Pre-training Point Cloud Compact Model with Partial-aware Reconstruction

0

Sign in to get full access
Overview
- This paper presents a novel approach for pre-training a compact point cloud model with partial-aware reconstruction.
- The proposed method aims to learn a more efficient and robust representation of 3D point clouds by considering partial information during the pre-training stage.
- The model leverages a masked autoencoder architecture to capture the underlying structure and context of point clouds, while also being aware of the missing regions.
Plain English Explanation
The paper introduces a new way to train a machine learning model that can efficiently represent and understand 3D point cloud data. Point clouds are digital representations of physical objects or environments, made up of a collection of individual data points in 3D space.
The key idea is to use a masked autoencoder approach during the pre-training stage. This means the model is trained to reconstruct the complete 3D point cloud from a partially-masked version of the input. By learning to fill in the missing parts of the point cloud, the model develops a deeper understanding of the underlying structure and context of the 3D data.
This partial-aware pre-training helps the model learn a more compact and robust representation of point clouds, which can then be used for various downstream tasks, such as 3D object recognition, scene understanding, or shape completion. The authors show that this approach outperforms traditional pre-training methods and leads to improved performance on several benchmark tasks.
Technical Explanation
The proposed method builds on the success of masked autoencoder (MAE) architectures for point cloud representation learning. The key innovation is the introduction of a "partial-aware" pre-training strategy.
During pre-training, the model is presented with a partially-masked version of the input point cloud, where a random subset of the points are removed. The model is then trained to reconstruct the complete point cloud from this partial input. This encourages the model to learn features that are robust to missing information and to understand the underlying structure of the 3D data.
The authors leverage a transformer-based encoder-decoder architecture, similar to recent work on point cloud MAEs. The encoder takes the partial point cloud as input and produces a compact latent representation, while the decoder reconstructs the complete point cloud from this latent code.
Experiments on several benchmark datasets demonstrate the effectiveness of the proposed partial-aware pre-training approach. The authors show that the pre-trained model outperforms traditional pre-training methods and achieves state-of-the-art results on point cloud classification, segmentation, and completion tasks.
Critical Analysis
The paper presents a well-designed and carefully evaluated approach for pre-training compact point cloud models. The key strengths are the partial-aware pre-training strategy and the use of a transformer-based architecture, which have both been shown to be effective for 3D data representation learning.
However, the paper does not extensively discuss the limitations or potential drawbacks of the proposed method. For example, the impact of the masking ratio (i.e., the proportion of points that are randomly removed during pre-training) on the final model performance is not thoroughly investigated. Additionally, the authors do not compare their approach to other recently proposed point cloud MAE models, such as ExpPointMAE or LCM, which could provide additional insights.
Further research could also explore the transferability of the pre-trained model to different downstream tasks or its performance on more diverse and challenging point cloud datasets. Investigating the model's interpretability and the latent representations learned during pre-training could also yield valuable insights.
Conclusion
This paper presents a novel approach for pre-training compact point cloud models with a focus on partial-aware reconstruction. The proposed method leverages a masked autoencoder architecture to learn a more efficient and robust representation of 3D point clouds, taking into account the presence of missing information.
The authors demonstrate that this partial-aware pre-training strategy leads to improved performance on a range of point cloud processing tasks, outperforming traditional pre-training methods. This work contributes to the ongoing efforts in the field of 3D deep learning to develop more accurate and compact models for various applications, such as autonomous navigation, augmented reality, and digital twinning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pre-training Point Cloud Compact Model with Partial-aware Reconstruction
Yaohua Zha, Yanzi Wang, Tao Dai, Shu-Tao Xia
The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, two drawbacks hinder their practical application. Firstly, the positional embedding of masked patches in the decoder results in the leakage of their central coordinates, leading to limited 3D representations. Secondly, the excessive model size of existing MPM methods results in higher demands for devices. To address these, we propose to pre-train Point cloud Compact Model with Partial-aware textbf{R}econstruction, named Point-CPR. Specifically, in the decoder, we couple the vanilla masked tokens with their positional embeddings as randomly masked queries and introduce a partial-aware prediction module before each decoder layer to predict them from the unmasked partial. It prevents the decoder from creating a shortcut between the central coordinates of masked patches and their reconstructed coordinates, enhancing the robustness of models. We also devise a compact encoder composed of local aggregation and MLPs, reducing the parameters and computational requirements compared to existing Transformer-based encoders. Extensive experiments demonstrate that our model exhibits strong performance across various tasks, especially surpassing the leading MPM-based model PointGPT-B with only 2% of its parameters.
Read more7/15/2024

