Optimizing and Testing Instruction-Following: Analyzing the Impact of Fine-Grained Instruction Variants on instruction-tuned LLMs
2406.11301
0
0

Abstract
The effective alignment of Large Language Models (LLMs) with precise instructions is essential for their application in diverse real-world scenarios. Current methods focus on enhancing the diversity and complexity of training and evaluation samples, yet they fall short in accurately assessing LLMs' ability to follow similar instruction variants. We introduce an effective data augmentation technique that decomposes complex instructions into simpler sub-components, modifies these, and reconstructs them into new variants, thereby preserves the original instruction's context and complexity while introducing variability, which is critical for training and evaluating LLMs' instruction-following precision. We developed the DeMoRecon dataset using this method to both fine-tune and evaluate LLMs. Our findings show that LLMs fine-tuned with DeMoRecon will gain significant performance boost on both ours and commonly used instructions-following benchmarks.
Create account to get full access
Overview
- This paper explores ways to enhance and assess the ability of language models to follow instructions.
- The researchers developed a diverse set of fine-grained instruction variants to better evaluate and improve instruction-following capabilities.
- They used these instruction variants to assess several large language models, identifying strengths and weaknesses in their ability to understand and execute instructions.
- The findings provide insights into the current state of instruction-following in language models and suggest directions for future research and development.
Plain English Explanation
The paper focuses on how well language models, like the ones used in chatbots and virtual assistants, can understand and follow instructions. The researchers created a wide variety of slightly different instructions, rather than just using a single set of instructions. This allowed them to more thoroughly test the models' abilities.
By assessing several popular language models using these diverse instructions, the researchers were able to identify areas where the models excel at following instructions, as well as areas where they struggle. This provides valuable insights into the current capabilities and limitations of these models when it comes to understanding and carrying out instructions.
The findings from this research can help guide future efforts to improve instruction-following in language models, ultimately leading to more capable and trustworthy AI assistants that can better understand and execute the instructions we give them. Link to Towards Robust Instruction Tuning with Multimodal Large Language Models
Technical Explanation
The researchers developed a diverse set of fine-grained instruction variants to evaluate and enhance the instruction-following capabilities of language models. They used these instruction variants to assess several large language models, including GPT-3, T0, and Chinchilla, identifying strengths and weaknesses in their ability to understand and execute instructions.
The instruction variants were designed to test different aspects of instruction-following, such as following multi-step instructions, handling ambiguity, and dealing with contradictory or incomplete information. By using a wide range of instruction variants, the researchers were able to gain a more comprehensive understanding of the models' capabilities.
The assessment revealed that while the language models performed reasonably well on many instruction-following tasks, they struggled with certain types of instructions, such as those involving reasoning, commonsense understanding, or tasks that required fine-grained control. The findings suggest that current language models still have limitations when it comes to truly understanding and following instructions in a robust and reliable manner.
The insights from this research can inform the development of instruction-tuning approaches and the design of more comprehensive instruction-following benchmarks, ultimately leading to more capable and trustworthy AI assistants that can better understand and execute the instructions we give them.
Critical Analysis
The researchers provide a thorough and rigorous assessment of instruction-following capabilities in large language models, but there are a few potential limitations to consider:
-
The instruction variants, while diverse, may not capture the full breadth of real-world instructions that users might give to AI assistants. Further research could explore instruction sets that more closely mirror natural language instructions.
-
The study only assessed a limited number of language models, and it's possible that other models not included in the analysis may have different strengths and weaknesses when it comes to instruction-following. Expanding the model selection could provide a more comprehensive understanding.
-
The researchers did not explore the potential of combining language models with other AI components, such as multimodal perception or reasoning capabilities, which could enhance instruction-following performance.
Overall, this research is a valuable contribution to the field, highlighting the need for continued progress in developing language models that can reliably understand and execute instructions. Further advancements in this area could lead to more capable and trustworthy AI assistants that can better support users in a wide range of tasks and applications.
Conclusion
This paper presents a novel approach to enhancing and assessing the instruction-following capabilities of large language models. By developing a diverse set of fine-grained instruction variants, the researchers were able to gain deeper insights into the strengths and limitations of several state-of-the-art language models.
