Audio-visual Generalized Zero-shot Learning the Easy Way

0
Sign in to get full access
Overview
- This paper proposes a novel approach to audio-visual generalized zero-shot learning, which aims to classify objects and recognize audio-visual concepts without any training examples.
- The method leverages pre-trained audio and visual models, along with text embeddings, to learn a shared multimodal representation that can be used for classification.
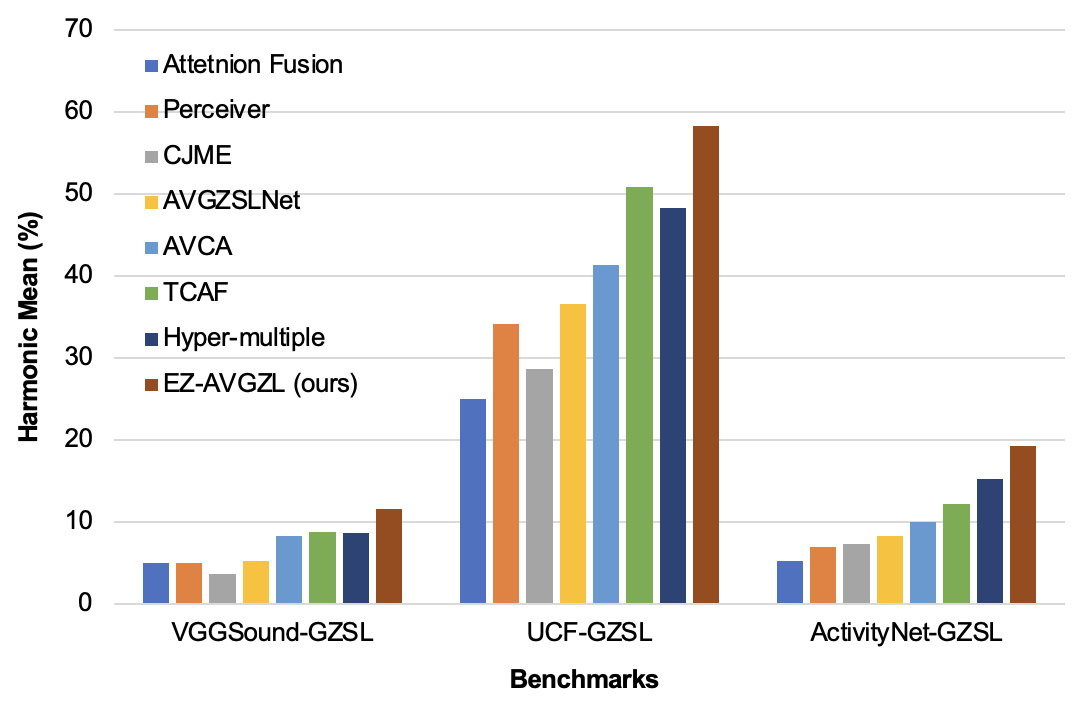
- The researchers demonstrate the effectiveness of their approach on several benchmark datasets, achieving state-of-the-art performance on audio-visual zero-shot learning tasks.
Plain English Explanation
The paper discusses a new way to train AI models to recognize objects and audio-visual concepts, even if the model hasn't seen examples of those things before. Typically, AI models need to be trained on lots of examples to learn how to classify things. But this new approach allows the model to learn using just text descriptions, without needing any actual examples.
The key idea is to use pre-trained models for processing audio and visual information, and then connect them to a shared text-based representation. This allows the model to learn the relationships between the different modalities (sound, images, text) without needing to see lots of examples. The researchers show that this approach works well on several benchmark datasets, outperforming other state-of-the-art methods for audio-visual zero-shot learning.
This is an important advance because it means AI models can be more flexible and adaptable, able to recognize new concepts without extensive retraining. It could lead to more versatile and capable AI assistants, for example, that can understand and respond to a wider range of audio-visual information. The Unified Video Language Pre-Training and Visual Echoes papers explore related ideas for joint audio-visual understanding.
