Optimizing Ingredient Substitution Using Large Language Models to Enhance Phytochemical Content in Recipes

0
💬
Sign in to get full access
Overview
- Researchers explored how large language models (LLMs) can be used to optimize ingredient substitutions in recipes to enhance the phytochemical content of meals.
- Phytochemicals are compounds found in plants that may offer potential health benefits based on preclinical studies.
- The researchers fine-tuned models like GPT-3.5, DaVinci, and TinyLlama using an ingredient substitution dataset.
- The models were then used to predict substitutions that increase phytochemical content and create a dataset of enriched recipes.
Plain English Explanation
Cooking and nutrition are becoming more scientific. Researchers wanted to see if they could use powerful AI language models to find healthier ingredient substitutions in recipes.
Phytochemicals are special compounds found in plants that may have health benefits. The researchers trained these AI models to predict ingredient swaps that would increase the amount of phytochemicals in recipes.
The models were able to improve the accuracy of suggesting good ingredient replacements compared to a baseline. This allowed the researchers to create over 1,900 recipes with more phytochemicals.
While this is a promising approach, the researchers caution that the health claims are based on early studies and need more clinical testing. But it shows how AI could help make our meals healthier in the future.
Technical Explanation
The researchers fine-tuned several large language models, including GPT-3.5, DaVinci, and Meta's TinyLlama, on an ingredient substitution dataset. This allowed the models to learn patterns for predicting ingredient swaps that would enhance the phytochemical content of recipes.
When evaluated on ingredient substitution tasks, the fine-tuned models showed improved performance. On the original GISMo dataset, accuracy increased from the baseline of 34.53% ± 0.10% to 38.03% ± 0.28%. On a refined version of the dataset, accuracy improved from 40.24% ± 0.36% to 54.46% ± 0.29%.
Using the trained models, the researchers generated 1,951 phytochemically enriched ingredient pairings and 1,639 unique recipes. This demonstrates the potential of leveraging large language models to optimize ingredient substitutions for healthier cooking.
Critical Analysis
The researchers acknowledge that while their approach shows promise, the claims about health benefits are based on preclinical evidence and require further clinical validation. Broader datasets and additional research would be needed to more comprehensively evaluate the nutritional impact of the suggested ingredient substitutions.
Some other potential limitations include the reliance on a relatively small ingredient substitution dataset, the focus on phytochemicals rather than a broader range of nutritional factors, and the uncertainty around the long-term stability and scalability of the fine-tuned models.
Nevertheless, this work represents an important step forward in using AI techniques to promote healthier eating practices by optimizing recipes based on scientific nutritional principles. Further research in this area could yield valuable insights and applications for integrating computational methods with nutritional science.
Conclusion
This study explores how large language models can be applied to enhance the phytochemical content of recipes through optimized ingredient substitutions. While the health claims require further clinical validation, the research demonstrates the potential of using AI to align culinary practices with scientifically supported nutritional goals.
By fine-tuning models on ingredient substitution data, the researchers were able to improve the accuracy of predicting substitutions that increase phytochemical levels. This allowed them to create a dataset of over 1,600 enriched recipes, representing a step forward in using computational methods to promote healthier eating.
As the field of computational gastronomy continues to evolve, this work highlights the important role that AI-driven optimization can play in integrating science and culinary practices to address nutritional challenges and improve public health outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Optimizing Ingredient Substitution Using Large Language Models to Enhance Phytochemical Content in Recipes
Luis Rita, Josh Southern, Ivan Laponogov, Kyle Higgins, Kirill Veselkov
In the emerging field of computational gastronomy, aligning culinary practices with scientifically supported nutritional goals is increasingly important. This study explores how large language models (LLMs) can be applied to optimize ingredient substitutions in recipes, specifically to enhance the phytochemical content of meals. Phytochemicals are bioactive compounds found in plants, which, based on preclinical studies, may offer potential health benefits. We fine-tuned models, including OpenAI's GPT-3.5, DaVinci, and Meta's TinyLlama, using an ingredient substitution dataset. These models were used to predict substitutions that enhance phytochemical content and create a corresponding enriched recipe dataset. Our approach improved Hit@1 accuracy on ingredient substitution tasks, from the baseline 34.53 plus-minus 0.10% to 38.03 plus-minus 0.28% on the original GISMo dataset, and from 40.24 plus-minus 0.36% to 54.46 plus-minus 0.29% on a refined version of the same dataset. These substitutions led to the creation of 1,951 phytochemically enriched ingredient pairings and 1,639 unique recipes. While this approach demonstrates potential in optimizing ingredient substitutions, caution must be taken when drawing conclusions about health benefits, as the claims are based on preclinical evidence. Future work should include clinical validation and broader datasets to further evaluate the nutritional impact of these substitutions. This research represents a step forward in using AI to promote healthier eating practices, providing potential pathways for integrating computational methods with nutritional science.
