OU-CoViT: Copula-Enhanced Bi-Channel Multi-Task Vision Transformers with Dual Adaptation for OU-UWF Images

0
Sign in to get full access
Overview
- OU-CoViT is a deep learning model for computer vision tasks on OU-UWF images
- It uses a bi-channel multi-task vision transformer architecture with dual adaptation
- The model leverages copula theory to enhance feature representation
Plain English Explanation
The OU-CoViT model is designed to tackle computer vision tasks on a specific type of image data called OU-UWF images. These images likely have some unique or challenging properties that require a specialized approach.
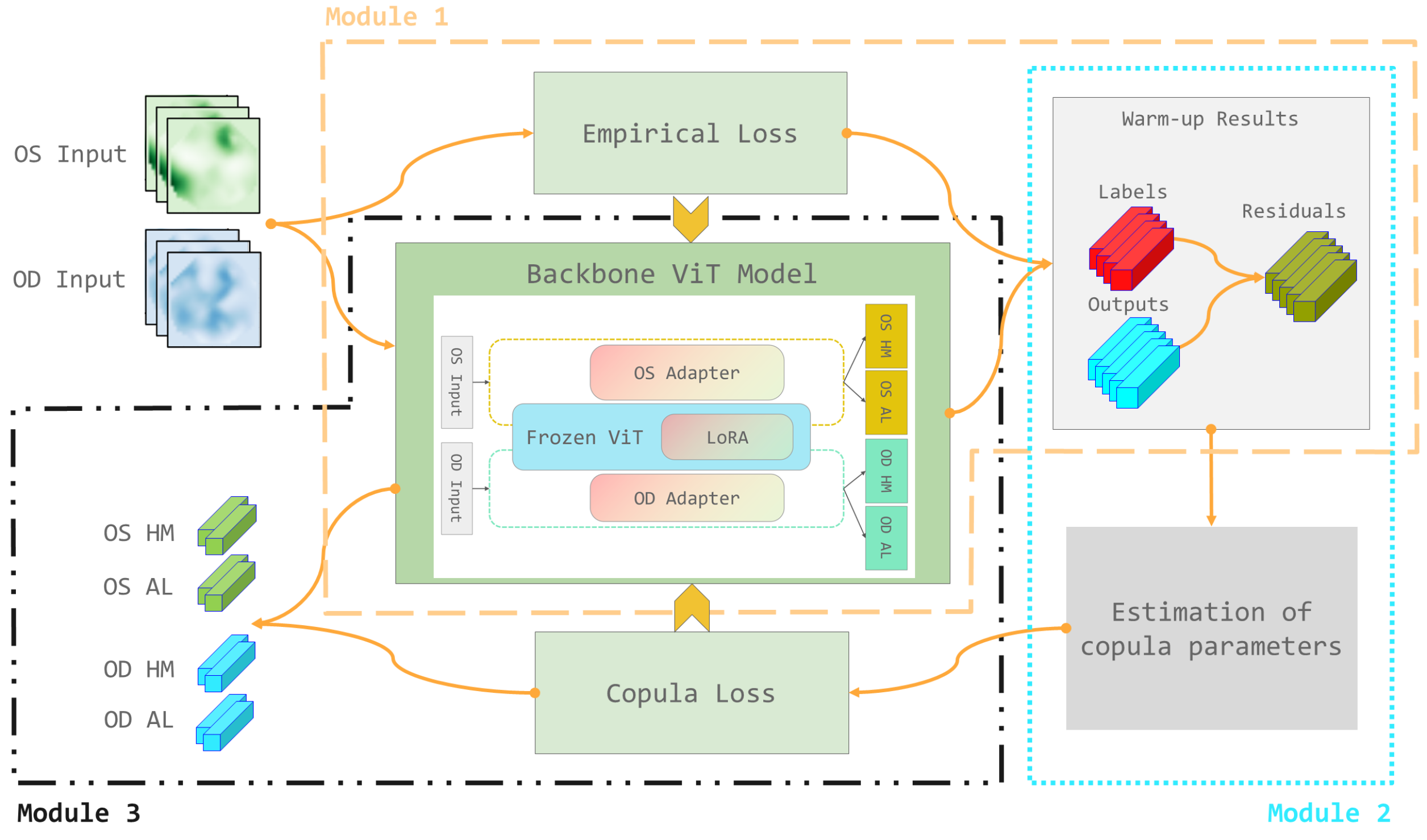
To address this, the researchers developed a bi-channel multi-task vision transformer architecture. This means the model takes in the image through two separate "channels" or pathways, and is trained on multiple related computer vision tasks at the same time.
A key innovation in OU-CoViT is the use of copula theory to enhance the model's feature representation. Copula theory is a mathematical framework for modeling the dependencies between random variables. By incorporating this, the researchers aimed to improve the model's ability to capture the unique characteristics of the OU-UWF images.
