LLaVA-Chef: A Multi-modal Generative Model for Food Recipes

0
Sign in to get full access
Overview
- LLaVA-Chef is a multi-modal generative model for creating food recipes.
- It combines language and visual information to generate recipes that are coherent and relevant to the input.
- The model is trained on a large dataset of recipe text and images.
Plain English Explanation
LLaVA-Chef is an AI system that can generate new food recipes. It takes in both text information and visual information about food, and then uses that to create its own unique recipes.
The key idea is that by combining the textual knowledge about ingredients, instructions, and cooking processes with the visual understanding of food, the model can generate recipes that make sense and look appetizing. This is an advance over previous systems that could only use one type of information at a time.
The researchers trained LLaVA-Chef on a large dataset of existing recipes, including both the written text and images. This allowed the model to learn the patterns and relationships between the different elements that go into a good recipe.
When given a new prompt, such as a description of a desired dish or an image of some ingredients, LLaVA-Chef can then generate an original recipe that fits that input. The resulting recipes should be coherent, tasty, and feasible to prepare.
Technical Explanation
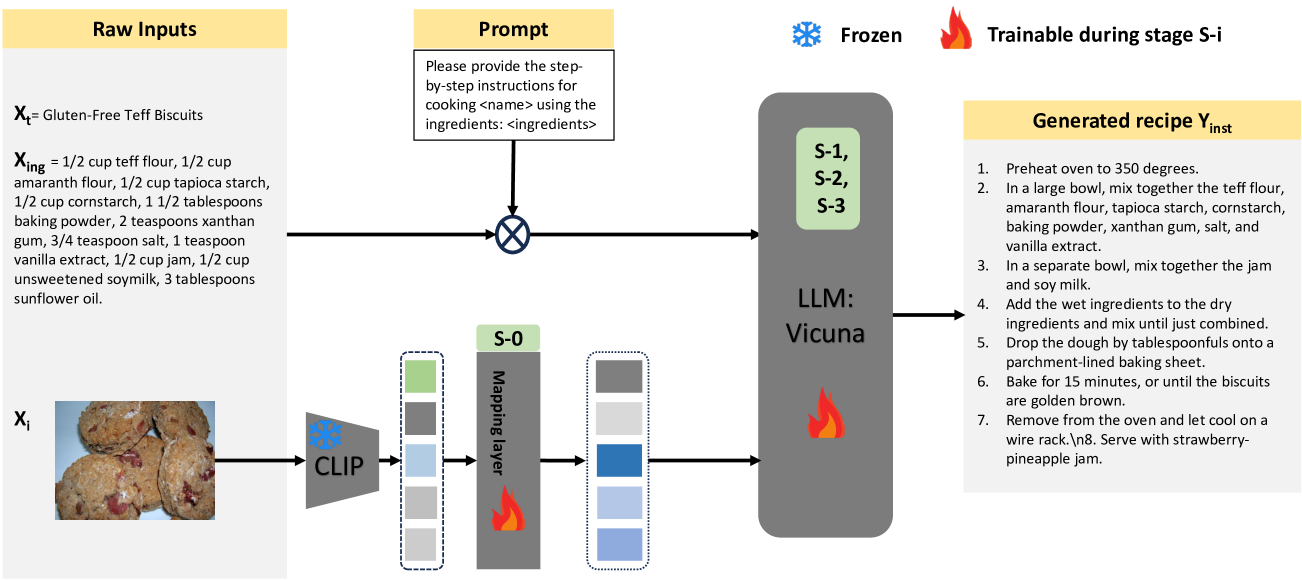
LLaVA-Chef is a multi-modal generative model that can generate food recipes by fusing textual and visual information. The model is based on a large language model and is fine-tuned on a dataset of recipe text and images.
The key technical components of LLaVA-Chef include:
- A text encoder that processes the recipe instructions and ingredients
- A visual encoder that processes images of food and ingredients
- A multi-modal fusion module that combines the text and visual representations
- A recipe generation module that uses the fused representation to produce new recipes
During training, the model learns to associate textual recipe elements with their corresponding visual elements. This allows it to generate coherent and relevant recipes when given either textual or visual inputs.
Critical Analysis
The researchers note that while LLaVA-Chef demonstrates promising results, there are some limitations to the current approach. One key issue is that the model may struggle to generate highly novel or creative recipes, as it is constrained by the patterns in the training data.
Additionally, the researchers acknowledge that evaluating the quality and tastiness of generated recipes is a challenging task that requires human judgment. Automated metrics may not fully capture the nuances of a good recipe.
Further research could explore ways to encourage more creativity in the recipe generation process, as well as developing better evaluation frameworks that account for the subjective nature of culinary preferences.
Conclusion
LLaVA-Chef represents an important step forward in the field of food computing by demonstrating the potential of multi-modal generative models for recipe creation. By fusing textual and visual information, the system can generate coherent and relevant recipes that could be useful for a variety of applications, from cooking assistance to food innovation.
