CeCNN: Copula-enhanced convolutional neural networks in joint prediction of refraction error and axial length based on ultra-widefield fundus images

0
🧠
Sign in to get full access
Overview
- Ultra-widefield (UWF) fundus imaging is becoming increasingly popular for screening, detecting, and predicting complications related to myopia.
- Spherical equivalent (SE) and axial length (AL) are key metrics used to assess myopia, and research shows they are strongly correlated.
- Leveraging the joint information from SE and AL may improve prediction accuracy over using either metric alone.
- The paper proposes a novel deep learning framework called Copula-enhanced Convolutional Neural Network (CeCNN) that incorporates the dependence between response variables.
Plain English Explanation
Myopia, or nearsightedness, is a common eye condition that causes blurry distant vision. Ultra-widefield (UWF) fundus imaging provides a much broader view of the eye compared to traditional fundus images, which is particularly helpful for assessing highly myopic eyes.
Two key metrics used to measure myopia are spherical equivalent (SE) and axial length (AL). SE refers to the overall focusing power of the eye, while AL is the length of the eyeball. Recent research has shown that these two measures are strongly related - as myopia progresses, the eye often elongates, increasing the AL.
The authors of this paper hypothesize that using both SE and AL together, rather than just one metric alone, could improve the accuracy of predicting and detecting myopia-related complications. To do this, they developed a new deep learning model called Copula-enhanced Convolutional Neural Network (CeCNN).
CeCNN is designed to capture the statistical dependence between the two response variables (SE and AL) using a mathematical technique called a "copula." This allows the model to leverage the relationship between these metrics to make more accurate predictions.
The authors demonstrate that CeCNN outperforms traditional deep learning approaches that treat the responses as independent. This suggests that incorporating the interconnected nature of SE and AL can lead to better performance in tasks like screening for myopia and its complications.
Technical Explanation
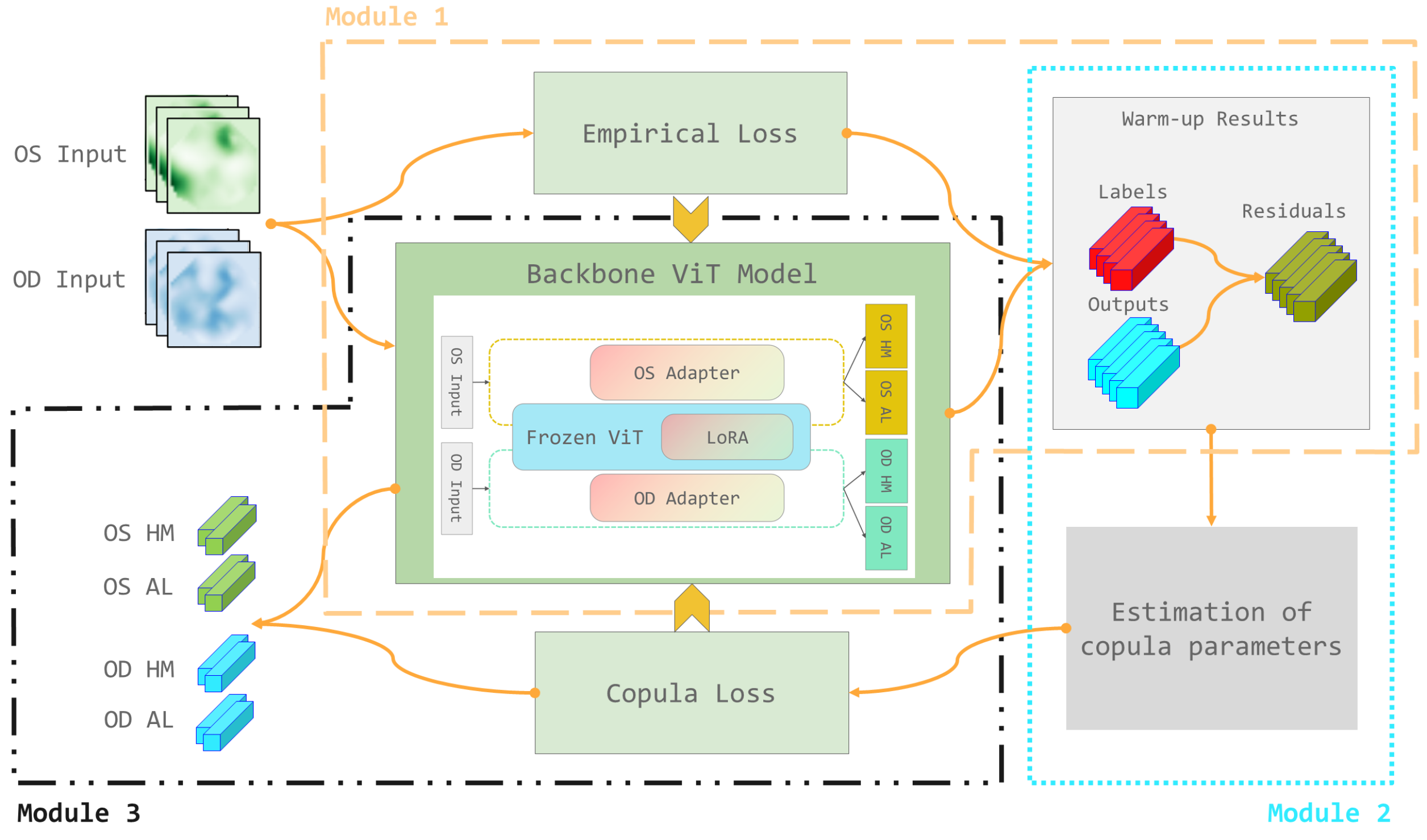
The paper proposes a Copula-enhanced Convolutional Neural Network (CeCNN) framework for bivariate regression-regression and regression-classification tasks, using a higher-order tensor biomarker (e.g., UWF fundus images).