Additionally, the model includes "dual adaptation" mechanisms, which likely refer to techniques for adapting the model to perform well on the OU-UWF data, such as transfer learning or domain adaptation.
Overall, the OU-CoViT model appears to be a specialized deep learning approach developed to tackle computer vision challenges in the context of OU-UWF images, leveraging novel architectural and mathematical components to enhance performance.
Technical Explanation
The OU-CoViT model is based on a bi-channel multi-task vision transformer architecture. This means the input image is processed through two separate transformer-based pathways, and the model is trained to perform multiple related computer vision tasks simultaneously.
A key innovation is the incorporation of copula theory to enhance the feature representation. Copula functions are used to model the dependencies between random variables, which the researchers hypothesize can better capture the unique characteristics of the OU-UWF image data.
The model also includes "dual adaptation" mechanisms, which likely refer to techniques such as transfer learning or domain adaptation to fine-tune the model for the OU-UWF dataset. This allows the model to better generalize and perform well on the target data, beyond what a generic vision transformer would be capable of.
Critical Analysis
The paper does not provide many details on the specific challenges or properties of the OU-UWF image data that motivated the development of this specialized model. More context on the dataset and task requirements would be helpful to fully evaluate the contributions of the OU-CoViT approach.
Additionally, the authors do not discuss the potential limitations or caveats of using copula theory for feature representation in this context. While it is an interesting mathematical technique, its effectiveness and appropriateness should be further scrutinized.
The dual adaptation mechanisms are also not thoroughly explained. It would be valuable to understand the precise transfer learning or domain adaptation strategies employed, as well as an analysis of their impact on model performance.
Finally, the paper does not compare OU-CoViT's performance to other state-of-the-art vision transformer or multi-task learning models. A more comprehensive benchmarking against relevant baselines would strengthen the claims about the model's effectiveness.
Conclusion
The OU-CoViT model presents a specialized deep learning approach for computer vision tasks on OU-UWF images. Its key innovations include a bi-channel multi-task vision transformer architecture and the incorporation of copula theory to enhance feature representation.
While the paper demonstrates promising results, more details are needed about the dataset, the specific challenges addressed, and the effectiveness of the copula-based and dual adaptation components. A more thorough comparative analysis would also help situate the OU-CoViT model within the broader landscape of computer vision research.
Overall, the OU-CoViT model showcases an interesting and potentially impactful approach to tackling domain-specific computer vision problems. Further exploration and validation of the techniques could lead to meaningful advancements in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OU-CoViT: Copula-Enhanced Bi-Channel Multi-Task Vision Transformers with Dual Adaptation for OU-UWF Images
Yang Li, Jianing Deng, Chong Zhong, Danjuan Yang, Meiyan Li, A. H. Welsh, Aiyi Liu, Xingtao Zhou, Catherine C. Liu, Bo Fu
Myopia screening using cutting-edge ultra-widefield (UWF) fundus imaging and joint modeling of multiple discrete and continuous clinical scores presents a promising new paradigm for multi-task problems in Ophthalmology. The bi-channel framework that arises from the Ophthalmic phenomenon of ``interocular asymmetries'' of both eyes (OU) calls for new employment on the SOTA transformer-based models. However, the application of copula models for multiple mixed discrete-continuous labels on deep learning (DL) is challenging. Moreover, the application of advanced large transformer-based models to small medical datasets is challenging due to overfitting and computational resource constraints. To resolve these challenges, we propose OU-CoViT: a novel Copula-Enhanced Bi-Channel Multi-Task Vision Transformers with Dual Adaptation for OU-UWF images, which can i) incorporate conditional correlation information across multiple discrete and continuous labels within a deep learning framework (by deriving the closed form of a novel Copula Loss); ii) take OU inputs subject to both high correlation and interocular asymmetries using a bi-channel model with dual adaptation; and iii) enable the adaptation of large vision transformer (ViT) models to small medical datasets. Solid experiments demonstrate that OU-CoViT significantly improves prediction performance compared to single-channel baseline models with empirical loss. Furthermore, the novel architecture of OU-CoViT allows generalizability and extensions of our dual adaptation and Copula Loss to various ViT variants and large DL models on small medical datasets. Our approach opens up new possibilities for joint modeling of heterogeneous multi-channel input and mixed discrete-continuous clinical scores in medical practices and has the potential to advance AI-assisted clinical decision-making in various medical domains beyond Ophthalmology.