While the current model has some limitations, the researchers have laid the groundwork for further advancements in this area. As multi-modal AI systems continue to improve, we may see increasingly sophisticated and creative food generation capabilities emerge in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLaVA-Chef: A Multi-modal Generative Model for Food Recipes
Fnu Mohbat, Mohammed J. Zaki
In the rapidly evolving landscape of online recipe sharing within a globalized context, there has been a notable surge in research towards comprehending and generating food recipes. Recent advancements in large language models (LLMs) like GPT-2 and LLaVA have paved the way for Natural Language Processing (NLP) approaches to delve deeper into various facets of food-related tasks, encompassing ingredient recognition and comprehensive recipe generation. Despite impressive performance and multi-modal adaptability of LLMs, domain-specific training remains paramount for their effective application. This work evaluates existing LLMs for recipe generation and proposes LLaVA-Chef, a novel model trained on a curated dataset of diverse recipe prompts in a multi-stage approach. First, we refine the mapping of visual food image embeddings to the language space. Second, we adapt LLaVA to the food domain by fine-tuning it on relevant recipe data. Third, we utilize diverse prompts to enhance the model's recipe comprehension. Finally, we improve the linguistic quality of generated recipes by penalizing the model with a custom loss function. LLaVA-Chef demonstrates impressive improvements over pretrained LLMs and prior works. A detailed qualitative analysis reveals that LLaVA-Chef generates more detailed recipes with precise ingredient mentions, compared to existing approaches.
Read more9/2/2024

0
FoodLMM: A Versatile Food Assistant using Large Multi-modal Model
Yuehao Yin, Huiyan Qi, Bin Zhu, Jingjing Chen, Yu-Gang Jiang, Chong-Wah Ngo
Large Multi-modal Models (LMMs) have made impressive progress in many vision-language tasks. Nevertheless, the performance of general LMMs in specific domains is still far from satisfactory. This paper proposes FoodLMM, a versatile food assistant based on LMMs with various capabilities, including food recognition, ingredient recognition, recipe generation, nutrition estimation, food segmentation and multi-round conversation. To facilitate FoodLMM to deal with tasks beyond pure text output, we introduce a series of novel task-specific tokens and heads, enabling the model to predict food nutritional values and multiple segmentation masks. We adopt a two-stage training strategy. In the first stage, we utilize multiple public food benchmarks for multi-task learning by leveraging the instruct-following paradigm. In the second stage, we construct a multi-round conversation dataset and a reasoning segmentation dataset to fine-tune the model, enabling it to conduct professional dialogues and generate segmentation masks based on complex reasoning in the food domain. Our fine-tuned FoodLMM achieves state-of-the-art results across several food benchmarks. We will make our code, models and datasets publicly available.
Read more4/15/2024
🏋️
0
Directed Domain Fine-Tuning: Tailoring Separate Modalities for Specific Training Tasks
Daniel Wen, Nafisa Hussain
Large language models (LLMs) and large visual language models (LVLMs) have been at the forefront of the artificial intelligence field, particularly for tasks like text generation, video captioning, and question-answering. Typically, it is more applicable to train these models on broader knowledge bases or datasets to increase generalizability, learn relationships between topics, and recognize patterns. Instead, we propose to provide instructional datasets specific to the task of each modality within a distinct domain and then fine-tune the parameters of the model using LORA. With our approach, we can eliminate all noise irrelevant to the given task while also ensuring that the model generates with enhanced precision. For this work, we use Video-LLaVA to generate recipes given cooking videos without transcripts. Video-LLaVA's multimodal architecture allows us to provide cooking images to its image encoder, cooking videos to its video encoder, and general cooking questions to its text encoder. Thus, we aim to remove all noise unrelated to cooking while improving our model's capabilities to generate specific ingredient lists and detailed instructions. As a result, our approach to fine-tuning Video-LLaVA leads to gains over the baseline Video-LLaVA by 2% on the YouCook2 dataset. While this may seem like a marginal increase, our model trains on an image instruction dataset 2.5% the size of Video-LLaVA's and a video instruction dataset 23.76% of Video-LLaVA's.
Read more6/26/2024
0
Deep Image-to-Recipe Translation
Jiangqin Ma, Bilal Mawji, Franz Williams
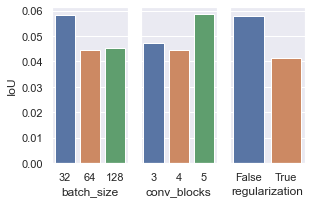
The modern saying, You Are What You Eat resonates on a profound level, reflecting the intricate connection between our identities and the food we consume. Our project, Deep Image-to-Recipe Translation, is an intersection of computer vision and natural language generation that aims to bridge the gap between cherished food memories and the art of culinary creation. Our primary objective involves predicting ingredients from a given food image. For this task, we first develop a custom convolutional network and then compare its performance to a model that leverages transfer learning. We pursue an additional goal of generating a comprehensive set of recipe steps from a list of ingredients. We frame this process as a sequence-to-sequence task and develop a recurrent neural network that utilizes pre-trained word embeddings. We address several challenges of deep learning including imbalanced datasets, data cleaning, overfitting, and hyperparameter selection. Our approach emphasizes the importance of metrics such as Intersection over Union (IoU) and F1 score in scenarios where accuracy alone might be misleading. For our recipe prediction model, we employ perplexity, a commonly used and important metric for language models. We find that transfer learning via pre-trained ResNet-50 weights and GloVe embeddings provide an exceptional boost to model performance, especially when considering training resource constraints. Although we have made progress on the image-to-recipe translation, there is an opportunity for future exploration with advancements in model architectures, dataset scalability, and enhanced user interaction.
Read more7/2/2024