PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling
2402.08702
0
0
🛠️
Abstract
Prompt optimization aims to find the best prompt to a large language model (LLM) for a given task. LLMs have been successfully used to help find and improve prompt candidates for single-step tasks. However, realistic tasks for agents are multi-step and introduce new challenges: (1) Prompt content is likely to be more extensive and complex, making it more difficult for LLMs to analyze errors, (2) the impact of an individual step is difficult to evaluate, and (3) different people may have varied preferences about task execution. While humans struggle to optimize prompts, they are good at providing feedback about LLM outputs; we therefore introduce a new LLM-driven discrete prompt optimization framework PROMST that incorporates human-designed feedback rules to automatically offer direct suggestions for improvement. We also use an extra learned heuristic model that predicts prompt performance to efficiently sample from prompt candidates. This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across 11 representative multi-step tasks (an average 10.6%-29.3% improvement to current best methods on five LLMs respectively). We believe our work can serve as a benchmark for automatic prompt optimization for LLM-driven multi-step tasks. Datasets and Codes are available at https://github.com/yongchao98/PROMST. Project Page is available at https://yongchao98.github.io/MIT-REALM-PROMST/.
Create account to get full access
Overview
- This research paper focuses on the challenge of optimizing prompts for large language models (LLMs) in complex, multi-step tasks.
- While LLMs have been successfully used to help find and improve prompts for single-step tasks, multi-step tasks introduce new challenges:
- Prompt content is more extensive and complex, making it harder for LLMs to analyze errors.
- The impact of individual steps is difficult to evaluate.
- Different people may have varied preferences about task execution.
- The researchers introduce a new LLM-driven discrete prompt optimization framework called PROMST that incorporates human-designed feedback rules to automatically suggest prompt improvements.
- PROMST also uses an extra learned heuristic model to predict prompt performance and efficiently sample from prompt candidates.
- This approach significantly outperforms both human-engineered prompts and several other prompt optimization methods across 11 representative multi-step tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 have been used to help find and improve prompts, which are the instructions given to the model, for single-step tasks. However, real-world tasks often involve multiple steps, which introduces new challenges.
For multi-step tasks, the prompts are likely to be more complex and extensive, making it harder for the LLMs to analyze where things are going wrong. It's also difficult to evaluate the impact of each individual step in the process. Additionally, different people may have different preferences for how the task should be executed.
To address these challenges, the researchers developed a new system called PROMST. PROMST uses the LLM to automatically analyze the prompts and provide suggestions for how to improve them. It also includes a separate machine learning model that helps predict how well a prompt will perform, which allows the system to efficiently try out different prompt variations.
Compared to both human-designed prompts and other prompt optimization methods, PROMST significantly improves the performance on a wide range of multi-step tasks. This research could serve as an important benchmark for developing better ways to optimize prompts for complex, real-world applications of LLMs.
Technical Explanation
The paper introduces a new LLM-driven discrete prompt optimization framework called PROMST that addresses the challenges of optimizing prompts for multi-step tasks.
PROMST incorporates human-designed feedback rules to automatically provide direct suggestions for improving prompts. It also uses an extra learned heuristic model that predicts prompt performance to efficiently sample from prompt candidates.
The researchers evaluate PROMST across 11 representative multi-step tasks and find that it significantly outperforms both human-engineered prompts and several other prompt optimization methods, including language model prompt selection via simulation optimization, PromptWizard, prompt optimization with human feedback, task facet learning, and optimizing instructions and demonstrations for multi-stage language models.
The average improvements range from 10.6% to 29.3% compared to the current best methods on five different LLMs. The researchers believe this work can serve as a valuable benchmark for automatic prompt optimization for LLM-driven multi-step tasks.
Critical Analysis
The paper presents a promising approach to addressing the challenge of prompt optimization for complex, multi-step tasks. However, there are a few potential limitations and areas for further research:
-
The paper does not provide much detail on the specific human-designed feedback rules used in PROMST. More information on the development and evaluation of these rules would be helpful.
-
The performance of PROMST is evaluated on a relatively small set of 11 tasks. It would be valuable to see how it generalizes to a wider range of multi-step scenarios, including real-world applications.
-
The paper does not discuss the computational cost and time required for the prompt optimization process. Understanding the tradeoffs between performance gains and efficiency would be important for practical deployment.
