PanopticRecon: Leverage Open-vocabulary Instance Segmentation for Zero-shot Panoptic Reconstruction

0

Sign in to get full access
Overview
• This paper presents a novel method called PanopticRecon that leverages open-vocabulary instance segmentation to enable zero-shot panoptic reconstruction.
• PanopticRecon combines 2D open-vocabulary instance segmentation with depth data to reconstruct 3D panoptic scenes, without requiring any pre-defined category labels or 3D annotations.
• The key innovation is the use of open-vocabulary segmentation, which allows the system to recognize and segment a wide range of object categories, going beyond the predefined set typically used in conventional panoptic segmentation.
Plain English Explanation
In this research, the authors have developed a new technique called PanopticRecon that can create detailed 3D models of scenes by combining 2D object recognition with depth information. This is an important advancement because typical 3D scene reconstruction methods are limited to a predefined set of object categories.
PanopticRecon overcomes this limitation by using an "open-vocabulary" approach to 2D object segmentation, which means it can recognize and segment a much wider range of object types, not just the ones it was specifically trained on. This open-vocabulary capability is then leveraged to build 3D models that capture the full complexity of real-world scenes, without being constrained by predefined category labels.
The key idea is to take the detailed 2D object segmentation information and combine it with depth data from sensors to construct a full 3D panoptic reconstruction of the scene. This allows the system to build rich 3D models that faithfully represent the diverse array of objects and elements present, going beyond what is possible with conventional 3D reconstruction techniques.
Technical Explanation
PanopticRecon builds on recent advances in open-vocabulary instance segmentation and depth-aware panoptic segmentation to enable zero-shot panoptic reconstruction of 3D scenes.
The system first performs 2D open-vocabulary instance segmentation on input images, which can recognize a wide range of object categories without being limited to a predefined set. It then combines this rich 2D segmentation information with depth data to reconstruct a full 3D panoptic model of the scene.
This approach contrasts with prior work on 3D panoptic segmentation and 2D-3D semantic reconstruction, which have been constrained by the object categories available in their training data. By leveraging open-vocabulary segmentation, PanopticRecon can handle a much broader range of object types, leading to more comprehensive 3D scene reconstructions.
Critical Analysis
The paper presents a compelling approach for leveraging advances in 2D open-vocabulary segmentation to enable more flexible and comprehensive 3D scene reconstruction. However, the authors acknowledge that PanopticRecon's performance is still limited by the accuracy and coverage of the underlying 2D segmentation model.
Additionally, the system currently relies on accurate depth data, which may not always be available in real-world scenarios. Developing techniques to handle more diverse or incomplete depth information could further enhance the practicality of the approach.
While the paper demonstrates promising results, more research is needed to fully explore the potential of open-vocabulary 3D reconstruction and its applications in areas like robotics, augmented reality, and digital twin modeling. Incorporating semantic reasoning and physical priors into the reconstruction process could also lead to more coherent and semantically meaningful 3D models.
Conclusion
The PanopticRecon method represents a significant step forward in 3D scene reconstruction by leveraging open-vocabulary instance segmentation to enable zero-shot panoptic reconstruction. This approach allows for the creation of rich, detailed 3D models that faithfully capture the diverse elements of real-world scenes, going beyond the limitations of traditional 3D reconstruction techniques.
The implications of this research are far-reaching, as comprehensive 3D scene understanding is a crucial capability for applications ranging from robotics and autonomous vehicles to augmented reality and digital twin modeling. By breaking free from predefined object categories, PanopticRecon paves the way for more flexible and adaptable 3D perception, with the potential to transform how we interact with and model the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PanopticRecon: Leverage Open-vocabulary Instance Segmentation for Zero-shot Panoptic Reconstruction
