Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
2406.11695
0
0
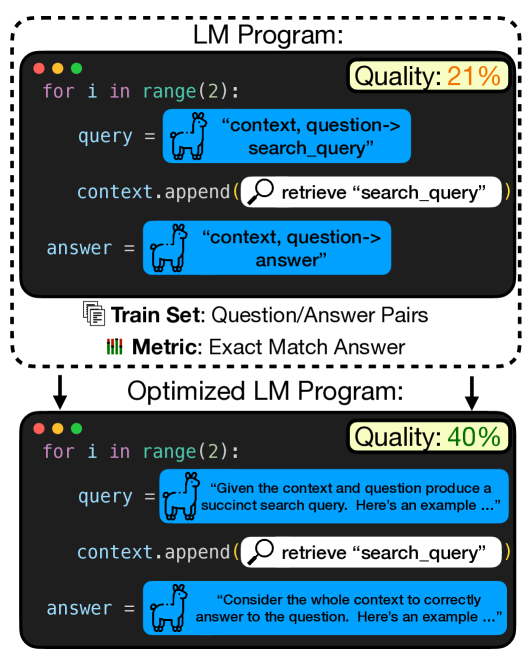
Abstract
Language Model Programs, i.e. sophisticated pipelines of modular language model (LM) calls, are increasingly advancing NLP tasks, but they require crafting prompts that are jointly effective for all modules. We study prompt optimization for LM programs, i.e. how to update these prompts to maximize a downstream metric without access to module-level labels or gradients. To make this tractable, we factorize our problem into optimizing the free-form instructions and few-shot demonstrations of every module and introduce several strategies to craft task-grounded instructions and navigate credit assignment across modules. Our strategies include (i) program- and data-aware techniques for proposing effective instructions, (ii) a stochastic mini-batch evaluation function for learning a surrogate model of our objective, and (iii) a meta-optimization procedure in which we refine how LMs construct proposals over time. Using these insights we develop MIPRO, a novel optimizer that outperforms baselines on five of six diverse LM programs using a best-in-class open-source model (Llama-3-8B), by as high as 12.9% accuracy. We will release our new optimizers and benchmark in DSPy at https://github.com/stanfordnlp/dspy
Create account to get full access
Overview
- The paper explores how to optimize instructions and demonstrations for multi-stage language model programs.
- It focuses on improving the effectiveness of language models in completing complex, multi-step tasks.
- The researchers investigate techniques for generating high-quality instructions and demonstrations to guide language models through these tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown remarkable capabilities in tasks like writing, translation, and question answering. However, they can struggle with more complex, multi-step tasks that require following a sequence of instructions or learning from demonstrations.
This paper examines ways to make instructions and demonstrations more effective for training LLMs to handle these kinds of tasks. The researchers explore techniques like optimizing the loss function over instructions and using a mixture of instructions and demonstrations to help the language models better understand and execute complex workflows.
By improving the quality of the instructions and demonstrations provided to LLMs, the goal is to enable them to tackle a wider range of real-world, multi-stage tasks with greater reliability and accuracy. This could have significant applications in areas like task automation, personal assistants, and industrial process control.
Technical Explanation
The paper presents a framework for optimizing the instructions and demonstrations used to train language models on multi-stage tasks. The key elements include:
-
Instruction Optimization: The researchers investigate techniques for tuning the loss function to encourage language models to better follow and retain the steps in a set of instructions.
-
Demonstration Optimization: The team explores ways to generate high-quality demonstrations that effectively convey the correct sequence of actions to the language model.
-
Instruction-Demonstration Mixing: The paper examines the benefits of combining instructions and demonstrations to provide more comprehensive training signals for the language model.
Through a series of experiments, the researchers demonstrate that these techniques can significantly improve the ability of large language models to execute complex, multi-step tasks compared to baseline approaches. The findings build on previous work in optimizing language models as optimizers and revisiting the limitations of small-scale LLMs.
Critical Analysis
The paper presents a thoughtful and rigorous approach to enhancing the capabilities of large language models in multi-stage tasks. However, the researchers acknowledge some key limitations and areas for further investigation:
- The experiments were conducted on a relatively narrow set of task domains, and it's unclear how well the techniques would generalize to a broader range of real-world applications.
