Open-vocabulary object 6D pose estimation
2312.00690
0
0
🚀
Abstract
We introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest. In contrast to existing approaches, in our setting (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g., CAD or video sequence) is required at inference, and (iii) the object is imaged from two RGBD viewpoints of different scenes. To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from the scenes and to estimate its relative 6D pose. The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts. We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 34 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes. Code and dataset are available at https://jcorsetti.github.io/oryon.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a novel approach for open-vocabulary 6D object pose estimation
- Utilizes language models to enable pose estimation for any object, not just pre-defined categories
- Combines 2D and 3D cues to accurately predict the 6D pose (position and orientation) of objects
- Demonstrates strong performance on various benchmarks, outperforming prior state-of-the-art methods
Plain English Explanation
This research paper presents a new method for estimating the 6D pose (position and orientation) of objects in 3D space. Unlike previous approaches that could only handle a fixed set of predefined object categories, this method can work with any object, even ones it has never seen before.
The key insight is to use language models, which are AI systems trained on vast amounts of text data. These models can understand the meaning and relationships between words, allowing the system to recognize and reason about objects even if it hasn't been explicitly trained on them. By combining this linguistic knowledge with visual cues from 2D images and 3D data, the researchers developed a system that can accurately predict the full 6D pose of any object, not just a limited set.
This open-vocabulary capability is important because the real world contains an immense variety of objects, far more than any single AI system could be explicitly trained on. By leveraging language understanding, this method allows for much more flexible and versatile 6D pose estimation, with applications in areas like robotics, augmented reality, and autonomous systems.
Technical Explanation
The proposed approach, called [object Object], uses a two-stage architecture. First, it generates a set of 2D object proposals from the input image using a Region Proposal Network (RPN). These proposals are then classified and associated with textual object descriptions using a language model.
In the second stage, the system uses the 2D object proposals and associated language features to estimate the full 6D pose of each object. This is done by predicting the 3D bounding box and 3D keypoints of the object, which are then used to compute the 6D pose. The 3D reasoning is enabled by fusing the 2D and language-based features with additional 3D data, such as depth maps or point clouds.
The researchers evaluated their method on several benchmark datasets, including [object Object] and [object Object], and showed that it outperforms previous state-of-the-art approaches for open-vocabulary 6D pose estimation.
Critical Analysis
The key strength of this work is its ability to handle a wide range of objects, not just a predefined set. This is a significant advance over prior methods, which were limited to a fixed number of categories. By leveraging language understanding, the system can adapt to new objects without retraining.
However, the paper does not extensively discuss the limitations of this approach. For example, it's unclear how well the system would perform on highly unusual or novel objects, or how it would handle ambiguity or uncertainty in the language descriptions. Additionally, the computational and memory requirements of the language model could be a concern for real-time or resource-constrained applications.
Further research could explore ways to make the language-based reasoning more robust and efficient, as well as investigate the system's performance on a wider range of objects and scenarios. Incorporating active learning or few-shot adaptation techniques could also help expand the system's capabilities.
Conclusion
Overall, this work represents a significant step forward in the field of 6D object pose estimation. By enabling open-vocabulary capabilities, it opens the door for more flexible and versatile applications in areas such as robotics, augmented reality, and autonomous systems. The strong performance on benchmark datasets suggests that this approach could have a meaningful impact, particularly in scenarios where the diversity of objects is a key challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Open-Pose 3D Zero-Shot Learning: Benchmark and Challenges
Weiguang Zhao, Guanyu Yang, Rui Zhang, Chenru Jiang, Chaolong Yang, Yuyao Yan, Amir Hussain, Kaizhu Huang
0
0
With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, methods transferring language or language-image pre-training models like Contrastive Language-Image Pre-training (CLIP) to 3D vision have made significant progress in the 3D zero-shot classification task. These methods primarily focus on 3D object classification with an aligned pose; such a setting is, however, rather restrictive, which overlooks the recognition of 3D objects with open poses typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more realistic and challenging scenario named open-pose 3D zero-shot classification, focusing on the recognition of 3D objects regardless of their orientation. First, we revisit the current research on 3D zero-shot classification, and propose two benchmark datasets specifically designed for the open-pose setting. We empirically validate many of the most popular methods in the proposed open-pose benchmark. Our investigations reveal that most current 3D zero-shot classification models suffer from poor performance, indicating a substantial exploration room towards the new direction. Furthermore, we study a concise pipeline with an iterative angle refinement mechanism that automatically optimizes one ideal angle to classify these open-pose 3D objects. In particular, to make validation more compelling and not just limited to existing CLIP-based methods, we also pioneer the exploration of knowledge transfer based on Diffusion models. While the proposed solutions can serve as a new benchmark for open-pose 3D zero-shot classification, we discuss the complexities and challenges of this scenario that remain for further research development. The code is available publicly at https://github.com/weiguangzhao/Diff-OP3D.
