OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding

0

Sign in to get full access
Overview
- This paper introduces OVAL-Prompt, a new approach that enables robots to understand and manipulate objects in the world by grounding their affordance knowledge from large language models (LLMs).
- The key idea is to leverage the rich knowledge about object affordances encoded in LLMs and transfer this knowledge to improve a robot's ability to perceive and interact with objects in the real world.
- The paper demonstrates that OVAL-Prompt can outperform state-of-the-art object detection and 6D pose estimation models on a range of manipulation tasks, showcasing its potential for enhancing robot capabilities.
Plain English Explanation
The paper explores a new way to help robots better understand and interact with objects in the real world. The key insight is that large language models (LLMs), which are trained on vast amounts of text data, have developed rich knowledge about the different ways we can use or "afford" various objects. OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding presents a method to transfer this affordance knowledge from LLMs to improve a robot's perception and manipulation capabilities.
Imagine you're teaching a robot how to do chores around the house. Instead of having to show the robot every possible way to interact with each object, the researchers found a way to "download" that knowledge from language models that have learned about objects and their uses from reading and processing huge amounts of text. This allows the robot to quickly understand how it can interact with new objects, without having to learn everything from scratch.
The paper demonstrates that this approach, called OVAL-Prompt, can outperform state-of-the-art object detection and pose estimation models, meaning the robot is better able to identify and manipulate objects compared to existing methods. This is an important step towards developing robots that can flexibly and intelligently interact with the world around them, drawing on the vast knowledge captured in language models.
Technical Explanation
The key innovation in OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding is the idea of "grounding" the affordance knowledge encoded in large language models (LLMs) to improve a robot's perception and manipulation capabilities.
The researchers start by training an LLM on a large corpus of text data, which allows the model to develop rich representations of objects and their associated affordances (i.e., the different ways an object can be used or interacted with). They then propose a novel architecture called OVAL-Prompt that takes this affordance knowledge from the LLM and uses it to guide the robot's object detection and 6D pose estimation tasks.
Specifically, OVAL-Prompt uses the LLM's representations as prompts to a vision-based object detection model, allowing the robot to better recognize and localize objects in the environment. The system also leverages the affordance information from the LLM to predict how the robot can manipulate the detected objects, such as grasping them or using them for a specific task.
The researchers evaluate OVAL-Prompt on a range of manipulation tasks and show that it outperforms state-of-the-art object detection and 6D pose estimation models, such as WorldAfford: Affordance Grounding based on Natural Language Instructions, Open-Vocabulary Object 6D Pose Estimation, and Text-Driven Affordance Learning from Egocentric Vision. This demonstrates the power of leveraging the rich affordance knowledge captured in LLMs to enhance a robot's understanding and manipulation of objects in the real world.
Critical Analysis
The OVAL-Prompt approach presented in the paper shows promise for improving robot manipulation capabilities by grounding affordance knowledge from large language models. However, the researchers acknowledge several limitations and areas for further research:
-
Dependency on LLM performance: The effectiveness of OVAL-Prompt is inherently tied to the quality and breadth of the affordance knowledge captured in the underlying LLM. If the LLM has gaps or biases in its understanding of object affordances, this could limit the robot's capabilities.
-
Potential for negative transfer: While the paper demonstrates the benefits of transferring affordance knowledge from LLMs, there is a risk of "negative transfer" if the LLM's representations do not align well with the specific robot and environment. Addressing this challenge is an important area for future work.
-
Scalability and generalization: The experiments in the paper focus on a limited set of objects and manipulation tasks. Further research is needed to assess how well OVAL-Prompt scales to a broader range of objects and scenarios, and how well the affordance knowledge can generalize to novel situations.
-
Safety and robustness: As with any AI system, there are potential concerns around the safety and robustness of OVAL-Prompt, especially when it comes to real-world robot manipulation. Addressing these issues is crucial for the practical deployment of such systems.
Despite these limitations, the OVAL-Prompt approach represents an exciting step forward in leveraging the rich knowledge captured in large language models to enhance robot capabilities. As the researchers continue to refine and expand this work, it will be interesting to see how it contributes to the broader effort of developing more intelligent and capable robots that can seamlessly interact with the world around them.
