On Overcoming Miscalibrated Conversational Priors in LLM-based Chatbots

0
➖
Sign in to get full access
Overview
• The paper explores the use of Large Language Model (LLM) based chatbots to power recommender systems. • The authors observe that LLM chatbots respond poorly to under-specified requests, making incorrect assumptions, hedging with long responses, or refusing to answer. • The authors conjecture that these miscalibrated response tendencies (conversational priors) can be attributed to LLM fine-tuning using single-turn annotations that do not capture multi-turn conversation utility.
Plain English Explanation
• The paper looks at using advanced language models, called Large Language Models (LLMs), to build chatbots that can power recommendation systems. • The researchers found that these LLM chatbots don't perform well when users make vague or incomplete requests. The chatbots may make wrong guesses, give long and uncertain responses, or refuse to answer. • The authors think this is because the LLMs were trained on annotations (labels) for individual conversational turns, which may not reflect how useful the full conversation would be for making recommendations. The annotators' preferences may also not match real users' needs.
Technical Explanation
• The authors first analyze public LLM chat logs to conclude that query under-specification (vague requests) is common. • They then study synthetic recommendation problems with configurable item utilities, framing them as Partially Observed Decision Processes (PODPs). • They find that pre-trained LLMs can be sub-optimal for PODPs and derive better policies that clarify under-specified queries when appropriate. • To improve the LLMs, the authors re-calibrate them by prompting with learned control messages to approximate the improved policy. • They show empirically that this lightweight learning approach effectively uses logged conversation data to re-calibrate the response strategies of LLM-based chatbots for recommendation tasks.
Critical Analysis
• The paper acknowledges the limitations of using single-turn annotations to fine-tune LLMs for multi-turn recommendation tasks. • While the authors propose an approach to re-calibrate the LLMs, it is not clear how scalable or generalizable this method would be across different recommendation domains. • The synthetic PODP experiments provide useful insights, but more real-world evaluation would be needed to assess the practical impact of the proposed techniques. • Further research could explore alternative training approaches, such as reinforcement learning or multi-task learning, to better align LLM-based chatbots with the goals of recommendation systems.
Conclusion
• The paper highlights the challenges of using LLM-based chatbots for recommendation tasks, particularly with respect to handling under-specified user requests. • The proposed re-calibration approach offers a lightweight way to improve the conversational priors of LLMs, but more research is needed to fully address the misalignment between single-turn annotations and multi-turn recommendation utility. • Advances in this area could lead to more effective and user-friendly recommender systems powered by large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
On Overcoming Miscalibrated Conversational Priors in LLM-based Chatbots
Christine Herlihy, Jennifer Neville, Tobias Schnabel, Adith Swaminathan
We explore the use of Large Language Model (LLM-based) chatbots to power recommender systems. We observe that the chatbots respond poorly when they encounter under-specified requests (e.g., they make incorrect assumptions, hedge with a long response, or refuse to answer). We conjecture that such miscalibrated response tendencies (i.e., conversational priors) can be attributed to LLM fine-tuning using annotators -- single-turn annotations may not capture multi-turn conversation utility, and the annotators' preferences may not even be representative of users interacting with a recommender system. We first analyze public LLM chat logs to conclude that query under-specification is common. Next, we study synthetic recommendation problems with configurable latent item utilities and frame them as Partially Observed Decision Processes (PODP). We find that pre-trained LLMs can be sub-optimal for PODPs and derive better policies that clarify under-specified queries when appropriate. Then, we re-calibrate LLMs by prompting them with learned control messages to approximate the improved policy. Finally, we show empirically that our lightweight learning approach effectively uses logged conversation data to re-calibrate the response strategies of LLM-based chatbots for recommendation tasks.