The key innovation is the incorporation of the dependence between the two response variables (e.g., SE and AL) through a Gaussian copula. The copula parameters are estimated from a warm-up CNN, and the induced copula-likelihood loss is used with the backbone CNNs (e.g., ResNet, LeNet).
This approach differs from previous work in the deep learning community, where dependence among responses is only sporadically taken into consideration in multiple-response tasks with 3D image biomarkers.
The authors establish the statistical framework and algorithms for the two bivariate tasks (regression-regression and regression-classification). They demonstrate that the CeCNN framework leads to better prediction accuracy compared to backbone CNN models that do not explicitly model the dependence between responses.
The modeling and the proposed CeCNN algorithm are applicable beyond the UWF scenario and can be effective with other backbones beyond ResNet and LeNet, as shown in the Confidence-Aware Multi-Modality Learning for Eye Disease and Upright Adjustment with Graph Convolutional Networks papers.
Critical Analysis
The paper presents a well-designed approach to leveraging the joint information from SE and AL to improve the prediction accuracy of deep learning models. The use of a copula to capture the dependence between the response variables is a novel and promising technique.
However, the paper does not provide much discussion on the potential limitations or caveats of the proposed CeCNN framework. For example, it would be valuable to understand how the CeCNN performs in scenarios with different levels of dependence between the response variables, or how sensitive the results are to the choice of copula function.
Additionally, the paper focuses on the technical aspects of the modeling approach, but does not delve deeply into the clinical implications or potential real-world applications of the improved prediction accuracy. It would be helpful to see a more in-depth discussion of how the CeCNN framework could be used to enhance myopia screening, detection, and management in clinical settings.
Further research could also explore the use of Coordinate-Based Neural Representations for Computational Adaptive Optics or Flexible Image Analysis for Law Enforcement Agencies with Deep Learning to potentially improve the performance of the CeCNN framework.
Conclusion
This paper presents a novel Copula-enhanced Convolutional Neural Network (CeCNN) framework that explicitly models the dependence between response variables, such as spherical equivalent and axial length, in bivariate regression tasks. The authors demonstrate that incorporating this dependence information can lead to improved prediction accuracy compared to traditional deep learning approaches.