Conclusion
OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding presents a novel approach to improving robot manipulation capabilities by grounding affordance knowledge from large language models. By transferring the rich understanding of object affordances captured in LLMs, the OVAL-Prompt system outperforms state-of-the-art object detection and 6D pose estimation models, demonstrating its potential to enhance a robot's perception and interaction with the world.
This work represents an important step towards developing more flexible and intelligent robots that can draw on vast amounts of knowledge to understand and manipulate their environment. As the researchers address the identified limitations and continue to refine the approach, the OVAL-Prompt system could have significant implications for a wide range of robotic applications, from household chores to industrial automation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding
Edmond Tong, Anthony Opipari, Stanley Lewis, Zhen Zeng, Odest Chadwicke Jenkins
In order for robots to interact with objects effectively, they must understand the form and function of each object they encounter. Essentially, robots need to understand which actions each object affords, and where those affordances can be acted on. Robots are ultimately expected to operate in unstructured human environments, where the set of objects and affordances is not known to the robot before deployment (i.e. the open-vocabulary setting). In this work, we introduce OVAL-Prompt, a prompt-based approach for open-vocabulary affordance localization in RGB-D images. By leveraging a Vision Language Model (VLM) for open-vocabulary object part segmentation and a Large Language Model (LLM) to ground each part-segment-affordance, OVAL-Prompt demonstrates generalizability to novel object instances, categories, and affordances without domain-specific finetuning. Quantitative experiments demonstrate that without any finetuning, OVAL-Prompt achieves localization accuracy that is competitive with supervised baseline models. Moreover, qualitative experiments show that OVAL-Prompt enables affordance-based robot manipulation of open-vocabulary object instances and categories. Project Page: https://ekjt.github.io/OVAL-Prompt/
Read more5/28/2024
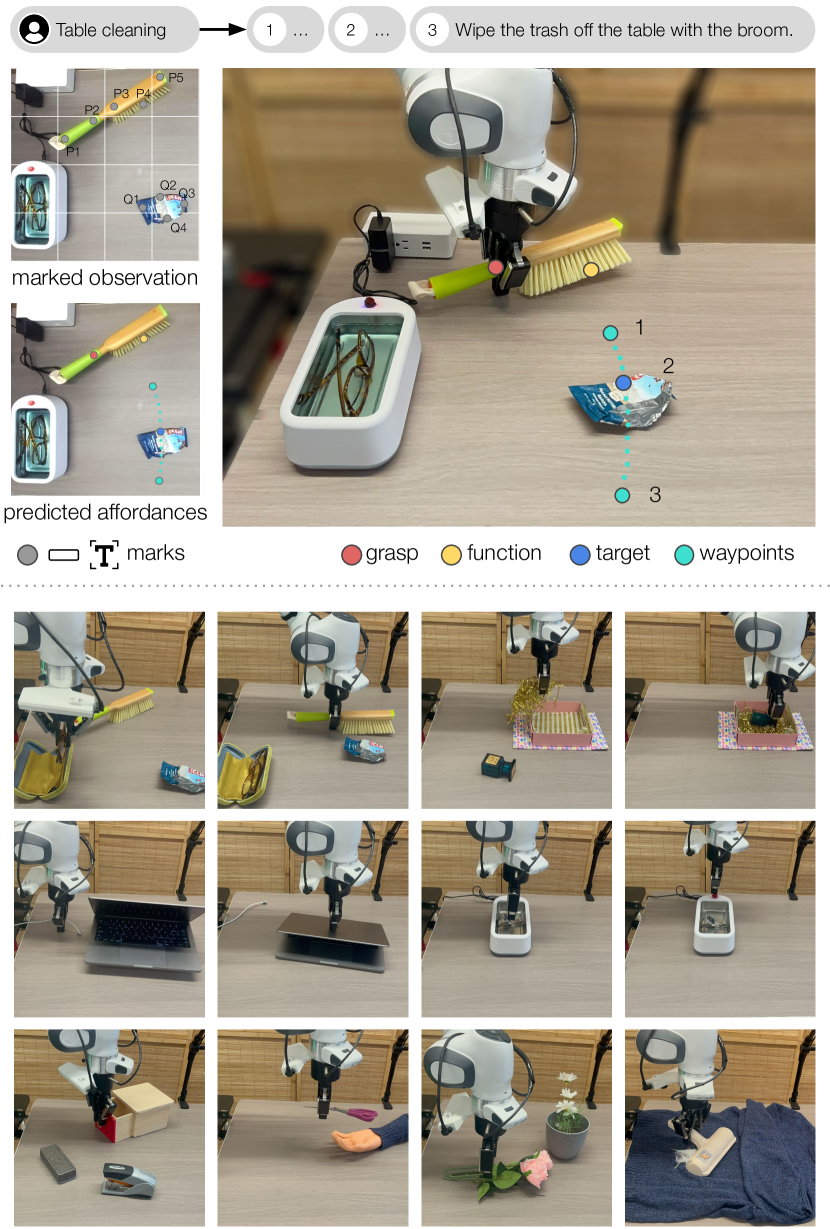
0
MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting
Fangchen Liu, Kuan Fang, Pieter Abbeel, Sergey Levine
Open-world generalization requires robotic systems to have a profound understanding of the physical world and the user command to solve diverse and complex tasks. While the recent advancement in vision-language models (VLMs) has offered unprecedented opportunities to solve open-world problems, how to leverage their capabilities to control robots remains a grand challenge. In this paper, we introduce Marking Open-world Keypoint Affordances (MOKA), an approach that employs VLMs to solve robotic manipulation tasks specified by free-form language instructions. Central to our approach is a compact point-based representation of affordance, which bridges the VLM's predictions on observed images and the robot's actions in the physical world. By prompting the pre-trained VLM, our approach utilizes the VLM's commonsense knowledge and concept understanding acquired from broad data sources to predict affordances and generate motions. To facilitate the VLM's reasoning in zero-shot and few-shot manners, we propose a visual prompting technique that annotates marks on images, converting affordance reasoning into a series of visual question-answering problems that are solvable by the VLM. We further explore methods to enhance performance with robot experiences collected by MOKA through in-context learning and policy distillation. We evaluate and analyze MOKA's performance on various table-top manipulation tasks including tool use, deformable body manipulation, and object rearrangement.