Technical Explanation
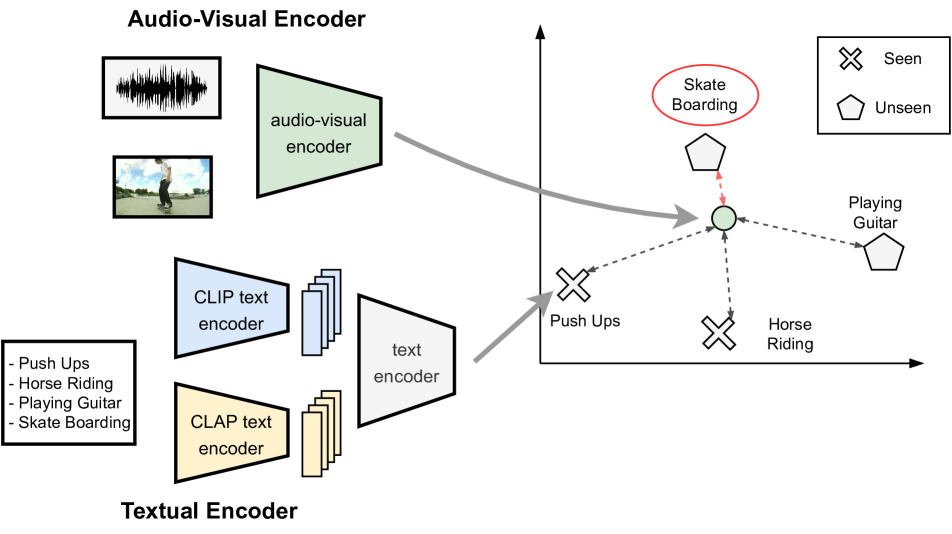
The paper proposes an audio-visual generalized zero-shot learning (AVGZSL) approach that leverages pre-trained audio and visual models, along with text embeddings, to learn a shared multimodal representation.
The key components are:
- Audio and Visual Encoders: Pre-trained models for encoding audio and visual inputs into feature representations.
- Text Encoder: A model for encoding text descriptions into embeddings.
- Multimodal Fusion: A module that learns to fuse the audio, visual, and text representations into a shared multimodal space.
- Classifier: A final classification layer that can predict unseen audio-visual concepts using the shared multimodal representations.
The paper evaluates this approach on several audio-visual zero-shot learning benchmarks, including Getting More with Less and EquiAV datasets. The results show that the proposed method outperforms other state-of-the-art AVGZSL techniques.
Critical Analysis
The paper presents a promising approach to audio-visual zero-shot learning, but there are a few potential limitations and areas for further research:
- Dataset Bias: The benchmarks used in the evaluation may not fully capture the diversity of real-world audio-visual concepts. Further testing on more diverse datasets would help validate the generalizability of the approach.
- Interpretability: The paper does not provide much insight into the internal representations learned by the multimodal fusion module. Improving the interpretability of the model could lead to a better understanding of how it achieves its strong performance.
- Scalability: While the approach shows promising results on the evaluated datasets, its scalability to larger-scale audio-visual understanding tasks remains to be seen. Exploring ways to make the model more efficient and applicable to real-world applications would be valuable.
Overall, the paper makes a compelling contribution to the field of audio-visual learning and zero-shot classification. Further research building on these ideas could lead to more versatile and powerful AI systems that can comprehend and interact with the multimodal world around them.
Conclusion
This paper presents a novel approach to audio-visual generalized zero-shot learning that leverages pre-trained models and text embeddings to learn a shared multimodal representation. The results demonstrate state-of-the-art performance on several benchmark datasets, suggesting that this method could be a promising step towards more flexible and adaptable AI systems.