Xuan Yu, Yili Liu, Chenrui Han, Sitong Mao, Shunbo Zhou, Rong Xiong, Yiyi Liao, Yue Wang
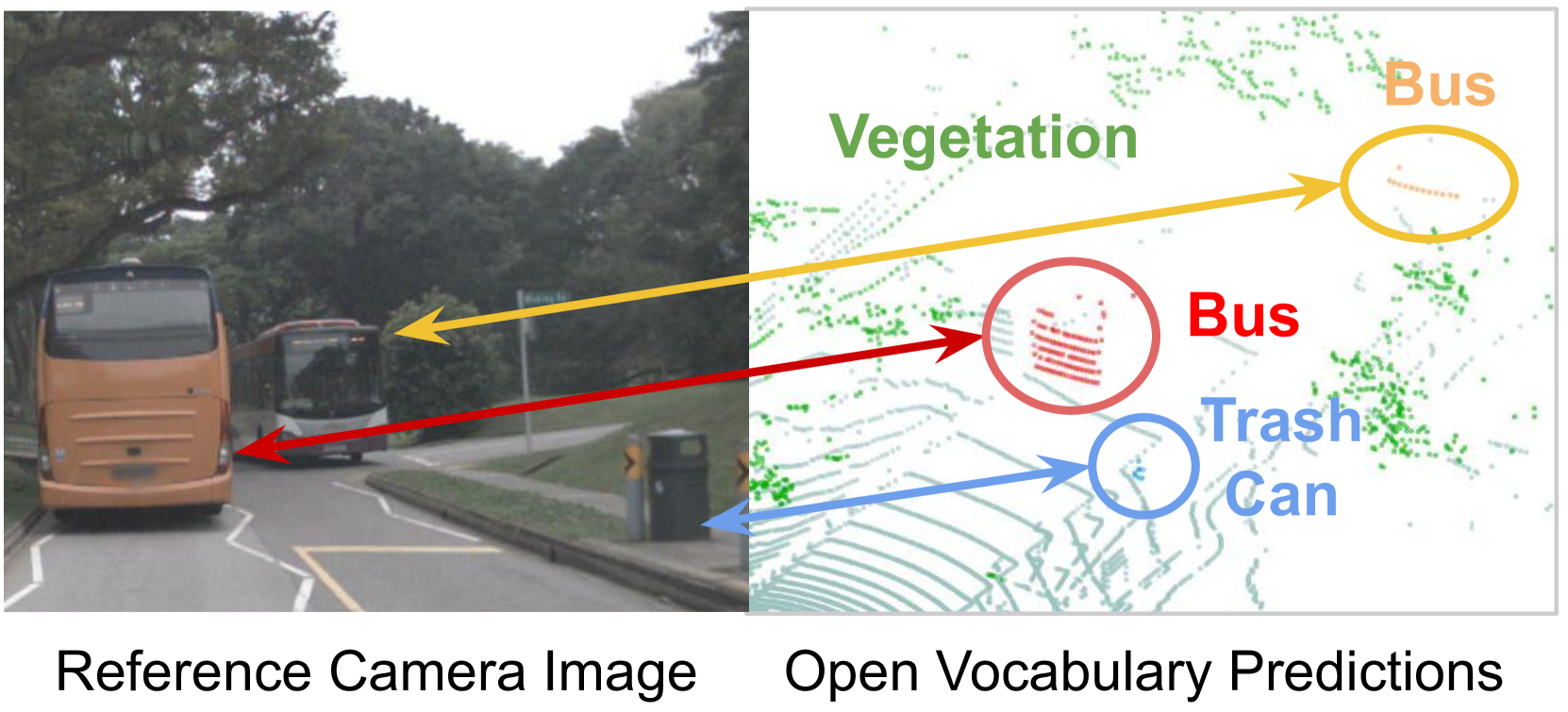
Panoptic reconstruction is a challenging task in 3D scene understanding. However, most existing methods heavily rely on pre-trained semantic segmentation models and known 3D object bounding boxes for 3D panoptic segmentation, which is not available for in-the-wild scenes. In this paper, we propose a novel zero-shot panoptic reconstruction method from RGB-D images of scenes. For zero-shot segmentation, we leverage open-vocabulary instance segmentation, but it has to face partial labeling and instance association challenges. We tackle both challenges by propagating partial labels with the aid of dense generalized features and building a 3D instance graph for associating 2D instance IDs. Specifically, we exploit partial labels to learn a classifier for generalized semantic features to provide complete labels for scenes with dense distilled features. Moreover, we formulate instance association as a 3D instance graph segmentation problem, allowing us to fully utilize the scene geometry prior and all 2D instance masks to infer global unique pseudo 3D instance ID. Our method outperforms state-of-the-art methods on the indoor dataset ScanNet V2 and the outdoor dataset KITTI-360, demonstrating the effectiveness of our graph segmentation method and reconstruction network.
Read more7/2/2024
0
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Zihao Xiao, Longlong Jing, Shangxuan Wu, Alex Zihao Zhu, Jingwei Ji, Chiyu Max Jiang, Wei-Chih Hung, Thomas Funkhouser, Weicheng Kuo, Anelia Angelova, Yin Zhou, Shiwei Sheng
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
Read more4/4/2024
🌀
0
Depth-aware Panoptic Segmentation
Tuan Nguyen, Max Mehltretter, Franz Rottensteiner
Panoptic segmentation unifies semantic and instance segmentation and thus delivers a semantic class label and, for so-called thing classes, also an instance label per pixel. The differentiation of distinct objects of the same class with a similar appearance is particularly challenging and frequently causes such objects to be incorrectly assigned to a single instance. In the present work, we demonstrate that information on the 3D geometry of the observed scene can be used to mitigate this issue: We present a novel CNN-based method for panoptic segmentation which processes RGB images and depth maps given as input in separate network branches and fuses the resulting feature maps in a late fusion manner. Moreover, we propose a new depth-aware dice loss term which penalises the assignment of pixels to the same thing instance based on the difference between their associated distances to the camera. Experiments carried out on the Cityscapes dataset show that the proposed method reduces the number of objects that are erroneously merged into one thing instance and outperforms the method used as basis by 2.2% in terms of panoptic quality.
Read more5/21/2024

0
PanoSSC: Exploring Monocular Panoptic 3D Scene Reconstruction for Autonomous Driving
Yining Shi, Jiusi Li, Kun Jiang, Ke Wang, Yunlong Wang, Mengmeng Yang, Diange Yang
Vision-centric occupancy networks, which represent the surrounding environment with uniform voxels with semantics, have become a new trend for safe driving of camera-only autonomous driving perception systems, as they are able to detect obstacles regardless of their shape and occlusion. Modern occupancy networks mainly focus on reconstructing visible voxels from object surfaces with voxel-wise semantic prediction. Usually, they suffer from inconsistent predictions of one object and mixed predictions for adjacent objects. These confusions may harm the safety of downstream planning modules. To this end, we investigate panoptic segmentation on 3D voxel scenarios and propose an instance-aware occupancy network, PanoSSC. We predict foreground objects and backgrounds separately and merge both in post-processing. For foreground instance grouping, we propose a novel 3D instance mask decoder that can efficiently extract individual objects. we unify geometric reconstruction, 3D semantic segmentation, and 3D instance segmentation into PanoSSC framework and propose new metrics for evaluating panoptic voxels. Extensive experiments show that our method achieves competitive results on SemanticKITTI semantic scene completion benchmark.
Read more6/12/2024