Read more9/5/2024

0
Affordance-Guided Reinforcement Learning via Visual Prompting
Olivia Y. Lee, Annie Xie, Kuan Fang, Karl Pertsch, Chelsea Finn
Robots equipped with reinforcement learning (RL) have the potential to learn a wide range of skills solely from a reward signal. However, obtaining a robust and dense reward signal for general manipulation tasks remains a challenge. Existing learning-based approaches require significant data, such as demonstrations or examples of success and failure, to learn task-specific reward functions. Recently, there is also a growing adoption of large multi-modal foundation models for robotics. These models can perform visual reasoning in physical contexts and generate coarse robot motions for various manipulation tasks. Motivated by this range of capability, in this work, we propose and study rewards shaped by vision-language models (VLMs). State-of-the-art VLMs have demonstrated an impressive ability to reason about affordances through keypoints in zero-shot, and we leverage this to define dense rewards for robotic learning. On a real-world manipulation task specified by natural language description, we find that these rewards improve the sample efficiency of autonomous RL and enable successful completion of the task in 20K online finetuning steps. Additionally, we demonstrate the robustness of the approach to reductions in the number of in-domain demonstrations used for pretraining, reaching comparable performance in 35K online finetuning steps.
Read more7/16/2024

0
Affordance Perception by a Knowledge-Guided Vision-Language Model with Efficient Error Correction
Gertjan Burghouts, Marianne Schaaphok, Michael van Bekkum, Wouter Meijer, Fieke Hillerstrom, Jelle van Mil
Mobile robot platforms will increasingly be tasked with activities that involve grasping and manipulating objects in open world environments. Affordance understanding provides a robot with means to realise its goals and execute its tasks, e.g. to achieve autonomous navigation in unknown buildings where it has to find doors and ways to open these. In order to get actionable suggestions, robots need to be able to distinguish subtle differences between objects, as they may result in different action sequences: doorknobs require grasp and twist, while handlebars require grasp and push. In this paper, we improve affordance perception for a robot in an open-world setting. Our contribution is threefold: (1) We provide an affordance representation with precise, actionable affordances; (2) We connect this knowledge base to a foundational vision-language models (VLM) and prompt the VLM for a wider variety of new and unseen objects; (3) We apply a human-in-the-loop for corrections on the output of the VLM. The mix of affordance representation, image detection and a human-in-the-loop is effective for a robot to search for objects to achieve its goals. We have demonstrated this in a scenario of finding various doors and the many different ways to open them.
Read more7/19/2024