Parameterizing Federated Continual Learning for Reproducible Research
2406.02015
0
0
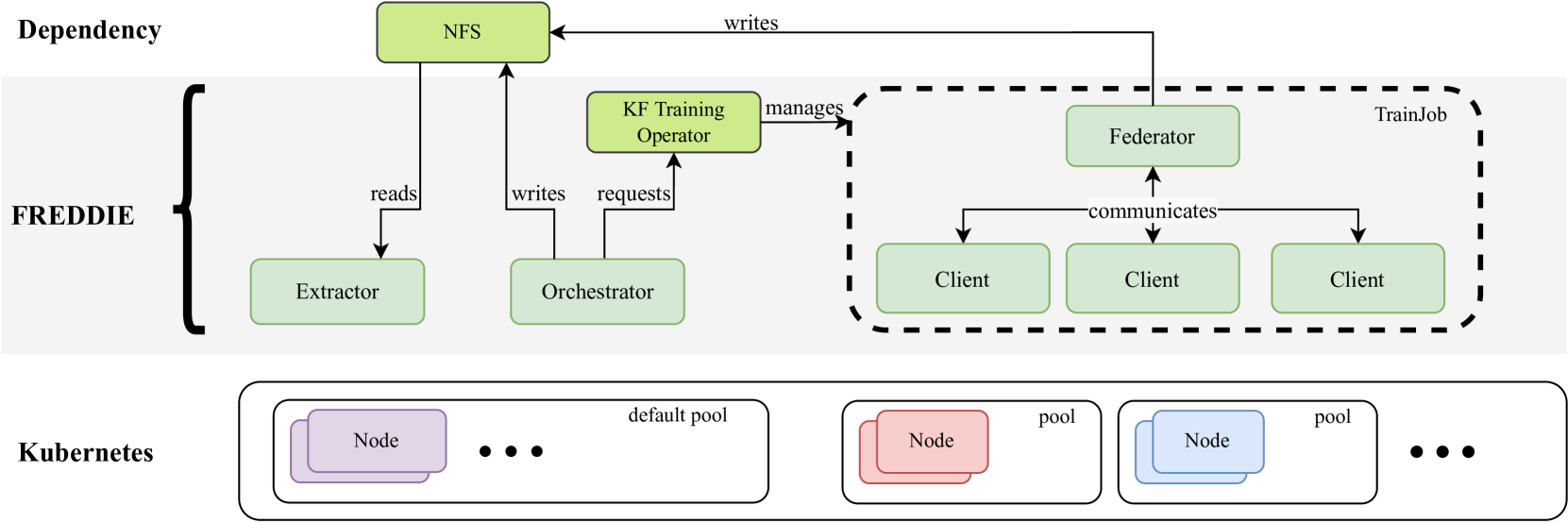
Abstract
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
Create account to get full access
Overview
• This paper explores ways to make federated continual learning more reproducible and standardized. • Federated learning allows multiple devices to collaborate on a shared model without sharing their raw data. • Continual learning aims to train models that can adapt to new data over time without catastrophically forgetting previous knowledge. • Combining these two concepts, federated continual learning allows devices to continuously learn and update a shared model in a decentralized way. • However, the authors note that the field currently lacks consistent benchmarks and experimental setups, making it difficult to compare results across studies. • To address this, the paper proposes a set of parameters and guidelines for designing reproducible federated continual learning experiments.
Plain English Explanation
The paper focuses on making federated continual learning more standardized and reproducible. Federated learning allows multiple devices to collaborate on a shared machine learning model without sharing their private data. Continual learning aims to train models that can adapt to new information over time without forgetting what they've already learned. Combining these two ideas, federated continual learning enables devices to continuously update a shared model in a decentralized way.
However, the authors note that this field currently lacks consistent experimental setups and benchmarks, making it hard to compare results between different studies. To address this issue, the paper proposes a set of parameters and guidelines that researchers can use to design more reproducible federated continual learning experiments. This could help advance the field by allowing for better comparisons and more reliable conclusions.
Technical Explanation
The paper begins by highlighting the challenges in making federated continual learning experiments reproducible. The authors point out that the field currently lacks standardized benchmarks, which makes it difficult to compare results across different studies. To address this, they propose a set of parameters that researchers can use to design their experiments.
These parameters cover various aspects of federated continual learning, such as:
- Client participation patterns: how often clients (e.g., devices) participate in the training process
- Data heterogeneity: the degree of diversity in the data held by different clients
- Task structure: how the learning objectives are organized (e.g., class-incremental, task-incremental)
The authors also propose guidelines for selecting appropriate baselines, evaluation metrics, and reporting practices to ensure that federated continual learning experiments are as reproducible as possible.