-
While PROMST outperforms other prompt optimization methods, it is not clear how much of an improvement it offers over simply having humans design the prompts. Further research could explore the specific types of tasks and scenarios where the automated approach provides the most value.
Overall, this research represents an important step forward in addressing the challenges of prompt optimization for complex, multi-step tasks using large language models. Continued work in this area could lead to significant advancements in the practical application of these powerful AI systems.
Conclusion
This research paper introduces a new LLM-driven prompt optimization framework called PROMST that addresses the challenges of optimizing prompts for multi-step tasks. PROMST incorporates human-designed feedback rules and a learned heuristic model to efficiently suggest prompt improvements.
The authors demonstrate that PROMST significantly outperforms both human-engineered prompts and other prompt optimization methods across a range of multi-step tasks. This work can serve as an important benchmark for developing better ways to optimize prompts for complex, real-world applications of large language models.
While the paper presents a promising approach, there are still some areas for further research, such as exploring the generalization of the method to a wider range of tasks and understanding the computational tradeoffs. Overall, this research represents an important step forward in addressing a key challenge in the practical application of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
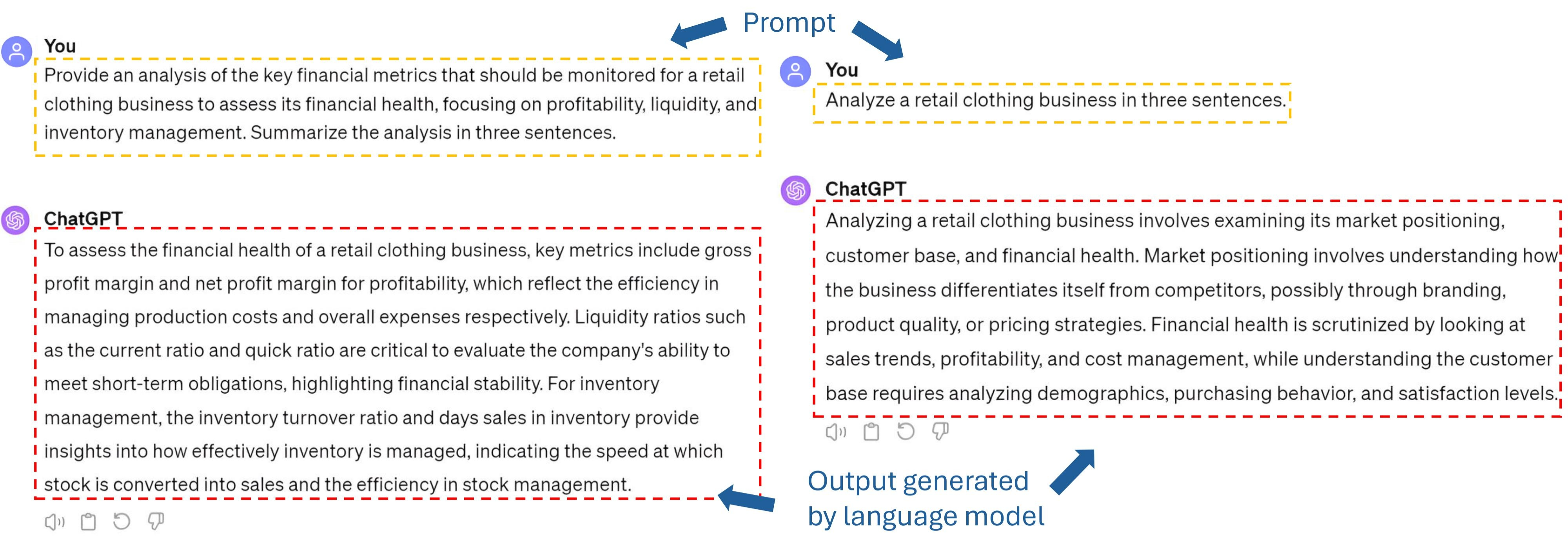
Language Model Prompt Selection via Simulation Optimization
Haoting Zhang, Jinghai He, Rhonda Righter, Zeyu Zheng
0
0
With the advancement in generative language models, the selection of prompts has gained significant attention in recent years. A prompt is an instruction or description provided by the user, serving as a guide for the generative language model in content generation. Despite existing methods for prompt selection that are based on human labor, we consider facilitating this selection through simulation optimization, aiming to maximize a pre-defined score for the selected prompt. Specifically, we propose a two-stage framework. In the first stage, we determine a feasible set of prompts in sufficient numbers, where each prompt is represented by a moderate-dimensional vector. In the subsequent stage for evaluation and selection, we construct a surrogate model of the score regarding the moderate-dimensional vectors that represent the prompts. We propose sequentially selecting the prompt for evaluation based on this constructed surrogate model. We prove the consistency of the sequential evaluation procedure in our framework. We also conduct numerical experiments to demonstrate the efficacy of our proposed framework, providing practical instructions for implementation.