The CeCNN framework is a promising contribution to the field of myopia research, as it has the potential to enhance screening, detection, and management of myopia-related complications by leveraging the joint information from multiple ocular metrics. The modeling approach and algorithms described in the paper are also applicable to a wider range of bivariate tasks beyond the UWF fundus imaging scenario.
Further research is needed to fully understand the limitations and clinical implications of the CeCNN framework, but this work represents an important step forward in the use of deep learning and statistical modeling techniques to improve medical decision-making and patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
CeCNN: Copula-enhanced convolutional neural networks in joint prediction of refraction error and axial length based on ultra-widefield fundus images
Chong Zhong, Yang Li, Danjuan Yang, Meiyan Li, Xingyao Zhou, Bo Fu, Catherine C. Liu, A. H. Welsh
The ultra-widefield (UWF) fundus image is an attractive 3D biomarker in AI-aided myopia screening because it provides much richer myopia-related information. Though axial length (AL) has been acknowledged to be highly related to the two key targets of myopia screening, Spherical Equivalence (SE) measurement and high myopia diagnosis, its prediction based on the UWF fundus image is rarely considered. To save the high expense and time costs of measuring SE and AL, we propose the Copula-enhanced Convolutional Neural Network (CeCNN), a one-stop UWF-based ophthalmic AI framework to jointly predict SE, AL, and myopia status. The CeCNN formulates a multiresponse regression that relates multiple dependent discrete-continuous responses and the image covariate, where the nonlinearity of the association is modeled by a backbone CNN. To thoroughly describe the dependence structure among the responses, we model and incorporate the conditional dependence among responses in a CNN through a new copula-likelihood loss. We provide statistical interpretations of the conditional dependence among responses, and reveal that such dependence is beyond the dependence explained by the image covariate. We heuristically justify that the proposed loss can enhance the estimation efficiency of the CNN weights. We apply the CeCNN to the UWF dataset collected by us and demonstrate that the CeCNN sharply enhances the predictive capability of various backbone CNNs. Our study evidences the ophthalmology view that besides SE, AL is also an important measure to myopia.
Read more8/19/2024
0
OU-CoViT: Copula-Enhanced Bi-Channel Multi-Task Vision Transformers with Dual Adaptation for OU-UWF Images
Yang Li, Jianing Deng, Chong Zhong, Danjuan Yang, Meiyan Li, A. H. Welsh, Aiyi Liu, Xingtao Zhou, Catherine C. Liu, Bo Fu
Myopia screening using cutting-edge ultra-widefield (UWF) fundus imaging and joint modeling of multiple discrete and continuous clinical scores presents a promising new paradigm for multi-task problems in Ophthalmology. The bi-channel framework that arises from the Ophthalmic phenomenon of ``interocular asymmetries'' of both eyes (OU) calls for new employment on the SOTA transformer-based models. However, the application of copula models for multiple mixed discrete-continuous labels on deep learning (DL) is challenging. Moreover, the application of advanced large transformer-based models to small medical datasets is challenging due to overfitting and computational resource constraints. To resolve these challenges, we propose OU-CoViT: a novel Copula-Enhanced Bi-Channel Multi-Task Vision Transformers with Dual Adaptation for OU-UWF images, which can i) incorporate conditional correlation information across multiple discrete and continuous labels within a deep learning framework (by deriving the closed form of a novel Copula Loss); ii) take OU inputs subject to both high correlation and interocular asymmetries using a bi-channel model with dual adaptation; and iii) enable the adaptation of large vision transformer (ViT) models to small medical datasets. Solid experiments demonstrate that OU-CoViT significantly improves prediction performance compared to single-channel baseline models with empirical loss. Furthermore, the novel architecture of OU-CoViT allows generalizability and extensions of our dual adaptation and Copula Loss to various ViT variants and large DL models on small medical datasets. Our approach opens up new possibilities for joint modeling of heterogeneous multi-channel input and mixed discrete-continuous clinical scores in medical practices and has the potential to advance AI-assisted clinical decision-making in various medical domains beyond Ophthalmology.
