Revisiting OPRO: The Limitations of Small-Scale LLMs as Optimizers
2405.10276
0
0

Abstract
Numerous recent works aim to enhance the efficacy of Large Language Models (LLMs) through strategic prompting. In particular, the Optimization by PROmpting (OPRO) approach provides state-of-the-art performance by leveraging LLMs as optimizers where the optimization task is to find instructions that maximize the task accuracy. In this paper, we revisit OPRO for automated prompting with relatively small-scale LLMs, such as LLaMa-2 family and Mistral 7B. Our investigation reveals that OPRO shows limited effectiveness in small-scale LLMs, with limited inference capabilities constraining optimization ability. We suggest future automatic prompting engineering to consider both model capabilities and computational costs. Additionally, for small-scale LLMs, we recommend direct instructions that clearly outline objectives and methodologies as robust prompt baselines, ensuring efficient and effective prompt engineering in ongoing research.
Create account to get full access
Overview
- This paper explores the limitations of using small-scale large language models (LLMs) as optimizers for complex tasks.
- The authors conduct a motivational study to investigate whether the LLaMa 13B model can effectively solve a linear regression problem.
- The paper then delves into a broader analysis of the challenges and shortcomings of employing small-scale LLMs as general-purpose optimizers.
Plain English Explanation
The paper examines the ability of smaller, less powerful language models to act as optimizers - tools that can find the best solutions to complex problems. The researchers start by testing whether the LLaMa 13B model, a moderately-sized language model, can solve a basic linear regression task. Linear regression is a relatively simple optimization problem, so if the model struggles with it, the authors argue that it is likely to have even more difficulty with more complex optimization tasks.
The paper then goes on to discuss the broader limitations of using small-scale language models as general-purpose optimizers. While large, powerful language models like GPT-3 have shown some promise in this area, the authors suggest that smaller models may not have the necessary capabilities to effectively tackle challenging optimization problems. The paper aims to provide a realistic assessment of the current state of language models as optimizers and caution against over-relying on these models for complex real-world optimization tasks.
Technical Explanation
The paper begins with a motivational study to investigate whether the LLaMa 13B model, a relatively small-scale LLM, can effectively solve a linear regression problem. Linear regression is a relatively simple optimization task, so if the model struggles with it, the authors argue that it is likely to have even more difficulty with more complex black-box optimization problems.
The authors then delve into a broader analysis of the limitations of using small-scale LLMs as general-purpose optimizers. They discuss how the capabilities of language models as optimizers may be constrained by factors such as model size, training data, and the inherent differences between language modeling and optimization tasks. The paper also explores potential strategies for adapting LLMs to be more effective as optimizers, such as fine-tuning or incorporating specialized optimization modules.
Critical Analysis
The paper provides a valuable and nuanced perspective on the limitations of using small-scale LLMs as optimizers. The authors are careful to acknowledge that larger, more powerful language models may indeed have greater potential in this area, while also cautioning against overstating the capabilities of smaller models.
One potential limitation of the research is that it focuses solely on the LLaMa 13B model, which may not be representative of all small-scale LLMs. It would be interesting to see the authors expand their analysis to include a broader range of models and optimization tasks to further validate their findings.
Additionally, the paper does not delve deeply into the specific reasons why small-scale LLMs may struggle as optimizers. A more detailed exploration of the architectural and algorithmic factors that contribute to these limitations could help inform future research and development in this area.
Conclusion
This paper offers a timely and important perspective on the current limitations of using small-scale LLMs as general-purpose optimizers. The authors' findings suggest that while large, powerful language models may show promise in this area, smaller models are unlikely to be effective substitutes for specialized optimization algorithms and techniques.
The research highlights the need for a more nuanced and realistic understanding of the capabilities and limitations of language models when it comes to complex optimization tasks. As the field of AI continues to evolve, it will be crucial for researchers and practitioners to carefully assess the strengths and weaknesses of different approaches and to deploy them in a responsible and well-informed manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models as Optimizers
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V. Le, Denny Zhou, Xinyun Chen
0
0
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to our main application in prompt optimization, where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks. Code at https://github.com/google-deepmind/opro.
