Optimizing Large Language Models for OpenAPI Code Completion
2405.15729
0
0

Abstract
Recent advancements in Large Language Models (LLMs) and their utilization in code generation tasks have significantly reshaped the field of software development. Despite the remarkable efficacy of code completion solutions in mainstream programming languages, their performance lags when applied to less ubiquitous formats such as OpenAPI definitions. This study evaluates the OpenAPI completion performance of GitHub Copilot, a prevalent commercial code completion tool, and proposes a set of task-specific optimizations leveraging Meta's open-source model Code Llama. A semantics-aware OpenAPI completion benchmark proposed in this research is used to perform a series of experiments through which the impact of various prompt-engineering and fine-tuning techniques on the Code Llama model's performance is analyzed. The fine-tuned Code Llama model reaches a peak correctness improvement of 55.2% over GitHub Copilot despite utilizing 25 times fewer parameters than the commercial solution's underlying Codex model. Additionally, this research proposes an enhancement to a widely used code infilling training technique, addressing the issue of underperformance when the model is prompted with context sizes smaller than those used during training. The dataset, the benchmark, and the model fine-tuning code are made publicly available.
Create account to get full access
Introduction
This paper explores techniques for optimizing large language models (LLMs) like Code Llama and GitHub Copilot for the task of OpenAPI code completion. OpenAPI is a popular standard for defining and describing RESTful APIs, and LLMs have shown promise in assisting developers with code generation and completion tasks. The researchers investigate fine-tuning and prompt engineering approaches to improve the performance of LLMs on this specific use case.
Plain English Explanation
The paper focuses on making large language models, which are powerful AI systems trained on vast amounts of data, better at helping developers write code for OpenAPI, a standard way of describing web-based APIs. OpenAPI is an important tool for building software that interacts with online services, and the researchers wanted to see if they could improve how well language models perform this specific task.
They tested different techniques, like fine-tuning the models (further training them on OpenAPI-related data) and carefully crafting the prompts (instructions) given to the models, to see if that would make the models better at generating accurate and useful OpenAPI code. The goal was to make the language models more effective at assisting developers with this important programming task.
Technical Explanation
The paper begins by outlining the state of the art in large language models for code generation and completion, citing relevant research such as CodeEditorBench and Learning Performance Improving Code Edits. It then describes the specific challenges of OpenAPI code completion, noting that existing models may struggle with the domain-specific terminology and syntax.
The researchers experiment with two main approaches to address this:
- Fine-tuning: Further training the base language models on a dataset of OpenAPI specifications and related code to adapt them to this domain.
- Prompt engineering: Carefully designing the input prompts given to the models to elicit more relevant and accurate OpenAPI code completions.
The paper details the datasets, model architectures, and evaluation metrics used in their experiments. Key findings include the effectiveness of fine-tuning for improving performance on OpenAPI-specific benchmarks, as well as the importance of prompt engineering to guide the models towards generating high-quality OpenAPI code.
Critical Analysis
The paper provides a thorough and well-designed study of optimizing LLMs for OpenAPI code completion. However, the researchers acknowledge that their work is limited to a specific set of models and datasets, and that further research is needed to generalize the findings.
One potential limitation is the reliance on automated metrics for evaluating the generated code, as these may not fully capture the nuances of real-world usability. Additionally, the paper does not explore the potential biases or safety considerations that could arise from deploying such AI-powered code completion tools in production environments.
Nonetheless, the researchers have made a valuable contribution to the field of LLM-based code generation and completion. Their work highlights the importance of domain-specific optimization and the role of prompt engineering, which could inform future efforts to make these powerful AI systems more useful and reliable for software development tasks.
Conclusion
This paper presents a promising approach to optimizing large language models for the task of OpenAPI code completion. By fine-tuning the models on relevant data and carefully crafting the input prompts, the researchers were able to significantly improve the quality and accuracy of the generated code.
The findings have important implications for the broader field of AI-assisted software development, where language models are increasingly being leveraged to enhance programmer productivity and reduce development time. As these technologies continue to evolve, it will be crucial to ensure they are tailored to the specific needs and best practices of different programming domains, as demonstrated in this work on OpenAPI.
Overall, the research highlights the value of domain-specific optimization and the potential for language models to become valuable tools in the software engineer's toolkit, as long as they are developed and deployed with care and consideration for the unique challenges of each application area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Should AI Optimize Your Code? A Comparative Study of Current Large Language Models Versus Classical Optimizing Compilers
Miguel Romero Rosas, Miguel Torres Sanchez, Rudolf Eigenmann
0
0
In the contemporary landscape of computer architecture, the demand for efficient parallel programming persists, needing robust optimization techniques. Traditional optimizing compilers have historically been pivotal in this endeavor, adapting to the evolving complexities of modern software systems. The emergence of Large Language Models (LLMs) raises intriguing questions about the potential for AI-driven approaches to revolutionize code optimization methodologies. This paper presents a comparative analysis between two state-of-the-art Large Language Models, GPT-4.0 and CodeLlama-70B, and traditional optimizing compilers, assessing their respective abilities and limitations in optimizing code for maximum efficiency. Additionally, we introduce a benchmark suite of challenging optimization patterns and an automatic mechanism for evaluating performance and correctness of the code generated by such tools. We used two different prompting methodologies to assess the performance of the LLMs -- Chain of Thought (CoT) and Instruction Prompting (IP). We then compared these results with three traditional optimizing compilers, CETUS, PLUTO and ROSE, across a range of real-world use cases. A key finding is that while LLMs have the potential to outperform current optimizing compilers, they often generate incorrect code on large code sizes, calling for automated verification methods. Our extensive evaluation across 3 different benchmarks suites shows CodeLlama-70B as the superior optimizer among the two LLMs, capable of achieving speedups of up to 2.1x. Additionally, CETUS is the best among the optimizing compilers, achieving a maximum speedup of 1.9x. We also found no significant difference between the two prompting methods: Chain of Thought (Cot) and Instructing prompting (IP).