Read more8/20/2024
0
Generative artificial intelligence in ophthalmology: multimodal retinal images for the diagnosis of Alzheimer's disease with convolutional neural networks
I. R. Slootweg, M. Thach, K. R. Curro-Tafili, F. D. Verbraak, F. H. Bouwman, Y. A. L. Pijnenburg, J. F. Boer, J. H. P. de Kwisthout, L. Bagheriye, P. J. Gonz'alez
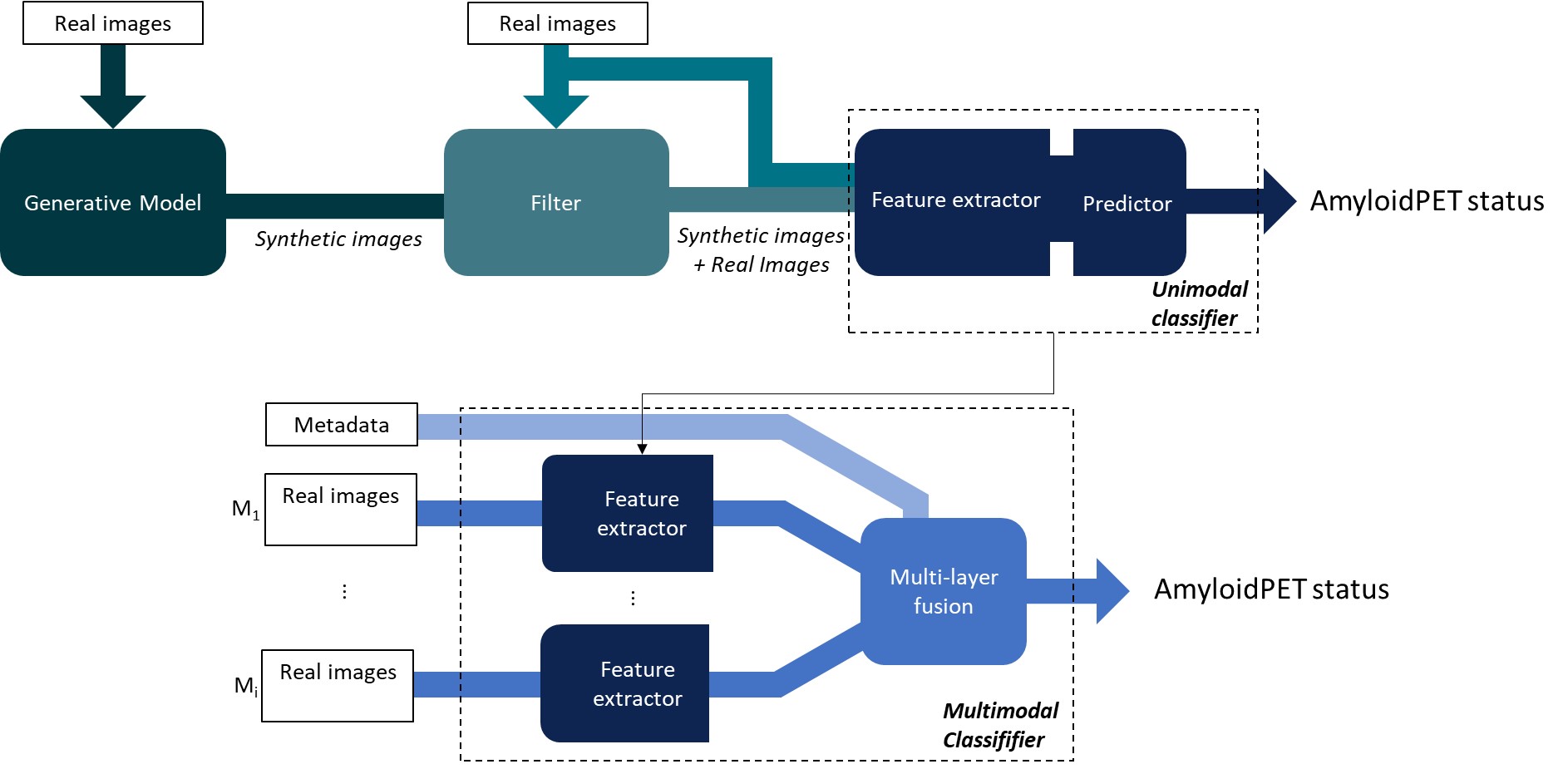
Background/Aim. This study aims to predict Amyloid Positron Emission Tomography (AmyloidPET) status with multimodal retinal imaging and convolutional neural networks (CNNs) and to improve the performance through pretraining with synthetic data. Methods. Fundus autofluorescence, optical coherence tomography (OCT), and OCT angiography images from 328 eyes of 59 AmyloidPET positive subjects and 108 AmyloidPET negative subjects were used for classification. Denoising Diffusion Probabilistic Models (DDPMs) were trained to generate synthetic images and unimodal CNNs were pretrained on synthetic data and finetuned on real data or trained solely on real data. Multimodal classifiers were developed to combine predictions of the four unimodal CNNs with patient metadata. Class activation maps of the unimodal classifiers provided insight into the network's attention to inputs. Results. DDPMs generated diverse, realistic images without memorization. Pretraining unimodal CNNs with synthetic data improved AUPR at most from 0.350 to 0.579. Integration of metadata in multimodal CNNs improved AUPR from 0.486 to 0.634, which was the best overall best classifier. Class activation maps highlighted relevant retinal regions which correlated with AD. Conclusion. Our method for generating and leveraging synthetic data has the potential to improve AmyloidPET prediction from multimodal retinal imaging. A DDPM can generate realistic and unique multimodal synthetic retinal images. Our best performing unimodal and multimodal classifiers were not pretrained on synthetic data, however pretraining with synthetic data slightly improved classification performance for two out of the four modalities.
Read more6/27/2024
🔮
0