4/17/2024
🎯
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
Haixin Shi, Yinlin Hu, Daniel Koguciuk, Juan-Ting Lin, Mathieu Salzmann, David Ferstl
0
0
We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
5/13/2024
🤔
The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding
Lorenzo Bianchi, Fabio Carrara, Nicola Messina, Claudio Gennaro, Fabrizio Falchi
0
0
Recent advancements in large vision-language models enabled visual object detection in open-vocabulary scenarios, where object classes are defined in free-text formats during inference. In this paper, we aim to probe the state-of-the-art methods for open-vocabulary object detection to determine to what extent they understand fine-grained properties of objects and their parts. To this end, we introduce an evaluation protocol based on dynamic vocabulary generation to test whether models detect, discern, and assign the correct fine-grained description to objects in the presence of hard-negative classes. We contribute with a benchmark suite of increasing difficulty and probing different properties like color, pattern, and material. We further enhance our investigation by evaluating several state-of-the-art open-vocabulary object detectors using the proposed protocol and find that most existing solutions, which shine in standard open-vocabulary benchmarks, struggle to accurately capture and distinguish finer object details. We conclude the paper by highlighting the limitations of current methodologies and exploring promising research directions to overcome the discovered drawbacks. Data and code are available at https://lorebianchi98.github.io/FG-OVD/.
4/9/2024
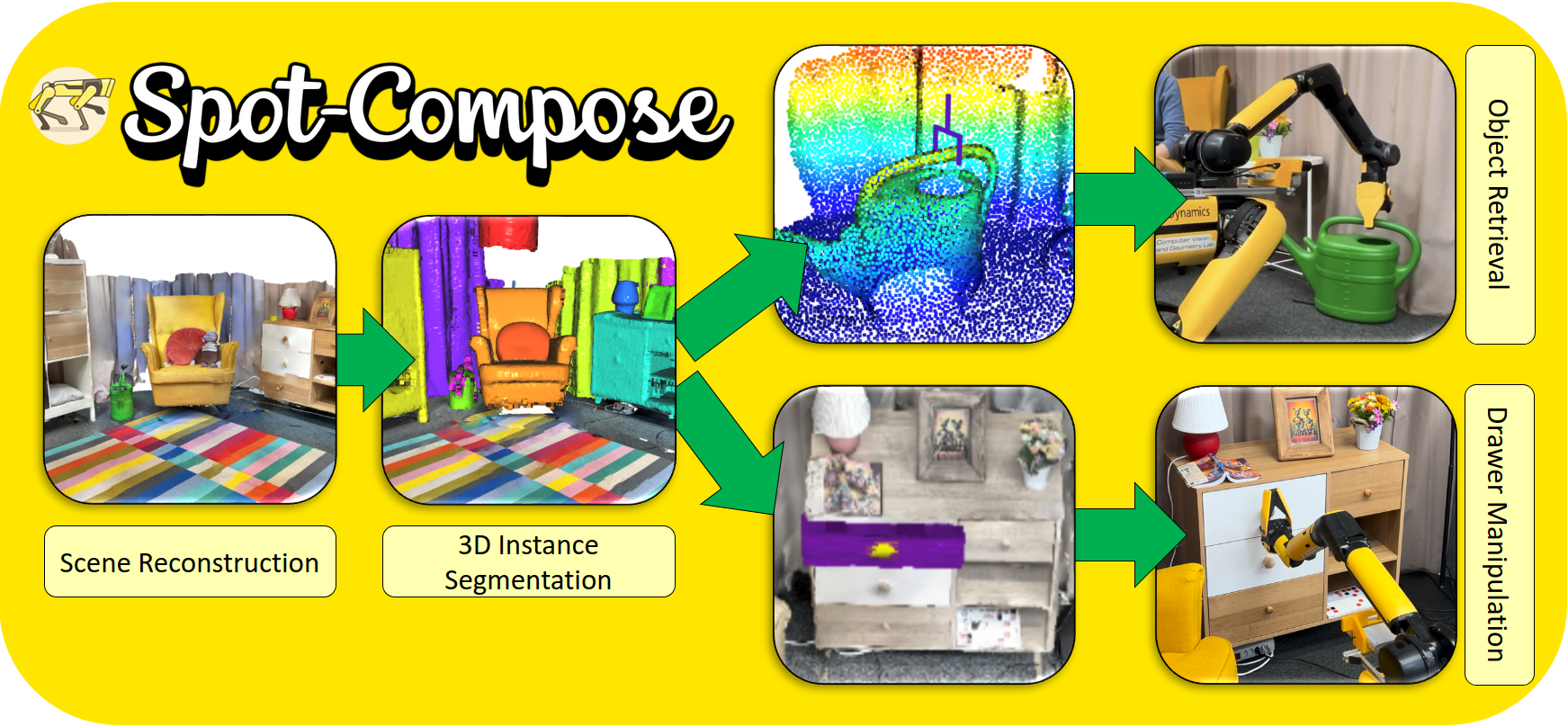
Spot-Compose: A Framework for Open-Vocabulary Object Retrieval and Drawer Manipulation in Point Clouds
Oliver Lemke, Zuria Bauer, Ren'e Zurbrugg, Marc Pollefeys, Francis Engelmann, Hermann Blum
0
0
In recent years, modern techniques in deep learning and large-scale datasets have led to impressive progress in 3D instance segmentation, grasp pose estimation, and robotics. This allows for accurate detection directly in 3D scenes, object- and environment-aware grasp prediction, as well as robust and repeatable robotic manipulation. This work aims to integrate these recent methods into a comprehensive framework for robotic interaction and manipulation in human-centric environments. Specifically, we leverage 3D reconstructions from a commodity 3D scanner for open-vocabulary instance segmentation, alongside grasp pose estimation, to demonstrate dynamic picking of objects, and opening of drawers. We show the performance and robustness of our model in two sets of real-world experiments including dynamic object retrieval and drawer opening, reporting a 51% and 82% success rate respectively. Code of our framework as well as videos are available on: https://spot-compose.github.io/.
4/22/2024