Text-driven Affordance Learning from Egocentric Vision
2404.02523
0
0

Abstract
Visual affordance learning is a key component for robots to understand how to interact with objects. Conventional approaches in this field rely on pre-defined objects and actions, falling short of capturing diverse interactions in realworld scenarios. The key idea of our approach is employing textual instruction, targeting various affordances for a wide range of objects. This approach covers both hand-object and tool-object interactions. We introduce text-driven affordance learning, aiming to learn contact points and manipulation trajectories from an egocentric view following textual instruction. In our task, contact points are represented as heatmaps, and the manipulation trajectory as sequences of coordinates that incorporate both linear and rotational movements for various manipulations. However, when we gather data for this task, manual annotations of these diverse interactions are costly. To this end, we propose a pseudo dataset creation pipeline and build a large pseudo-training dataset: TextAFF80K, consisting of over 80K instances of the contact points, trajectories, images, and text tuples. We extend existing referring expression comprehension models for our task, and experimental results show that our approach robustly handles multiple affordances, serving as a new standard for affordance learning in real-world scenarios.
Create account to get full access
Related Work
Visual Affordance Learning
Researchers have been exploring ways for machines to learn about the affordances, or possible actions, associated with objects and scenes in visual data. This involves teaching AI systems to understand not just what an object is, but what it can be used for. Previous work has looked at using visual information alone to learn affordances, but this paper explores incorporating text-based knowledge to improve this process.
Plain English Explanation
The key idea behind this research is to combine visual and textual information to help AI systems better understand the potential uses, or affordances, of objects and scenes. Rather than just recognizing what an object is, the goal is to teach the system what that object can be used for.
For example, a person might look at a cup and recognize it as a cup, but also understand that a cup can be used to hold liquids. By integrating visual data from cameras with text-based knowledge, the researchers aim to give AI systems a more comprehensive understanding of the world and the things in it.
This could have useful applications in areas like robotics, where a system needs to understand not just what objects are, but how to interact with them to complete tasks. It may also support more natural language interactions, where an AI assistant can reason about the affordances of objects to have more meaningful conversations.
Technical Explanation
The paper presents a deep learning architecture that takes in both visual and textual data to learn affordance representations. The visual input comes from egocentric, or first-person, camera footage, which provides a richer understanding of how objects can be interacted with from a human perspective.
The textual data comes from natural language descriptions associated with the visual inputs. By aligning the visual and textual information, the model can learn to ground language-based knowledge about affordances in the visual world.
The researchers evaluate their approach on several affordance-related tasks, including affordance recognition, affordance anticipation, and task completion. They find that the integrated visual-textual model outperforms approaches that use only visual or only textual data, demonstrating the value of this multimodal learning strategy.
Critical Analysis
The paper makes a strong case for the benefits of combining visual and textual information to improve affordance learning. However, the evaluation is primarily focused on controlled lab environments, and it's unclear how well the approach would generalize to more complex, real-world settings.
Additionally, the paper does not address potential biases or limitations that could arise from the textual data used to train the system. Language models can sometimes encode societal biases, which could then be reflected in the affordance knowledge learned by the system.
Further research is needed to explore the robustness and fairness of this approach, as well as its applicability to a broader range of real-world tasks and environments.
Conclusion
This research demonstrates the potential of integrating visual and textual data to give AI systems a more comprehensive understanding of object affordances. By grounding language-based knowledge in visual experiences, the approach can teach machines not just what things are, but how they can be used. While there are still challenges to address, this work represents an important step towards developing more capable and intuitive artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Self-Explainable Affordance Learning with Embodied Caption
Zhipeng Zhang, Zhimin Wei, Guolei Sun, Peng Wang, Luc Van Gool
0
0
In the field of visual affordance learning, previous methods mainly used abundant images or videos that delineate human behavior patterns to identify action possibility regions for object manipulation, with a variety of applications in robotic tasks. However, they encounter a main challenge of action ambiguity, illustrated by the vagueness like whether to beat or carry a drum, and the complexities involved in processing intricate scenes. Moreover, it is important for human intervention to rectify robot errors in time. To address these issues, we introduce Self-Explainable Affordance learning (SEA) with embodied caption. This innovation enables robots to articulate their intentions and bridge the gap between explainable vision-language caption and visual affordance learning. Due to a lack of appropriate dataset, we unveil a pioneering dataset and metrics tailored for this task, which integrates images, heatmaps, and embodied captions. Furthermore, we propose a novel model to effectively combine affordance grounding with self-explanation in a simple but efficient manner. Extensive quantitative and qualitative experiments demonstrate our method's effectiveness.
