Out-Of-Distribution Detection for Audio-visual Generalized Zero-Shot Learning: A General Framework

0

Sign in to get full access
Overview
- This paper introduces a general framework for out-of-distribution (OOD) detection in audio-visual generalized zero-shot learning (GZSL) tasks.
- The proposed approach aims to improve the performance and robustness of GZSL models by identifying and handling samples that do not belong to the seen or unseen classes during training and inference.
- The framework includes novel OOD detection techniques and a regularization method to enhance the generalization of GZSL models.
Plain English Explanation
The paper presents a new way to improve the performance of machine learning models that can recognize both familiar and unfamiliar objects or concepts (known as generalized zero-shot learning or GZSL). The key idea is to develop techniques that can identify when an input doesn't belong to any of the classes the model was trained on, which is called "out-of-distribution" (OOD) detection. By being able to detect these OOD samples, the model can handle them more appropriately, leading to better overall performance.
The researchers propose a general framework that incorporates OOD detection methods and a regularization technique to make GZSL models more robust and accurate. The approach aims to enhance the model's ability to distinguish between in-distribution samples (from known classes) and out-of-distribution samples (from unknown classes) during both training and inference.
Technical Explanation
The paper introduces a general framework for OOD detection in audio-visual GZSL tasks. The core components of the framework include:
-
OOD Detection Techniques: The authors propose novel OOD detection methods that leverage the audio and visual modalities to identify samples that do not belong to the seen or unseen classes during training and inference.
-
Regularization Method: The researchers introduce a regularization technique that encourages the GZSL model to learn more discriminative features, enhancing its ability to generalize to unseen classes.
The proposed OOD detection methods aim to improve the model's performance by identifying and handling OOD samples more effectively. The regularization technique helps the model learn better representations, which can lead to better generalization to unseen classes.
The authors evaluate their framework on several audio-visual GZSL benchmarks and demonstrate significant improvements in both OOD detection and GZSL performance compared to existing approaches.
Critical Analysis
The paper presents a comprehensive framework for OOD detection in audio-visual GZSL, which is an important and challenging problem. The proposed techniques seem promising, and the empirical results suggest that the framework can effectively improve the performance and robustness of GZSL models.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the proposed approach. For example, the authors could discuss the computational complexity of the OOD detection methods or the sensitivity of the regularization technique to hyperparameter tuning.
Additionally, the paper could have explored the generalization of the framework to other modalities beyond audio-visual, such as text or multi-modal data, to further demonstrate its broader applicability.
Conclusion
This paper presents a general framework for OOD detection in audio-visual GZSL tasks, which aims to enhance the performance and robustness of GZSL models. The key contributions include novel OOD detection techniques and a regularization method that can help GZSL models better distinguish between in-distribution and out-of-distribution samples.
The proposed approach shows promising results on benchmark datasets and could have significant implications for improving the reliability and deployment of GZSL models in real-world applications. Further research on addressing the potential limitations and exploring the framework's extensibility to other modalities could further advance the field of generalized zero-shot learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Out-Of-Distribution Detection for Audio-visual Generalized Zero-Shot Learning: A General Framework
Liuyuan Wen
Generalized Zero-Shot Learning (GZSL) is a challenging task requiring accurate classification of both seen and unseen classes. Within this domain, Audio-visual GZSL emerges as an extremely exciting yet difficult task, given the inclusion of both visual and acoustic features as multi-modal inputs. Existing efforts in this field mostly utilize either embedding-based or generative-based methods. However, generative training is difficult and unstable, while embedding-based methods often encounter domain shift problem. Thus, we find it promising to integrate both methods into a unified framework to leverage their advantages while mitigating their respective disadvantages. Our study introduces a general framework employing out-of-distribution (OOD) detection, aiming to harness the strengths of both approaches. We first employ generative adversarial networks to synthesize unseen features, enabling the training of an OOD detector alongside classifiers for seen and unseen classes. This detector determines whether a test feature belongs to seen or unseen classes, followed by classification utilizing separate classifiers for each feature type. We test our framework on three popular audio-visual datasets and observe a significant improvement comparing to existing state-of-the-art works. Codes can be found in https://github.com/liuyuan-wen/AV-OOD-GZSL.
