Parameter-Efficient Instruction Tuning of Large Language Models For Extreme Financial Numeral Labelling

0
💬
Sign in to get full access
Overview
- The paper investigates using large language models (LLMs) to automatically annotate relevant financial metrics (GAAP metrics) in financial documents with their corresponding XBRL tags.
- It explores a generative approach to this "extreme classification" problem, leveraging metric metadata to frame the target outputs.
- The proposed model, FLAN-FinXC, achieves new state-of-the-art performance on two financial numeric labeling datasets, outperforming several baselines.
Plain English Explanation
The paper focuses on the challenge of automatically tagging important financial numbers (known as GAAP metrics) in financial documents with their corresponding XBRL tags. XBRL is a standardized way of representing financial data that helps computers understand and analyze it more easily.
Unlike previous approaches, the researchers in this paper explore using large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to solve this problem. They frame it as a "generative" task, where the model needs to generate the correct XBRL tag for each financial metric.
To help the model learn this task, the researchers leverage additional information about the financial metrics, such as their metadata (descriptive information). They also use a technique called LoRA to make the model more efficient, requiring fewer parameters to be trained.
When tested on two recent financial datasets, the researchers' FLAN-FinXC model outperformed several other strong baselines, setting new state-of-the-art performance. The model showed the ability to correctly tag even the rarest financial metrics, and even when it didn't predict the exact XBRL tag, its output still overlapped substantially with the ground truth.
Technical Explanation
The paper investigates using a generative approach, via instruction tuning of Large Language Models (LLMs), to automatically annotate relevant financial metrics (GAAP metrics) occurring in financial documents with their corresponding XBRL tags.
To frame the target outputs, the researchers leverage metric metadata information, and propose a parameter-efficient solution for the task using LoRA. They evaluate their proposed model, FLAN-FinXC, on two recently released financial numeric labeling datasets, where it achieves new state-of-the-art performance, outperforming several strong baselines.
The paper explains the better scores of FLAN-FinXC by demonstrating its capability for zero-shot as well as the least frequently occurring tags. Additionally, even when the model fails to predict the exact XBRL tags, its generated output has substantial overlap with the ground-truth in the majority of cases.
Critical Analysis
The paper presents a novel approach to the problem of automatically annotating financial metrics with XBRL tags, leveraging the power of large language models. The researchers' use of metric metadata to frame the target outputs and their adoption of parameter-efficient techniques like LoRA are interesting technical choices.
However, the paper does not delve deeply into the limitations of their approach. For example, it would be helpful to understand how the model performs on edge cases, such as financial metrics that are phrased in unusual ways or are context-dependent. Additionally, the paper could have explored the interpretability of the model's predictions - i.e., how well the generated XBRL tags can be explained and justified.
Further research could also investigate the broader applicability of this approach beyond the financial domain, such as to other types of specialized technical documents. Exploring ways to make the model more robust and generalizable would be valuable contributions to the field.
Overall, the paper presents a promising direction for using large language models to tackle complex annotation tasks in the financial domain, but there is still room for further refinement and exploration of the approach's limitations and potential.
Conclusion
This paper explores the use of large language models (LLMs) to automatically annotate relevant financial metrics (GAAP metrics) in financial documents with their corresponding XBRL tags. By framing the problem as a generative task and leveraging metric metadata, the researchers' proposed FLAN-FinXC model achieves new state-of-the-art performance on two financial numeric labeling datasets.
The paper's findings suggest that LLMs can be effectively applied to complex financial data annotation tasks, with the potential to streamline and enhance the analysis of financial information. This work contributes to the ongoing efforts to integrate large language models into financial regulatory interpretation and other financial applications.
While the paper demonstrates the promise of this approach, further research is needed to fully understand its limitations and explore ways to make the models more robust and generalizable. Nonetheless, this study represents an important step forward in leveraging the power of large language models to tackle challenging problems in the financial domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Parameter-Efficient Instruction Tuning of Large Language Models For Extreme Financial Numeral Labelling
Subhendu Khatuya, Rajdeep Mukherjee, Akash Ghosh, Manjunath Hegde, Koustuv Dasgupta, Niloy Ganguly, Saptarshi Ghosh, Pawan Goyal
We study the problem of automatically annotating relevant numerals (GAAP metrics) occurring in the financial documents with their corresponding XBRL tags. Different from prior works, we investigate the feasibility of solving this extreme classification problem using a generative paradigm through instruction tuning of Large Language Models (LLMs). To this end, we leverage metric metadata information to frame our target outputs while proposing a parameter efficient solution for the task using LoRA. We perform experiments on two recently released financial numeric labeling datasets. Our proposed model, FLAN-FinXC, achieves new state-of-the-art performances on both the datasets, outperforming several strong baselines. We explain the better scores of our proposed model by demonstrating its capability for zero-shot as well as the least frequently occurring tags. Also, even when we fail to predict the XBRL tags correctly, our generated output has substantial overlap with the ground-truth in majority of the cases.