4/16/2024
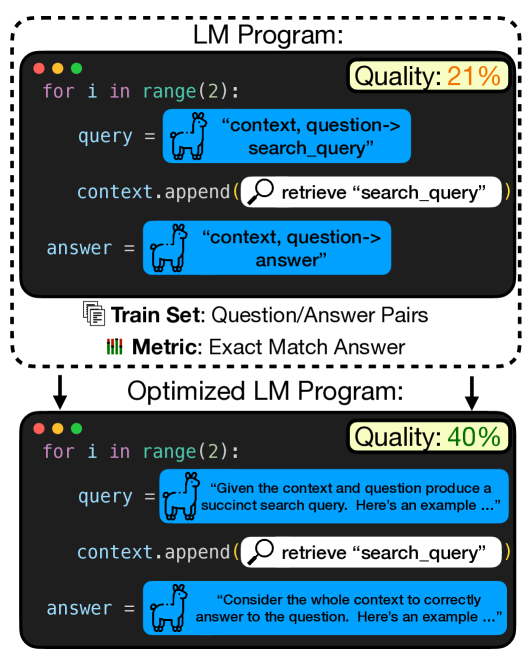
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, Omar Khattab
0
0
Language Model Programs, i.e. sophisticated pipelines of modular language model (LM) calls, are increasingly advancing NLP tasks, but they require crafting prompts that are jointly effective for all modules. We study prompt optimization for LM programs, i.e. how to update these prompts to maximize a downstream metric without access to module-level labels or gradients. To make this tractable, we factorize our problem into optimizing the free-form instructions and few-shot demonstrations of every module and introduce several strategies to craft task-grounded instructions and navigate credit assignment across modules. Our strategies include (i) program- and data-aware techniques for proposing effective instructions, (ii) a stochastic mini-batch evaluation function for learning a surrogate model of our objective, and (iii) a meta-optimization procedure in which we refine how LMs construct proposals over time. Using these insights we develop MIPRO, a novel optimizer that outperforms baselines on five of six diverse LM programs using a best-in-class open-source model (Llama-3-8B), by as high as 12.9% accuracy. We will release our new optimizers and benchmark in DSPy at https://github.com/stanfordnlp/dspy
6/18/2024

Towards Optimizing with Large Language Models
Pei-Fu Guo, Ying-Hsuan Chen, Yun-Da Tsai, Shou-De Lin
0
0
In this work, we conduct an assessment of the optimization capabilities of LLMs across various tasks and data sizes. Each of these tasks corresponds to unique optimization domains, and LLMs are required to execute these tasks with interactive prompting. That is, in each optimization step, the LLM generates new solutions from the past generated solutions with their values, and then the new solutions are evaluated and considered in the next optimization step. Additionally, we introduce three distinct metrics for a comprehensive assessment of task performance from various perspectives. These metrics offer the advantage of being applicable for evaluating LLM performance across a broad spectrum of optimization tasks and are less sensitive to variations in test samples. By applying these metrics, we observe that LLMs exhibit strong optimization capabilities when dealing with small-sized samples. However, their performance is significantly influenced by factors like data size and values, underscoring the importance of further research in the domain of optimization tasks for LLMs.
5/28/2024
Unveiling the Lexical Sensitivity of LLMs: Combinatorial Optimization for Prompt Enhancement
Pengwei Zhan, Zhen Xu, Qian Tan, Jie Song, Ru Xie
0
0
Large language models (LLMs) demonstrate exceptional instruct-following ability to complete various downstream tasks. Although this impressive ability makes LLMs flexible task solvers, their performance in solving tasks also heavily relies on instructions. In this paper, we reveal that LLMs are over-sensitive to lexical variations in task instructions, even when the variations are imperceptible to humans. By providing models with neighborhood instructions, which are closely situated in the latent representation space and differ by only one semantically similar word, the performance on downstream tasks can be vastly different. Following this property, we propose a black-box Combinatorial Optimization framework for Prompt Lexical Enhancement (COPLE). COPLE performs iterative lexical optimization according to the feedback from a batch of proxy tasks, using a search strategy related to word influence. Experiments show that even widely-used human-crafted prompts for current benchmarks suffer from the lexical sensitivity of models, and COPLE recovers the declined model ability in both instruct-following and solving downstream tasks.
6/3/2024