5/21/2024
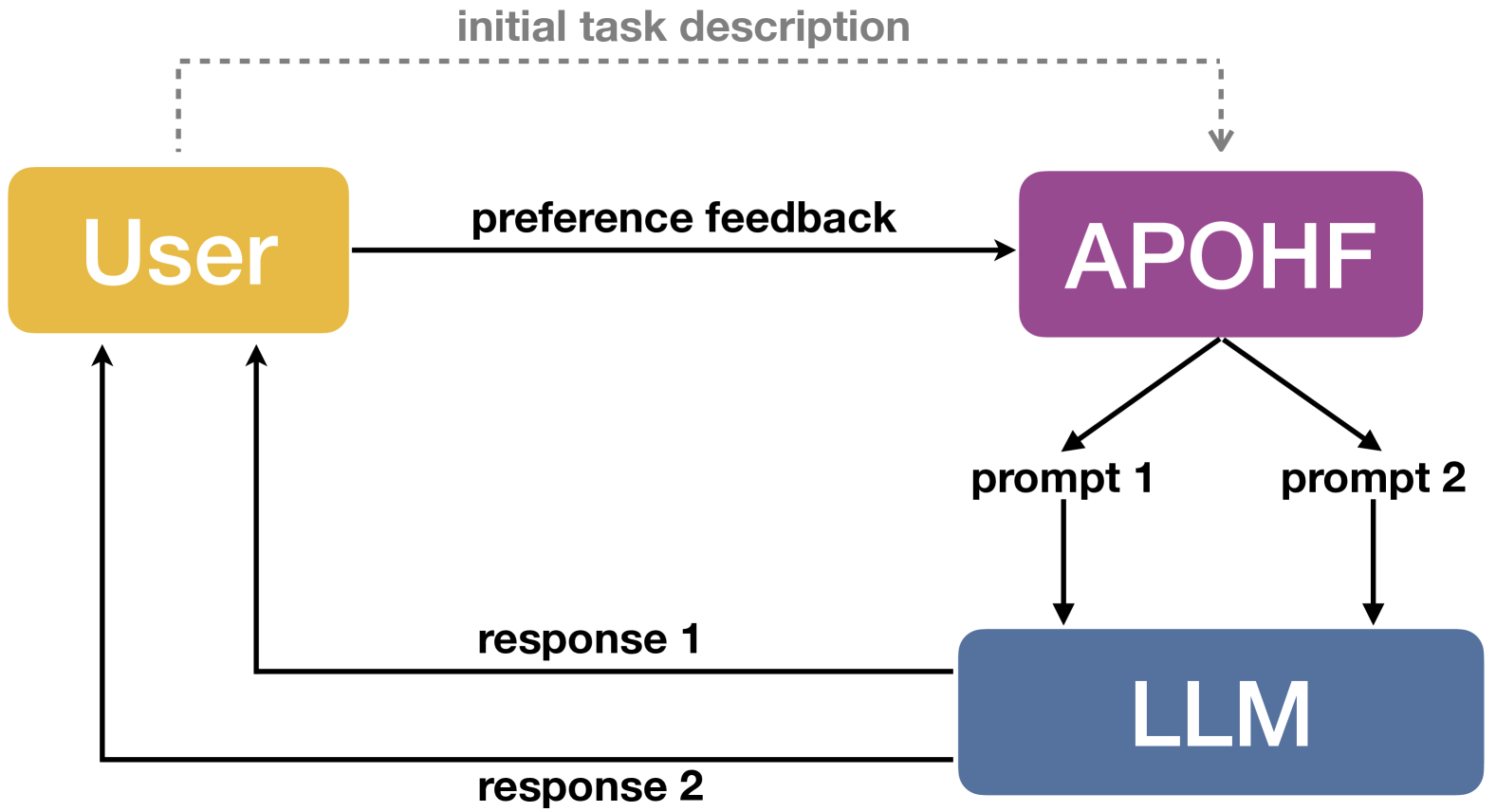
Prompt Optimization with Human Feedback
Xiaoqiang Lin, Zhongxiang Dai, Arun Verma, See-Kiong Ng, Patrick Jaillet, Bryan Kian Hsiang Low
0
0
Large language models (LLMs) have demonstrated remarkable performances in various tasks. However, the performance of LLMs heavily depends on the input prompt, which has given rise to a number of recent works on prompt optimization. However, previous works often require the availability of a numeric score to assess the quality of every prompt. Unfortunately, when a human user interacts with a black-box LLM, attaining such a score is often infeasible and unreliable. Instead, it is usually significantly easier and more reliable to obtain preference feedback from a human user, i.e., showing the user the responses generated from a pair of prompts and asking the user which one is preferred. Therefore, in this paper, we study the problem of prompt optimization with human feedback (POHF), in which we aim to optimize the prompt for a black-box LLM using only human preference feedback. Drawing inspiration from dueling bandits, we design a theoretically principled strategy to select a pair of prompts to query for preference feedback in every iteration, and hence introduce our algorithm named automated POHF (APOHF). We apply our APOHF algorithm to various tasks, including optimizing user instructions, prompt optimization for text-to-image generative models, and response optimization with human feedback (i.e., further refining the response using a variant of our APOHF). The results demonstrate that our APOHF can efficiently find a good prompt using a small number of preference feedback instances. Our code can be found at url{https://github.com/xqlin98/APOHF}.
5/28/2024
🛠️
PromptWizard: Task-Aware Agent-driven Prompt Optimization Framework
Eshaan Agarwal, Vivek Dani, Tanuja Ganu, Akshay Nambi
0
0
Large language models (LLMs) have revolutionized AI across diverse domains, showcasing remarkable capabilities. Central to their success is the concept of prompting, which guides model output generation. However, manual prompt engineering is labor-intensive and domain-specific, necessitating automated solutions. This paper introduces PromptWizard, a novel framework leveraging LLMs to iteratively synthesize and refine prompts tailored to specific tasks. Unlike existing approaches, PromptWizard optimizes both prompt instructions and in-context examples, maximizing model performance. The framework iteratively refines prompts by mutating instructions and incorporating negative examples to deepen understanding and ensure diversity. It further enhances both instructions and examples with the aid of a critic, synthesizing new instructions and examples enriched with detailed reasoning steps for optimal performance. PromptWizard offers several key features and capabilities, including computational efficiency compared to state-of-the-art approaches, adaptability to scenarios with varying amounts of training data, and effectiveness with smaller LLMs. Rigorous evaluation across 35 tasks on 8 datasets demonstrates PromptWizard's superiority over existing prompt strategies, showcasing its efficacy and scalability in prompt optimization.