4/9/2024
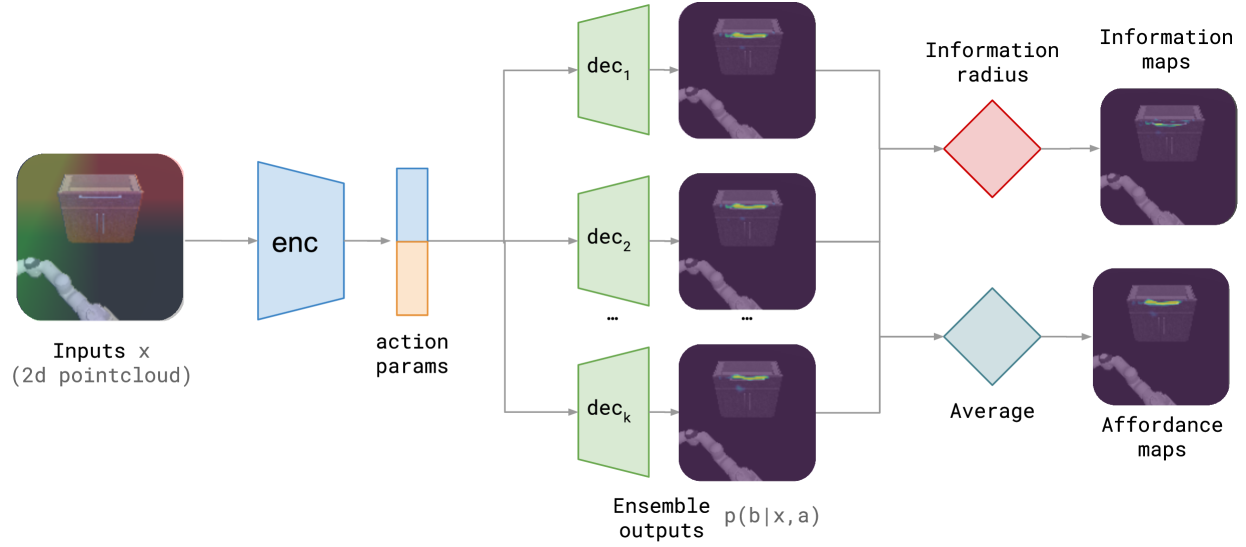
Information-driven Affordance Discovery for Efficient Robotic Manipulation
Pietro Mazzaglia, Taco Cohen, Daniel Dijkman
0
0
Robotic affordances, providing information about what actions can be taken in a given situation, can aid robotic manipulation. However, learning about affordances requires expensive large annotated datasets of interactions or demonstrations. In this work, we argue that well-directed interactions with the environment can mitigate this problem and propose an information-based measure to augment the agent's objective and accelerate the affordance discovery process. We provide a theoretical justification of our approach and we empirically validate the approach both in simulation and real-world tasks. Our method, which we dub IDA, enables the efficient discovery of visual affordances for several action primitives, such as grasping, stacking objects, or opening drawers, strongly improving data efficiency in simulation, and it allows us to learn grasping affordances in a small number of interactions, on a real-world setup with a UFACTORY XArm 6 robot arm.
6/7/2024

RAIL: Robot Affordance Imagination with Large Language Models
Ceng Zhang, Xin Meng, Dongchen Qi, Gregory S. Chirikjian
0
0
This paper introduces an automatic affordance reasoning paradigm tailored to minimal semantic inputs, addressing the critical challenges of classifying and manipulating unseen classes of objects in household settings. Inspired by human cognitive processes, our method integrates generative language models and physics-based simulators to foster analytical thinking and creative imagination of novel affordances. Structured with a tripartite framework consisting of analysis, imagination, and evaluation, our system analyzes the requested affordance names into interaction-based definitions, imagines the virtual scenarios, and evaluates the object affordance. If an object is recognized as possessing the requested affordance, our method also predicts the optimal pose for such functionality, and how a potential user can interact with it. Tuned on only a few synthetic examples across 3 affordance classes, our pipeline achieves a very high success rate on affordance classification and functional pose prediction of 8 classes of novel objects, outperforming learning-based baselines. Validation through real robot manipulating experiments demonstrates the practical applicability of the imagined user interaction, showcasing the system's ability to independently conceptualize unseen affordances and interact with new objects and scenarios in everyday settings.
6/10/2024
🤖
Uncertainty-driven Affordance Discovery for Efficient Robotics Manipulation
Pietro Mazzaglia, Taco Cohen, Daniel Dijkman
0
0
Robotics affordances, providing information about what actions can be taken in a given situation, can aid robotics manipulation. However, learning about affordances requires expensive large annotated datasets of interactions or demonstrations. In this work, we show active learning can mitigate this problem and propose the use of uncertainty to drive an interactive affordance discovery process. We show that our method enables the efficient discovery of visual affordances for several action primitives, such as grasping, stacking objects, or opening drawers, strongly improving data efficiency and allowing us to learn grasping affordances on a real-world setup with an xArm 6 robot arm in a small number of trials.
6/6/2024