0
LCM: Locally Constrained Compact Point Cloud Model for Masked Point Modeling
Yaohua Zha, Naiqi Li, Yanzi Wang, Tao Dai, Hang Guo, Bin Chen, Zhi Wang, Zhihao Ouyang, Shu-Tao Xia
The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, these models heavily rely on the Transformer, leading to quadratic complexity and limited decoder, hindering their practice application. To address this limitation, we first conduct a comprehensive analysis of existing Transformer-based MPM, emphasizing the idea that redundancy reduction is crucial for point cloud analysis. To this end, we propose a Locally constrained Compact point cloud Model (LCM) consisting of a locally constrained compact encoder and a locally constrained Mamba-based decoder. Our encoder replaces self-attention with our local aggregation layers to achieve an elegant balance between performance and efficiency. Considering the varying information density between masked and unmasked patches in the decoder inputs of MPM, we introduce a locally constrained Mamba-based decoder. This decoder ensures linear complexity while maximizing the perception of point cloud geometry information from unmasked patches with higher information density. Extensive experimental results show that our compact model significantly surpasses existing Transformer-based models in both performance and efficiency, especially our LCM-based Point-MAE model, compared to the Transformer-based model, achieved an improvement of 2.24%, 0.87%, and 0.94% in performance on the three variants of ScanObjectNN while reducing parameters by 88% and computation by 73%.
Read more5/28/2024
✨
0
3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining
Siming Yan, Yuqi Yang, Yuxiao Guo, Hao Pan, Peng-shuai Wang, Xin Tong, Yang Liu, Qixing Huang
Masked autoencoders (MAE) have recently been introduced to 3D self-supervised pretraining for point clouds due to their great success in NLP and computer vision. Unlike MAEs used in the image domain, where the pretext task is to restore features at the masked pixels, such as colors, the existing 3D MAE works reconstruct the missing geometry only, i.e, the location of the masked points. In contrast to previous studies, we advocate that point location recovery is inessential and restoring intrinsic point features is much superior. To this end, we propose to ignore point position reconstruction and recover high-order features at masked points including surface normals and surface variations, through a novel attention-based decoder which is independent of the encoder design. We validate the effectiveness of our pretext task and decoder design using different encoder structures for 3D training and demonstrate the advantages of our pretrained networks on various point cloud analysis tasks.
Read more4/30/2024
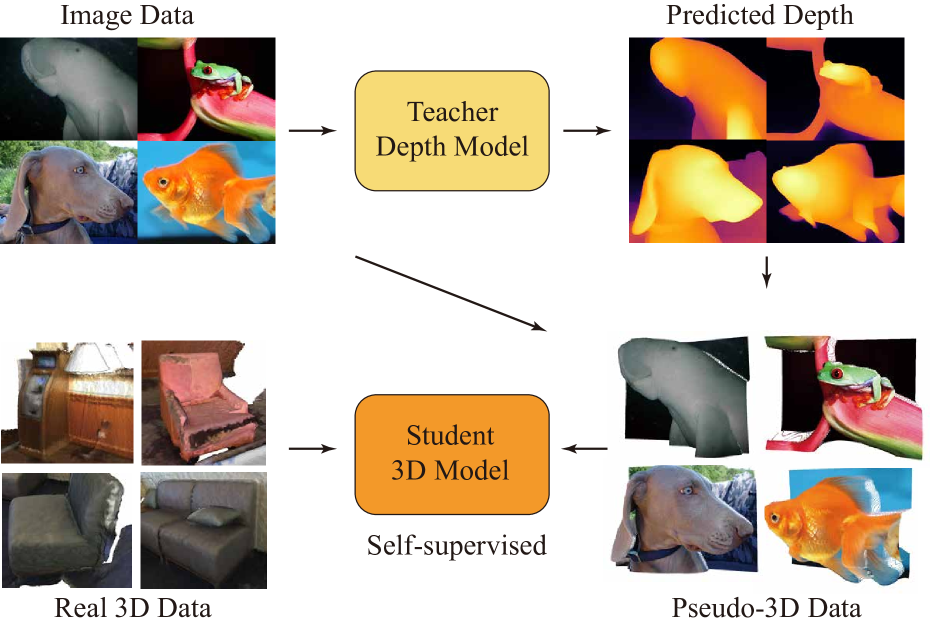
0
P3P: Pseudo-3D Pre-training for Scaling 3D Masked Autoencoders
Xuechao Chen, Ying Chen, Jialin Li, Qiang Nie, Yong Liu, Qixing Huang, Yang Li
3D pre-training is crucial to 3D perception tasks. However, limited by the difficulties in collecting clean 3D data, 3D pre-training consistently faced data scaling challenges. Inspired by semi-supervised learning leveraging limited labeled data and a large amount of unlabeled data, in this work, we propose a novel self-supervised pre-training framework utilizing the real 3D data and the pseudo-3D data lifted from images by a large depth estimation model. Another challenge lies in the efficiency. Previous methods such as Point-BERT and Point-MAE, employ k nearest neighbors to embed 3D tokens, requiring quadratic time complexity. To efficiently pre-train on such a large amount of data, we propose a linear-time-complexity token embedding strategy and a training-efficient 2D reconstruction target. Our method achieves state-of-the-art performance in 3D classification and few-shot learning while maintaining high pre-training and downstream fine-tuning efficiency.
Read more8/20/2024