Read more6/5/2024
2
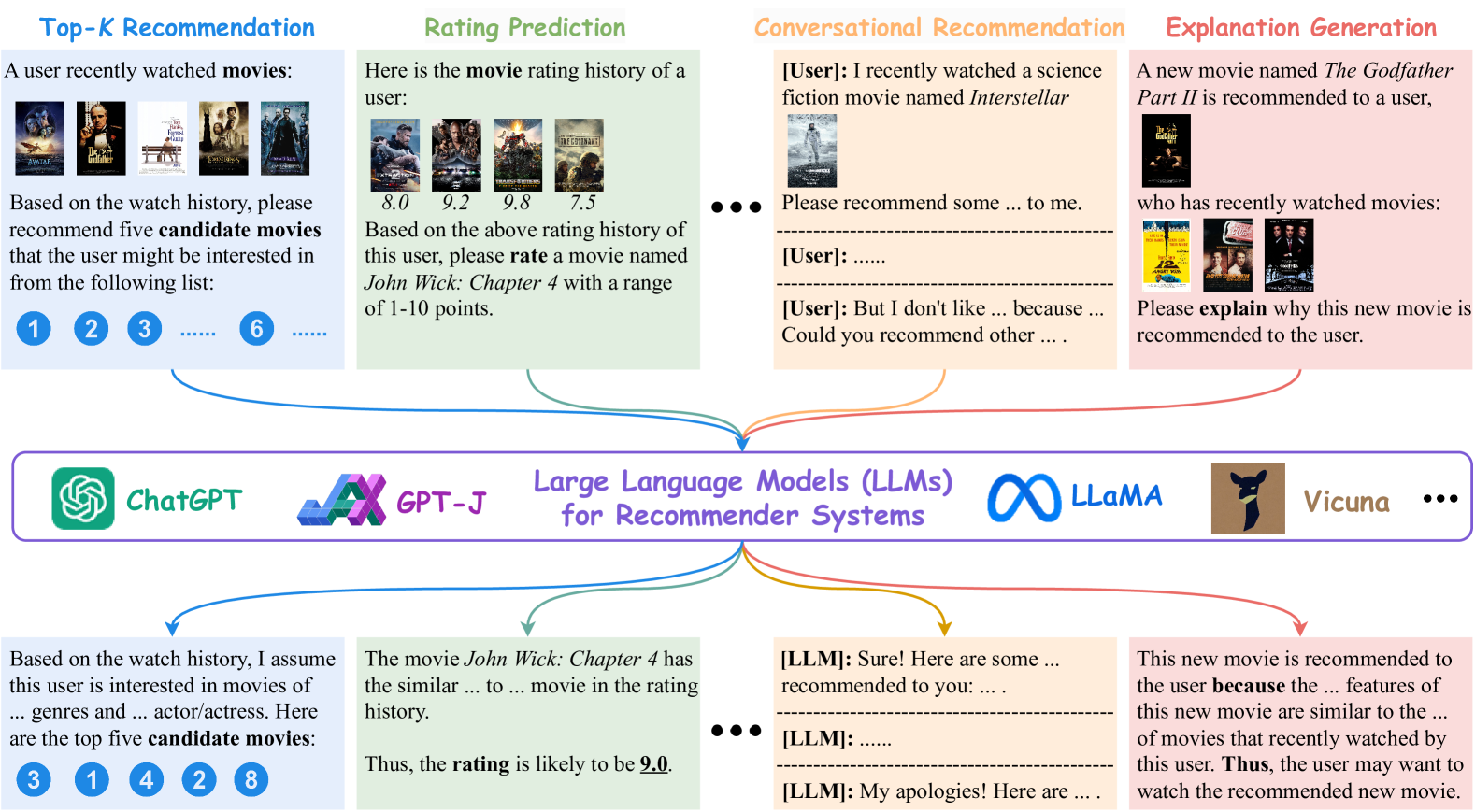
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
Read more4/23/2024
0
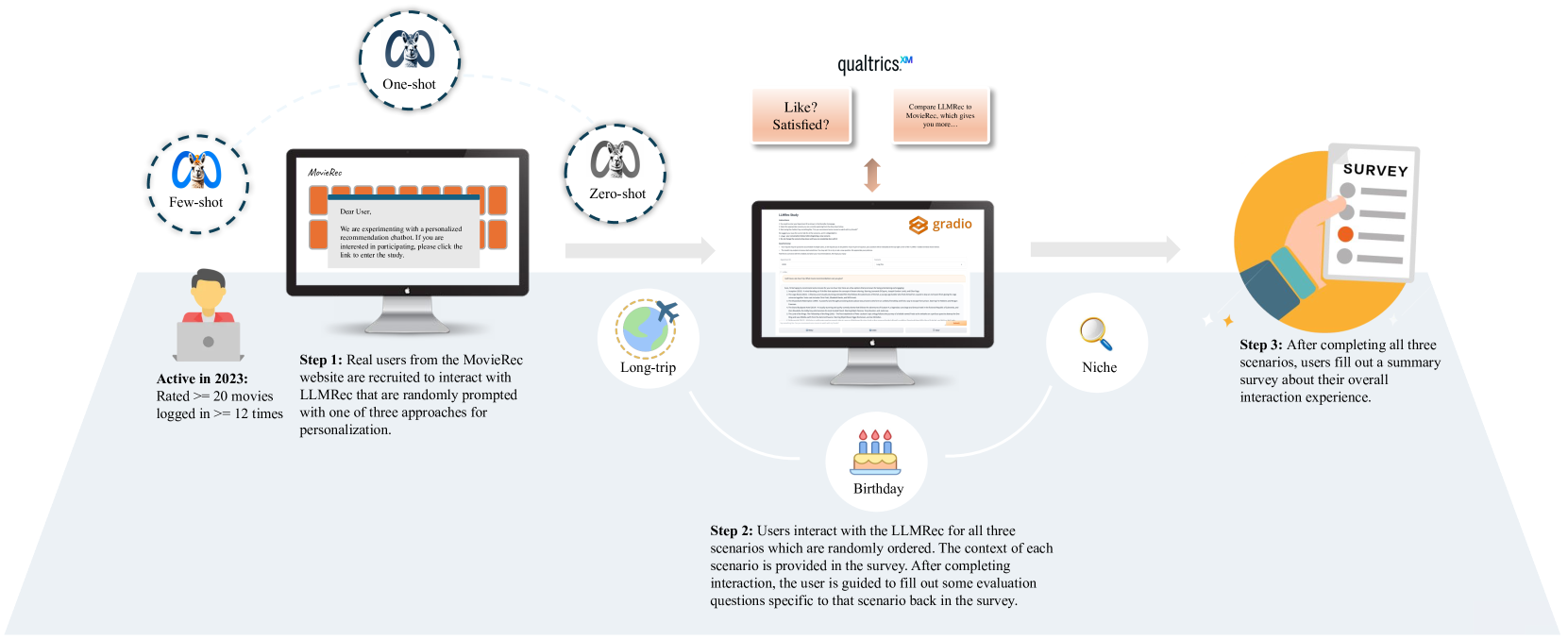
Large Language Models as Conversational Movie Recommenders: A User Study
Ruixuan Sun, Xinyi Li, Avinash Akella, Joseph A. Konstan
This paper explores the effectiveness of using large language models (LLMs) for personalized movie recommendations from users' perspectives in an online field experiment. Our study involves a combination of between-subject prompt and historic consumption assessments, along with within-subject recommendation scenario evaluations. By examining conversation and survey response data from 160 active users, we find that LLMs offer strong recommendation explainability but lack overall personalization, diversity, and user trust. Our results also indicate that different personalized prompting techniques do not significantly affect user-perceived recommendation quality, but the number of movies a user has watched plays a more significant role. Furthermore, LLMs show a greater ability to recommend lesser-known or niche movies. Through qualitative analysis, we identify key conversational patterns linked to positive and negative user interaction experiences and conclude that providing personal context and examples is crucial for obtaining high-quality recommendations from LLMs.
Read more5/1/2024
0
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
Read more4/30/2024