best-of-both approach by first learning the behavior policy and critic with supervised learning, before improving with off-policy reinforcement learning. Specifically, we demonstrate improved efficiency by pre-training with a supervised Monte-Carlo value-error, making use of commonly neglected downstream information from the provided offline trajectories. We find that we are able to more than halve the training time of the considered offline algorithms on standard benchmarks, and surprisingly also achieve greater stability. We further build on the importance of having consistent policy and value functions to propose novel hybrid algorithms, TD3+BC+CQL and EDAC+BC, that regularize both the actor and the critic towards the behavior policy. This helps to more reliably improve on the behavior policy when learning from limited human demonstrations. Code is available at https://github.com/AdamJelley/EfficientOfflineRL
Read more6/21/2024

0
Strategically Conservative Q-Learning
Yutaka Shimizu, Joey Hong, Sergey Levine, Masayoshi Tomizuka
Offline reinforcement learning (RL) is a compelling paradigm to extend RL's practical utility by leveraging pre-collected, static datasets, thereby avoiding the limitations associated with collecting online interactions. The major difficulty in offline RL is mitigating the impact of approximation errors when encountering out-of-distribution (OOD) actions; doing so ineffectively will lead to policies that prefer OOD actions, which can lead to unexpected and potentially catastrophic results. Despite the variety of works proposed to address this issue, they tend to excessively suppress the value function in and around OOD regions, resulting in overly pessimistic value estimates. In this paper, we propose a novel framework called Strategically Conservative Q-Learning (SCQ) that distinguishes between OOD data that is easy and hard to estimate, ultimately resulting in less conservative value estimates. Our approach exploits the inherent strengths of neural networks to interpolate, while carefully navigating their limitations in extrapolation, to obtain pessimistic yet still property calibrated value estimates. Theoretical analysis also shows that the value function learned by SCQ is still conservative, but potentially much less so than that of Conservative Q-learning (CQL). Finally, extensive evaluation on the D4RL benchmark tasks shows our proposed method outperforms state-of-the-art methods. Our code is available through url{https://github.com/purewater0901/SCQ}.
Read more6/10/2024