Read more8/6/2024
0
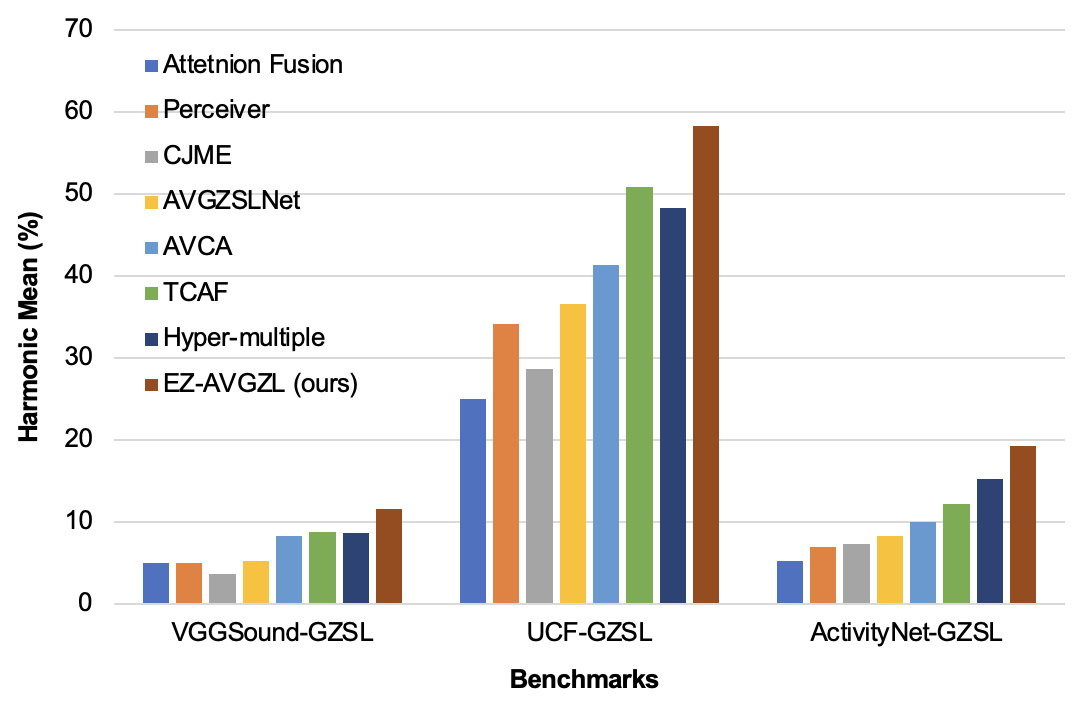
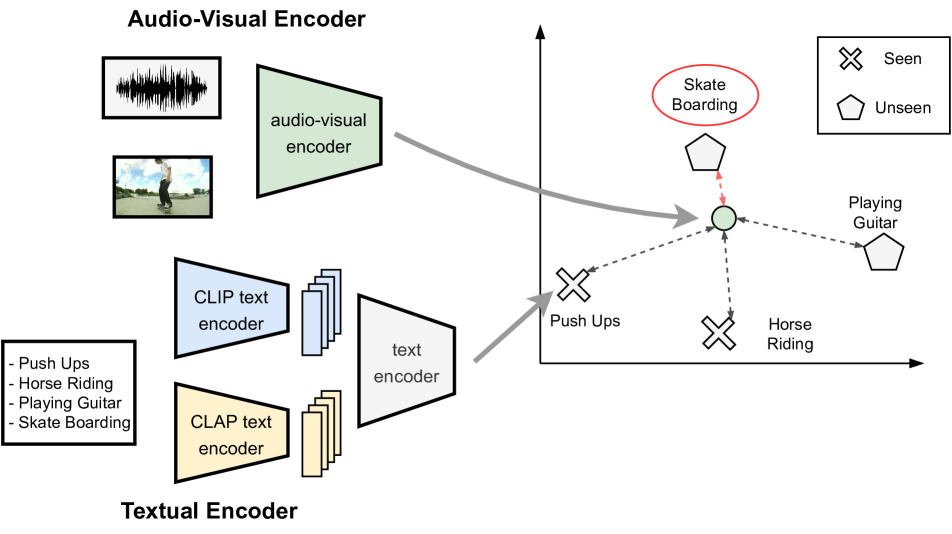
Audio-visual Generalized Zero-shot Learning the Easy Way
Shentong Mo, Pedro Morgado
Audio-visual generalized zero-shot learning is a rapidly advancing domain that seeks to understand the intricate relations between audio and visual cues within videos. The overarching goal is to leverage insights from seen classes to identify instances from previously unseen ones. Prior approaches primarily utilized synchronized auto-encoders to reconstruct audio-visual attributes, which were informed by cross-attention transformers and projected text embeddings. However, these methods fell short of effectively capturing the intricate relationship between cross-modal features and class-label embeddings inherent in pre-trained language-aligned embeddings. To circumvent these bottlenecks, we introduce a simple yet effective framework for Easy Audio-Visual Generalized Zero-shot Learning, named EZ-AVGZL, that aligns audio-visual embeddings with transformed text representations. It utilizes a single supervised text audio-visual contrastive loss to learn an alignment between audio-visual and textual modalities, moving away from the conventional approach of reconstructing cross-modal features and text embeddings. Our key insight is that while class name embeddings are well aligned with language-based audio-visual features, they don't provide sufficient class separation to be useful for zero-shot learning. To address this, our method leverages differential optimization to transform class embeddings into a more discriminative space while preserving the semantic structure of language representations. We conduct extensive experiments on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL benchmarks. Our results demonstrate that our EZ-AVGZL achieves state-of-the-art performance in audio-visual generalized zero-shot learning.
Read more7/19/2024
0
Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
David Kurzendorfer, Otniel-Bogdan Mercea, A. Sophia Koepke, Zeynep Akata