Critical Analysis
The paper makes a valuable contribution by highlighting the importance of standardization and reproducibility in federated continual learning research. The proposed parameters and guidelines could indeed help advance the field by allowing for more consistent comparisons and more reliable conclusions.
However, the paper does not address some potential limitations of this approach. For example, the authors do not discuss how to handle the inherent trade-offs between different experimental parameters (e.g., data heterogeneity vs. client participation patterns) or how to choose the most appropriate settings for a given research question.
Additionally, the paper does not explore how these guidelines might need to be adapted for different application domains or real-world deployment scenarios. Federated continual learning in healthcare, for instance, may require different considerations than in consumer electronics.
Overall, the paper provides a solid foundation for improving the reproducibility of federated continual learning research, but there is still room for further exploration and refinement of the proposed framework.
Conclusion
This paper tackles the important issue of reproducibility in the field of federated continual learning. By proposing a set of standardized parameters and guidelines, the authors aim to help researchers design more consistent and comparable experiments. This could lead to faster progress and more reliable conclusions in this rapidly evolving area of machine learning.
While the paper doesn't address all potential limitations, it represents a valuable step towards making federated continual learning research more rigorous and accessible. As the field continues to evolve, further work on standardizing experimental practices and benchmarks will be crucial for driving meaningful advancements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Reducing Bias in Federated Class-Incremental Learning with Hierarchical Generative Prototypes
Riccardo Salami, Pietro Buzzega, Matteo Mosconi, Mattia Verasani, Simone Calderara
0
0
Federated Learning (FL) aims at unburdening the training of deep models by distributing computation across multiple devices (clients) while safeguarding data privacy. On top of that, Federated Continual Learning (FCL) also accounts for data distribution evolving over time, mirroring the dynamic nature of real-world environments. In this work, we shed light on the Incremental and Federated biases that naturally emerge in FCL. While the former is a known problem in Continual Learning, stemming from the prioritization of recently introduced classes, the latter (i.e., the bias towards local distributions) remains relatively unexplored. Our proposal constrains both biases in the last layer by efficiently fine-tuning a pre-trained backbone using learnable prompts, resulting in clients that produce less biased representations and more biased classifiers. Therefore, instead of solely relying on parameter aggregation, we also leverage generative prototypes to effectively balance the predictions of the global model. Our method improves on the current State Of The Art, providing an average increase of +7.9% in accuracy.
6/5/2024
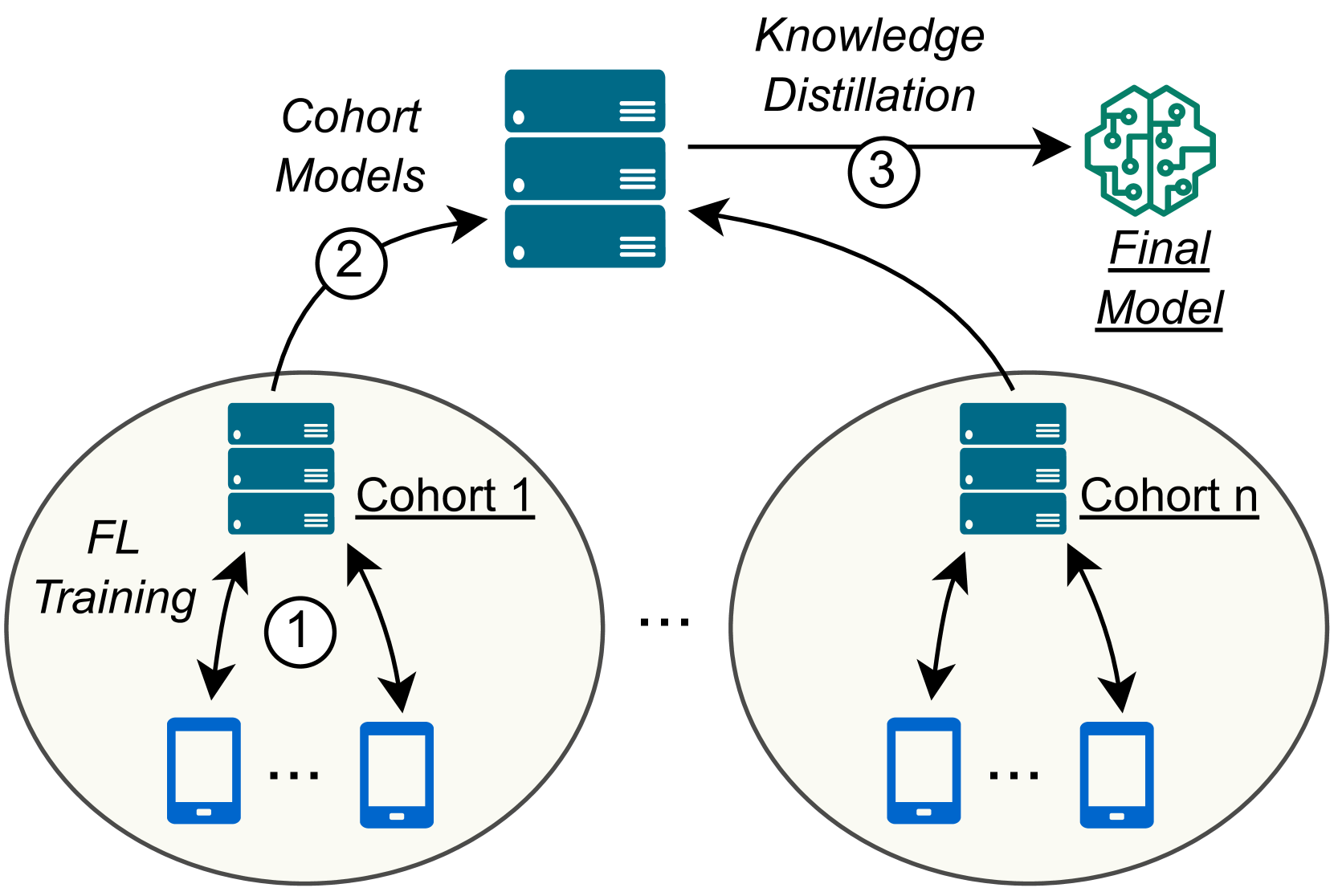
Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
Akash Dhasade, Anne-Marie Kermarrec, Tuan-Anh Nguyen, Rafael Pires, Martijn de Vos
0
0