- The instruction and demonstration optimization procedures require additional computational resources and could be challenging to scale to very large language models.
- The paper does not explore the potential for lexical sensitivity in the language model's responses, which could be an important consideration for safety and reliability.
Further research is needed to address these limitations and explore other techniques for improving language model performance on complex, multi-step tasks. Nonetheless, this paper represents an important step forward in advancing the state of the art in this critical area of language AI.
Conclusion
This paper presents a novel framework for optimizing the instructions and demonstrations used to train large language models on multi-stage tasks. By focusing on techniques like instruction loss function tuning and instruction-demonstration mixing, the researchers have demonstrated significant improvements in the ability of LLMs to execute complex workflows reliably and accurately.
While there are still some limitations and areas for further investigation, this work represents an important advancement in the field of language AI and could have far-reaching implications for applications like task automation, personal assistants, and industrial process control. As large language models continue to grow in capability, optimizing their performance on multi-step tasks will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, Xinyun Chen
0
0
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to our main application in prompt optimization, where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks. Code at https://github.com/google-deepmind/opro.
4/16/2024

Dual-Phase Accelerated Prompt Optimization
Muchen Yang, Moxin Li, Yongle Li, Zijun Chen, Chongming Gao, Junqi Zhang, Yangyang Li, Fuli Feng
0
0
Gradient-free prompt optimization methods have made significant strides in enhancing the performance of closed-source Large Language Models (LLMs) across a wide range of tasks. However, existing approaches make light of the importance of high-quality prompt initialization and the identification of effective optimization directions, thus resulting in substantial optimization steps to obtain satisfactory performance. In this light, we aim to accelerate prompt optimization process to tackle the challenge of low convergence rate. We propose a dual-phase approach which starts with generating high-quality initial prompts by adopting a well-designed meta-instruction to delve into task-specific information, and iteratively optimize the prompts at the sentence level, leveraging previous tuning experience to expand prompt candidates and accept effective ones. Extensive experiments on eight datasets demonstrate the effectiveness of our proposed method, achieving a consistent accuracy gain over baselines with less than five optimization steps.
6/21/2024
🛠️
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling
Yongchao Chen, Jacob Arkin, Yilun Hao, Yang Zhang, Nicholas Roy, Chuchu Fan
0
0
Prompt optimization aims to find the best prompt to a large language model (LLM) for a given task. LLMs have been successfully used to help find and improve prompt candidates for single-step tasks. However, realistic tasks for agents are multi-step and introduce new challenges: (1) Prompt content is likely to be more extensive and complex, making it more difficult for LLMs to analyze errors, (2) the impact of an individual step is difficult to evaluate, and (3) different people may have varied preferences about task execution. While humans struggle to optimize prompts, they are good at providing feedback about LLM outputs; we therefore introduce a new LLM-driven discrete prompt optimization framework PROMST that incorporates human-designed feedback rules to automatically offer direct suggestions for improvement. We also use an extra learned heuristic model that predicts prompt performance to efficiently sample from prompt candidates. This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across 11 representative multi-step tasks (an average 10.6%-29.3% improvement to current best methods on five LLMs respectively). We believe our work can serve as a benchmark for automatic prompt optimization for LLM-driven multi-step tasks. Datasets and Codes are available at https://github.com/yongchao98/PROMST. Project Page is available at https://yongchao98.github.io/MIT-REALM-PROMST/.
6/18/2024

Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers
Tuo Zhang, Jinyue Yuan, Salman Avestimehr
0
0
Numerous recent works aim to enhance the efficacy of Large Language Models (LLMs) through strategic prompting. In particular, the Optimization by PROmpting (OPRO) approach provides state-of-the-art performance by leveraging LLMs as optimizers where the optimization task is to find instructions that maximize the task accuracy. In this paper, we revisit OPRO for automated prompting with relatively small-scale LLMs, such as LLaMa-2 family and Mistral 7B. Our investigation reveals that OPRO shows limited effectiveness in small-scale LLMs, with limited inference capabilities constraining optimization ability. We suggest future automatic prompting engineering to consider both model capabilities and computational costs. Additionally, for small-scale LLMs, we recommend direct instructions that clearly outline objectives and methodologies as robust prompt baselines, ensuring efficient and effective prompt engineering in ongoing research.
5/17/2024