6/19/2024
💬
New!Leveraging Large Language Models for Software Model Completion: Results from Industrial and Public Datasets
Christof Tinnes, Alisa Welter, Sven Apel
0
0
Modeling structure and behavior of software systems plays a crucial role in the industrial practice of software engineering. As with other software engineering artifacts, software models are subject to evolution. Supporting modelers in evolving software models with recommendations for model completions is still an open problem, though. In this paper, we explore the potential of large language models for this task. In particular, we propose an approach, retrieval-augmented generation, leveraging large language models, model histories, and retrieval-augmented generation for model completion. Through experiments on three datasets, including an industrial application, one public open-source community dataset, and one controlled collection of simulated model repositories, we evaluate the potential of large language models for model completion with retrieval-augmented generation. We found that large language models are indeed a promising technology for supporting software model evolution (62.30% semantically correct completions on real-world industrial data and up to 86.19% type-correct completions). The general inference capabilities of large language models are particularly useful when dealing with concepts for which there are few, noisy, or no examples at all.
6/28/2024

A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, Sunghun Kim
0
0
Large Language Models (LLMs) have garnered remarkable advancements across diverse code-related tasks, known as Code LLMs, particularly in code generation that generates source code with LLM from natural language descriptions. This burgeoning field has captured significant interest from both academic researchers and industry professionals due to its practical significance in software development, e.g., GitHub Copilot. Despite the active exploration of LLMs for a variety of code tasks, either from the perspective of natural language processing (NLP) or software engineering (SE) or both, there is a noticeable absence of a comprehensive and up-to-date literature review dedicated to LLM for code generation. In this survey, we aim to bridge this gap by providing a systematic literature review that serves as a valuable reference for researchers investigating the cutting-edge progress in LLMs for code generation. We introduce a taxonomy to categorize and discuss the recent developments in LLMs for code generation, covering aspects such as data curation, latest advances, performance evaluation, and real-world applications. In addition, we present a historical overview of the evolution of LLMs for code generation and offer an empirical comparison using the widely recognized HumanEval and MBPP benchmarks to highlight the progressive enhancements in LLM capabilities for code generation. We identify critical challenges and promising opportunities regarding the gap between academia and practical development. Furthermore, we have established a dedicated resource website (https://codellm.github.io) to continuously document and disseminate the most recent advances in the field.
6/4/2024
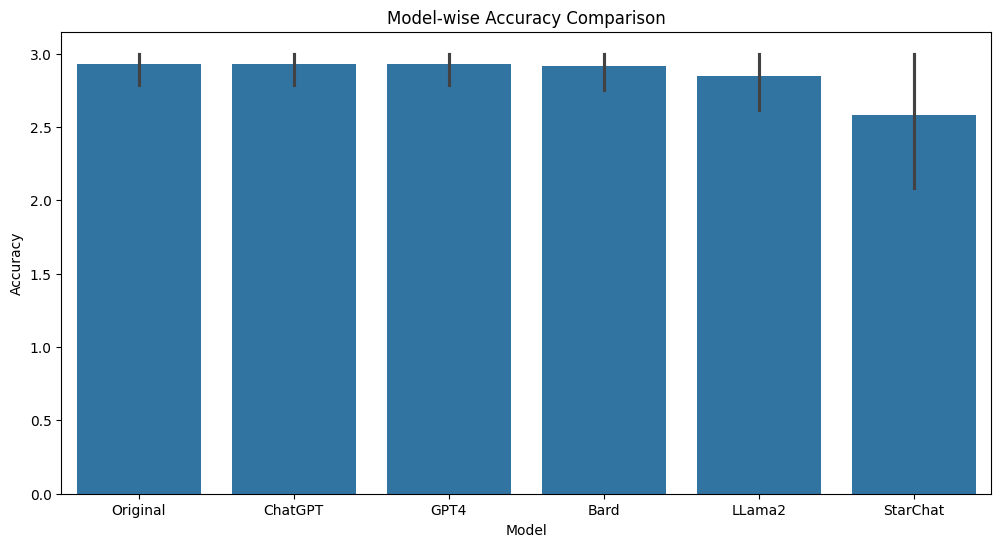
A Comparative Analysis of Large Language Models for Code Documentation Generation
Shubhang Shekhar Dvivedi, Vyshnav Vijay, Sai Leela Rahul Pujari, Shoumik Lodh, Dhruv Kumar
0
0
This paper presents a comprehensive comparative analysis of Large Language Models (LLMs) for generation of code documentation. Code documentation is an essential part of the software writing process. The paper evaluates models such as GPT-3.5, GPT-4, Bard, Llama2, and Starchat on various parameters like Accuracy, Completeness, Relevance, Understandability, Readability and Time Taken for different levels of code documentation. Our evaluation employs a checklist-based system to minimize subjectivity, providing a more objective assessment. We find that, barring Starchat, all LLMs consistently outperform the original documentation. Notably, closed-source models GPT-3.5, GPT-4, and Bard exhibit superior performance across various parameters compared to open-source/source-available LLMs, namely LLama 2 and StarChat. Considering the time taken for generation, GPT-4 demonstrated the longest duration, followed by Llama2, Bard, with ChatGPT and Starchat having comparable generation times. Additionally, file level documentation had a considerably worse performance across all parameters (except for time taken) as compared to inline and function level documentation.
4/30/2024