Read more9/16/2024
0
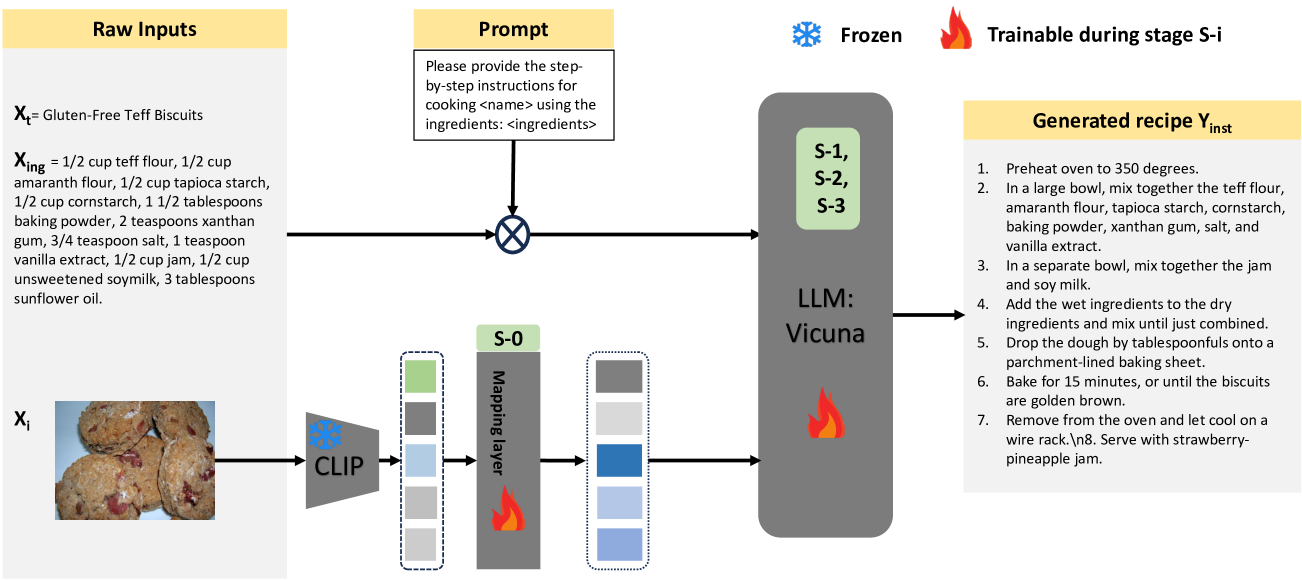
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Fnu Mohbat, Mohammed J. Zaki
In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
Read more9/2/2024
💬
0
Extracting chemical food safety hazards from the scientific literature automatically using large language models
Neris Ozen, Wenjuan Mu, Esther D. van Asselt, Leonieke M. van den Bulk
The number of scientific articles published in the domain of food safety has consistently been increasing over the last few decades. It has therefore become unfeasible for food safety experts to read all relevant literature related to food safety and the occurrence of hazards in the food chain. However, it is important that food safety experts are aware of the newest findings and can access this information in an easy and concise way. In this study, an approach is presented to automate the extraction of chemical hazards from the scientific literature through large language models. The large language model was used out-of-the-box and applied on scientific abstracts; no extra training of the models or a large computing cluster was required. Three different styles of prompting the model were tested to assess which was the most optimal for the task at hand. The prompts were optimized with two validation foods (leafy greens and shellfish) and the final performance of the best prompt was evaluated using three test foods (dairy, maize and salmon). The specific wording of the prompt was found to have a considerable effect on the results. A prompt breaking the task down into smaller steps performed best overall. This prompt reached an average accuracy of 93% and contained many chemical contaminants already included in food monitoring programs, validating the successful retrieval of relevant hazards for the food safety domain. The results showcase how valuable large language models can be for the task of automatic information extraction from the scientific literature.
Read more5/28/2024

0
Small Molecule Optimization with Large Language Models
Philipp Guevorguian, Menua Bedrosian, Tigran Fahradyan, Gayane Chilingaryan, Hrant Khachatrian, Armen Aghajanyan
Recent advancements in large language models have opened new possibilities for generative molecular drug design. We present Chemlactica and Chemma, two language models fine-tuned on a novel corpus of 110M molecules with computed properties, totaling 40B tokens. These models demonstrate strong performance in generating molecules with specified properties and predicting new molecular characteristics from limited samples. We introduce a novel optimization algorithm that leverages our language models to optimize molecules for arbitrary properties given limited access to a black box oracle. Our approach combines ideas from genetic algorithms, rejection sampling, and prompt optimization. It achieves state-of-the-art performance on multiple molecular optimization benchmarks, including an 8% improvement on Practical Molecular Optimization compared to previous methods. We publicly release the training corpus, the language models and the optimization algorithm.
Read more7/29/2024