Read more8/20/2024
🧠
0
CeCNN: Copula-enhanced convolutional neural networks in joint prediction of refraction error and axial length based on ultra-widefield fundus images
Chong Zhong, Yang Li, Danjuan Yang, Meiyan Li, Xingyao Zhou, Bo Fu, Catherine C. Liu, A. H. Welsh
The ultra-widefield (UWF) fundus image is an attractive 3D biomarker in AI-aided myopia screening because it provides much richer myopia-related information. Though axial length (AL) has been acknowledged to be highly related to the two key targets of myopia screening, Spherical Equivalence (SE) measurement and high myopia diagnosis, its prediction based on the UWF fundus image is rarely considered. To save the high expense and time costs of measuring SE and AL, we propose the Copula-enhanced Convolutional Neural Network (CeCNN), a one-stop UWF-based ophthalmic AI framework to jointly predict SE, AL, and myopia status. The CeCNN formulates a multiresponse regression that relates multiple dependent discrete-continuous responses and the image covariate, where the nonlinearity of the association is modeled by a backbone CNN. To thoroughly describe the dependence structure among the responses, we model and incorporate the conditional dependence among responses in a CNN through a new copula-likelihood loss. We provide statistical interpretations of the conditional dependence among responses, and reveal that such dependence is beyond the dependence explained by the image covariate. We heuristically justify that the proposed loss can enhance the estimation efficiency of the CNN weights. We apply the CeCNN to the UWF dataset collected by us and demonstrate that the CeCNN sharply enhances the predictive capability of various backbone CNNs. Our study evidences the ophthalmology view that besides SE, AL is also an important measure to myopia.
Read more8/19/2024
👀
0
Effectiveness of Vision Language Models for Open-world Single Image Test Time Adaptation
Manogna Sreenivas, Soma Biswas
We propose a novel framework to address the real-world challenging task of Single Image Test Time Adaptation in an open and dynamic environment. We leverage large scale Vision Language Models like CLIP to enable real time adaptation on a per-image basis without access to source data or ground truth labels. Since the deployed model can also encounter unseen classes in an open world, we first employ a simple and effective Out of Distribution (OOD) detection module to distinguish between weak and strong OOD samples. We propose a novel contrastive learning based objective to enhance the discriminability between weak and strong OOD samples by utilizing small, dynamically updated feature banks. Finally, we also employ a classification objective for adapting the model using the reliable weak OOD samples. The proposed framework ROSITA combines these components, enabling continuous online adaptation of Vision Language Models on a single image basis. Extensive experimentation on diverse domain adaptation benchmarks validates the effectiveness of the proposed framework. Our code can be found at the project site https://manogna-s.github.io/rosita/
Read more6/4/2024
0
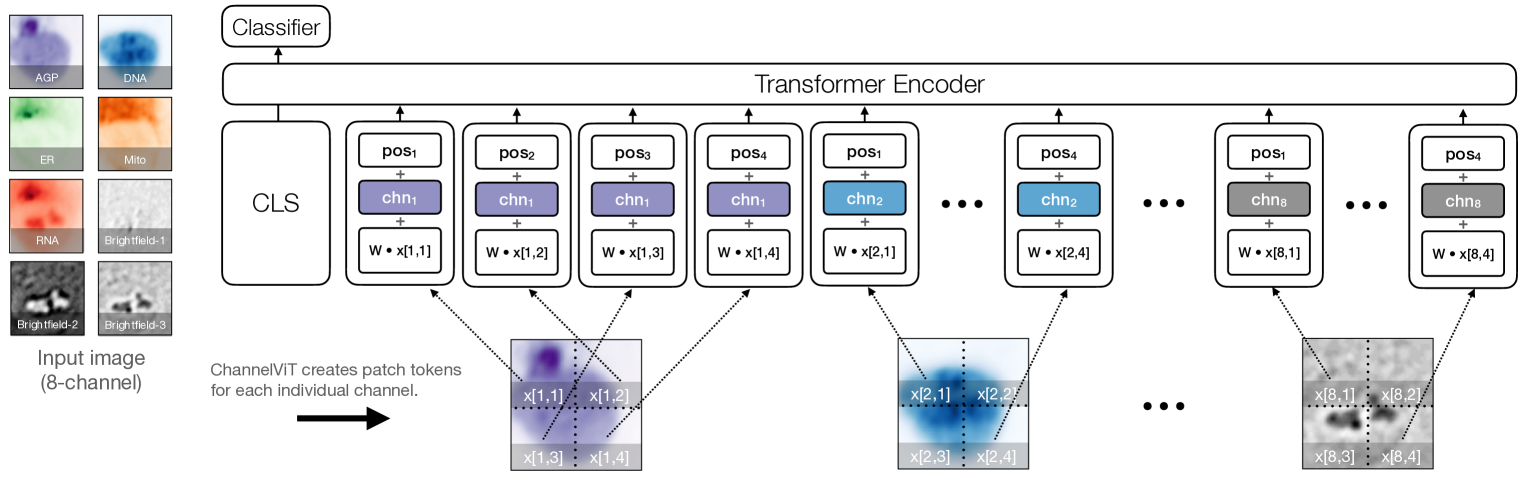
Channel Vision Transformers: An Image Is Worth 1 x 16 x 16 Words
Yujia Bao, Srinivasan Sivanandan, Theofanis Karaletsos
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
Read more4/22/2024