5/29/2024
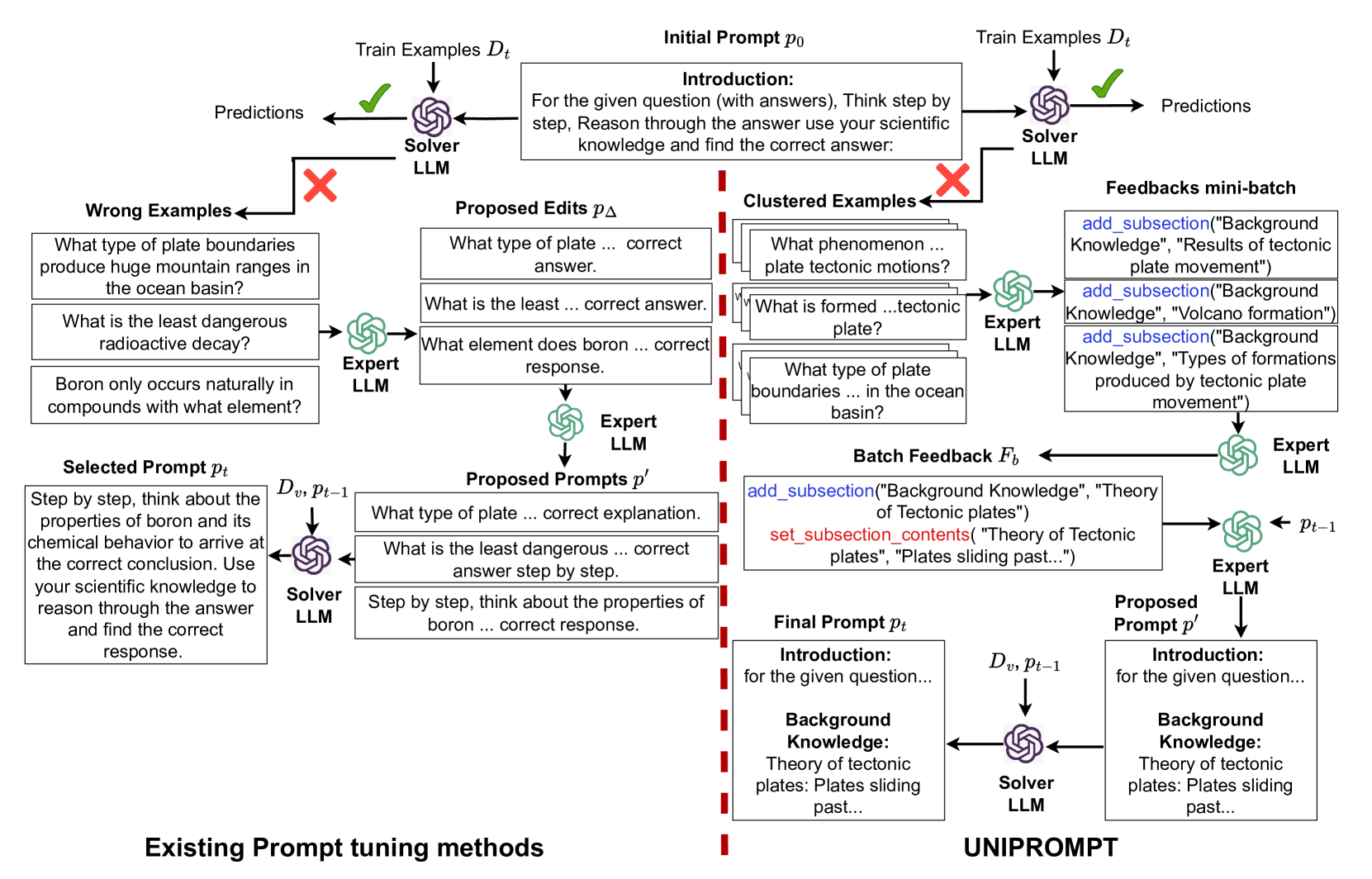
Task Facet Learning: A Structured Approach to Prompt Optimization
Gurusha Juneja, Nagarajan Natarajan, Hua Li, Jian Jiao, Amit Sharma
0
0
Given a task in the form of a basic description and its training examples, prompt optimization is the problem of synthesizing the given information into a text prompt for a large language model (LLM). Humans solve this problem by also considering the different facets that define a task (e.g., counter-examples, explanations, analogies) and including them in the prompt. However, it is unclear whether existing algorithmic approaches, based on iteratively editing a given prompt or automatically selecting a few in-context examples, can cover the multiple facets required to solve a complex task. In this work, we view prompt optimization as that of learning multiple facets of a task from a set of training examples. We identify and exploit structure in the prompt optimization problem -- first, we find that prompts can be broken down into loosely coupled semantic sections that have a relatively independent effect on the prompt's performance; second, we cluster the input space and use clustered batches so that the optimization procedure can learn the different facets of a task across batches. The resulting algorithm, UniPrompt, consists of a generative model to generate initial candidates for each prompt section; and a feedback mechanism that aggregates suggested edits from multiple mini-batches into a conceptual description for the section. Empirical evaluation on multiple datasets and a real-world task shows that prompts generated using UniPrompt obtain higher accuracy than human-tuned prompts and those from state-of-the-art methods. In particular, our algorithm can generate long, complex prompts that existing methods are unable to generate. Code for UniPrompt will be available at url{https://aka.ms/uniprompt}.
6/18/2024