The findings from this study suggest that while current language models can perform reasonably well on many instruction-following tasks, they still struggle with certain types of instructions that require more advanced reasoning, commonsense understanding, or fine-grained control. These insights can inform future research and development efforts aimed at improving instruction-following in language models, ultimately leading to more capable and trustworthy AI assistants that can better support users in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
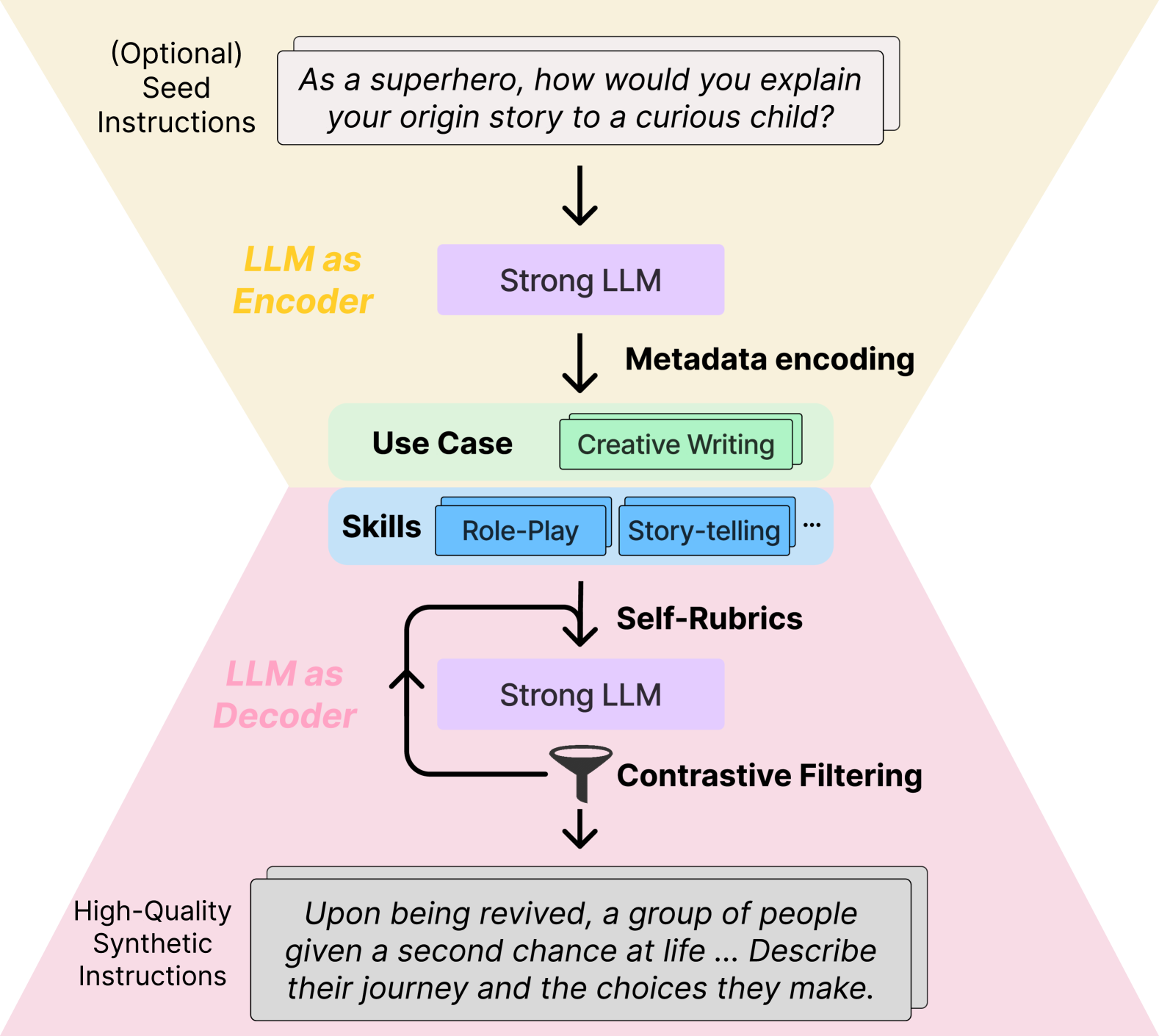
CodecLM: Aligning Language Models with Tailored Synthetic Data
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
0
0
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
4/10/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024
💬
From Complex to Simple: Enhancing Multi-Constraint Complex Instruction Following Ability of Large Language Models
Qianyu He, Jie Zeng, Qianxi He, Jiaqing Liang, Yanghua Xiao
0
0
It is imperative for Large language models (LLMs) to follow instructions with elaborate requirements (i.e. Complex Instructions Following). Yet, it remains under-explored how to enhance the ability of LLMs to follow complex instructions with multiple constraints. To bridge the gap, we initially study what training data is effective in enhancing complex constraints following abilities. We found that training LLMs with instructions containing multiple constraints enhances their understanding of complex instructions, especially those with lower complexity levels. The improvement can even generalize to compositions of out-of-domain constraints. Additionally, we further propose methods addressing how to obtain and utilize the effective training data. Finally, we conduct extensive experiments to prove the effectiveness of our methods in terms of overall performance and training efficiency. We also demonstrate that our methods improve models' ability to follow instructions generally and generalize effectively across out-of-domain, in-domain, and adversarial settings, while maintaining general capabilities.
6/19/2024
✅
Instruction Tuning With Loss Over Instructions
Zhengyan Shi, Adam X. Yang, Bin Wu, Laurence Aitchison, Emine Yilmaz, Aldo Lipani
0
0
Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.
5/24/2024