Read more5/16/2024
0
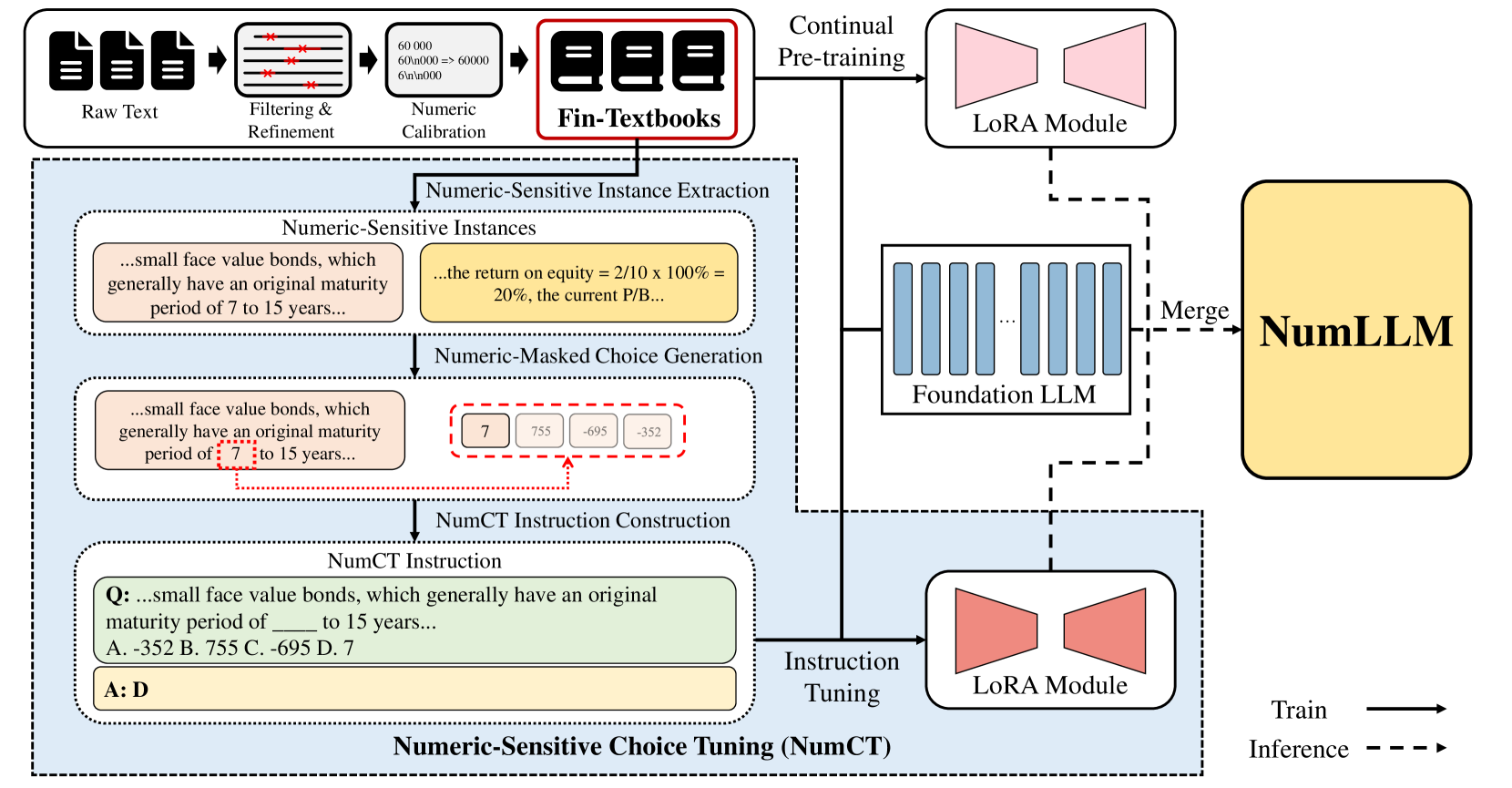
NumLLM: Numeric-Sensitive Large Language Model for Chinese Finance
Huan-Yi Su, Ke Wu, Yu-Hao Huang, Wu-Jun Li
Recently, many works have proposed various financial large language models (FinLLMs) by pre-training from scratch or fine-tuning open-sourced LLMs on financial corpora. However, existing FinLLMs exhibit unsatisfactory performance in understanding financial text when numeric variables are involved in questions. In this paper, we propose a novel LLM, called numeric-sensitive large language model (NumLLM), for Chinese finance. We first construct a financial corpus from financial textbooks which is essential for improving numeric capability of LLMs during fine-tuning. After that, we train two individual low-rank adaptation (LoRA) modules by fine-tuning on our constructed financial corpus. One module is for adapting general-purpose LLMs to financial domain, and the other module is for enhancing the ability of NumLLM to understand financial text with numeric variables. Lastly, we merge the two LoRA modules into the foundation model to obtain NumLLM for inference. Experiments on financial question-answering benchmark show that NumLLM can boost the performance of the foundation model and can achieve the best overall performance compared to all baselines, on both numeric and non-numeric questions.
Read more5/2/2024

0
Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
Read more5/2/2024
🛸
0
Instruction Finetuning for Leaderboard Generation from Empirical AI Research
Salomon Kabongo, Jennifer D'Souza
This study demonstrates the application of instruction finetuning of pretrained Large Language Models (LLMs) to automate the generation of AI research leaderboards, extracting (Task, Dataset, Metric, Score) quadruples from articles. It aims to streamline the dissemination of advancements in AI research by transitioning from traditional, manual community curation, or otherwise taxonomy-constrained natural language inference (NLI) models, to an automated, generative LLM-based approach. Utilizing the FLAN-T5 model, this research enhances LLMs' adaptability and reliability in information extraction, offering a novel method for structured knowledge representation.
Read more8/20/2024