Direct Zernike Coefficient Prediction from Point Spread Functions and Extended Images using Deep Learning
Yong En Kok (School of Computer Science, University of Nottingham, Nottingham, UK), Alexander Bentley (Optics and Photonics Group, Department of Electrical and Electronic Engineering, University of Nottingham, Nottingham, UK), Andrew Parkes (School of Computer Science, University of Nottingham, Nottingham, UK), Amanda J. Wright (Optics and Photonics Group, Department of Electrical and Electronic Engineering, University of Nottingham, Nottingham, UK), Michael G. Somekh (Optics and Photonics Group, Department of Electrical and Electronic Engineering, University of Nottingham, Nottingham, UK, Research Center for Humanoid Sensing, Zhejiang Laboratory Hangzhou, China), Michael Pound (School of Computer Science, University of Nottingham, Nottingham, UK)
Optical imaging quality can be severely degraded by system and sample induced aberrations. Existing adaptive optics systems typically rely on iterative search algorithm to correct for aberrations and improve images. This study demonstrates the application of convolutional neural networks to characterise the optical aberration by directly predicting the Zernike coefficients from two to three phase-diverse optical images. We evaluated our network on 600,000 simulated Point Spread Function (PSF) datasets randomly generated within the range of -1 to 1 radians using the first 25 Zernike coefficients. The results show that using only three phase-diverse images captured above, below and at the focal plane with an amplitude of 1 achieves a low RMSE of 0.10 radians on the simulated PSF dataset. Furthermore, this approach directly predicts Zernike modes simulated extended 2D samples, while maintaining a comparable RMSE of 0.15 radians. We demonstrate that this approach is effective using only a single prediction step, or can be iterated a small number of times. This simple and straightforward technique provides rapid and accurate method for predicting the aberration correction using three or less phase-diverse images, paving the way for evaluation on real-world dataset.
Read more4/24/2024