Audio-visual zero-shot learning methods commonly build on features extracted from pre-trained models, e.g. video or audio classification models. However, existing benchmarks predate the popularization of large multi-modal models, such as CLIP and CLAP. In this work, we explore such large pre-trained models to obtain features, i.e. CLIP for visual features, and CLAP for audio features. Furthermore, the CLIP and CLAP text encoders provide class label embeddings which are combined to boost the performance of the system. We propose a simple yet effective model that only relies on feed-forward neural networks, exploiting the strong generalization capabilities of the new audio, visual and textual features. Our framework achieves state-of-the-art performance on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL with our new features. Code and data available at: https://github.com/dkurzend/ClipClap-GZSL.
Read more4/10/2024

0
Generalized Out-of-Distribution Detection and Beyond in Vision Language Model Era: A Survey
Atsuyuki Miyai, Jingkang Yang, Jingyang Zhang, Yifei Ming, Yueqian Lin, Qing Yu, Go Irie, Shafiq Joty, Yixuan Li, Hai Li, Ziwei Liu, Toshihiko Yamasaki, Kiyoharu Aizawa
Detecting out-of-distribution (OOD) samples is crucial for ensuring the safety of machine learning systems and has shaped the field of OOD detection. Meanwhile, several other problems are closely related to OOD detection, including anomaly detection (AD), novelty detection (ND), open set recognition (OSR), and outlier detection (OD). To unify these problems, a generalized OOD detection framework was proposed, taxonomically categorizing these five problems. However, Vision Language Models (VLMs) such as CLIP have significantly changed the paradigm and blurred the boundaries between these fields, again confusing researchers. In this survey, we first present a generalized OOD detection v2, encapsulating the evolution of AD, ND, OSR, OOD detection, and OD in the VLM era. Our framework reveals that, with some field inactivity and integration, the demanding challenges have become OOD detection and AD. In addition, we also highlight the significant shift in the definition, problem settings, and benchmarks; we thus feature a comprehensive review of the methodology for OOD detection, including the discussion over other related tasks to clarify their relationship to OOD detection. Finally, we explore the advancements in the emerging Large Vision Language Model (LVLM) era, such as GPT-4V. We conclude this survey with open challenges and future directions.
Read more8/1/2024