By enabling AI models to recognize new audio-visual concepts without extensive retraining, this work could have far-reaching implications for applications like intelligent assistants, augmented reality, and human-robot interaction. Continued research in this area may lead to breakthroughs in how AI systems can understand and interact with the rich, multimodal world around them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio-visual Generalized Zero-shot Learning the Easy Way
Shentong Mo, Pedro Morgado
Audio-visual generalized zero-shot learning is a rapidly advancing domain that seeks to understand the intricate relations between audio and visual cues within videos. The overarching goal is to leverage insights from seen classes to identify instances from previously unseen ones. Prior approaches primarily utilized synchronized auto-encoders to reconstruct audio-visual attributes, which were informed by cross-attention transformers and projected text embeddings. However, these methods fell short of effectively capturing the intricate relationship between cross-modal features and class-label embeddings inherent in pre-trained language-aligned embeddings. To circumvent these bottlenecks, we introduce a simple yet effective framework for Easy Audio-Visual Generalized Zero-shot Learning, named EZ-AVGZL, that aligns audio-visual embeddings with transformed text representations. It utilizes a single supervised text audio-visual contrastive loss to learn an alignment between audio-visual and textual modalities, moving away from the conventional approach of reconstructing cross-modal features and text embeddings. Our key insight is that while class name embeddings are well aligned with language-based audio-visual features, they don't provide sufficient class separation to be useful for zero-shot learning. To address this, our method leverages differential optimization to transform class embeddings into a more discriminative space while preserving the semantic structure of language representations. We conduct extensive experiments on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL benchmarks. Our results demonstrate that our EZ-AVGZL achieves state-of-the-art performance in audio-visual generalized zero-shot learning.
Read more7/19/2024
0
Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
David Kurzendorfer, Otniel-Bogdan Mercea, A. Sophia Koepke, Zeynep Akata
Audio-visual zero-shot learning methods commonly build on features extracted from pre-trained models, e.g. video or audio classification models. However, existing benchmarks predate the popularization of large multi-modal models, such as CLIP and CLAP. In this work, we explore such large pre-trained models to obtain features, i.e. CLIP for visual features, and CLAP for audio features. Furthermore, the CLIP and CLAP text encoders provide class label embeddings which are combined to boost the performance of the system. We propose a simple yet effective model that only relies on feed-forward neural networks, exploiting the strong generalization capabilities of the new audio, visual and textual features. Our framework achieves state-of-the-art performance on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL with our new features. Code and data available at: https://github.com/dkurzend/ClipClap-GZSL.
Read more4/10/2024

0
Out-Of-Distribution Detection for Audio-visual Generalized Zero-Shot Learning: A General Framework
Liuyuan Wen
Generalized Zero-Shot Learning (GZSL) is a challenging task requiring accurate classification of both seen and unseen classes. Within this domain, Audio-visual GZSL emerges as an extremely exciting yet difficult task, given the inclusion of both visual and acoustic features as multi-modal inputs. Existing efforts in this field mostly utilize either embedding-based or generative-based methods. However, generative training is difficult and unstable, while embedding-based methods often encounter domain shift problem. Thus, we find it promising to integrate both methods into a unified framework to leverage their advantages while mitigating their respective disadvantages. Our study introduces a general framework employing out-of-distribution (OOD) detection, aiming to harness the strengths of both approaches. We first employ generative adversarial networks to synthesize unseen features, enabling the training of an OOD detector alongside classifiers for seen and unseen classes. This detector determines whether a test feature belongs to seen or unseen classes, followed by classification utilizing separate classifiers for each feature type. We test our framework on three popular audio-visual datasets and observe a significant improvement comparing to existing state-of-the-art works. Codes can be found in https://github.com/liuyuan-wen/AV-OOD-GZSL.
Read more8/6/2024

0
On Class Separability Pitfalls In Audio-Text Contrastive Zero-Shot Learning
Tiago Tavares, Fabio Ayres, Zhepei Wang, Paris Smaragdis
Recent advances in audio-text cross-modal contrastive learning have shown its potential towards zero-shot learning. One possibility for this is by projecting item embeddings from pre-trained backbone neural networks into a cross-modal space in which item similarity can be calculated in either domain. This process relies on a strong unimodal pre-training of the backbone networks, and on a data-intensive training task for the projectors. These two processes can be biased by unintentional data leakage, which can arise from using supervised learning in pre-training or from inadvertently training the cross-modal projection using labels from the zero-shot learning evaluation. In this study, we show that a significant part of the measured zero-shot learning accuracy is due to strengths inherited from the audio and text backbones, that is, they are not learned in the cross-modal domain and are not transferred from one modality to another.
Read more8/26/2024