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$times$ reduction in train time and a 1.3$times$ reduction in resource usage, with a minimal drop in test accuracy.
5/27/2024
📊
Variational Bayes for Federated Continual Learning
Dezhong Yao, Sanmu Li, Yutong Dai, Zhiqiang Xu, Shengshan Hu, Peilin Zhao, Lichao Sun
0
0
Federated continual learning (FCL) has received increasing attention due to its potential in handling real-world streaming data, characterized by evolving data distributions and varying client classes over time. The constraints of storage limitations and privacy concerns confine local models to exclusively access the present data within each learning cycle. Consequently, this restriction induces performance degradation in model training on previous data, termed catastrophic forgetting. However, existing FCL approaches need to identify or know changes in data distribution, which is difficult in the real world. To release these limitations, this paper directs attention to a broader continuous framework. Within this framework, we introduce Federated Bayesian Neural Network (FedBNN), a versatile and efficacious framework employing a variational Bayesian neural network across all clients. Our method continually integrates knowledge from local and historical data distributions into a single model, adeptly learning from new data distributions while retaining performance on historical distributions. We rigorously evaluate FedBNN's performance against prevalent methods in federated learning and continual learning using various metrics. Experimental analyses across diverse datasets demonstrate that FedBNN achieves state-of-the-art results in mitigating forgetting.
5/24/2024
✨
Feature Aggregation with Latent Generative Replay for Federated Continual Learning of Socially Appropriate Robot Behaviours
Nikhil Churamani, Saksham Checker, Hao-Tien Lewis Chiang, Hatice Gunes
0
0
For widespread real-world applications, it is beneficial for robots to explore Federated Learning (FL) settings where several robots, deployed in parallel, can learn independently while also sharing their learning with each other. This work explores a simulated living room environment where robots need to learn the social appropriateness of their actions. We propose Federated Root (FedRoot), a novel weight aggregation strategy which disentangles feature learning across clients from individual task-based learning. Adapting popular FL strategies to use FedRoot instead, we present a novel FL benchmark for learning the social appropriateness of different robot actions in diverse social configurations. FedRoot-based methods offer competitive performance compared to others while offering sizeable (up to 86% for CPU usage and up to 72% for GPU usage) reduction in resource consumption. Furthermore, real-world interactions require social robots to dynamically adapt to changing environmental and task settings. To facilitate this, we propose Federated Latent Generative Replay (FedLGR), a novel Federated Continual Learning (FCL) strategy that uses FedRoot-based weight aggregation and embeds each client with a generator model for pseudo-rehearsal of learnt feature embeddings to mitigate forgetting in a resource-efficient manner. Our benchmark results demonstrate that FedRoot-based FCL methods outperform other methods while also offering sizeable (up to 84% for CPU usage and up to 92% for GPU usage) reduction in resource consumption, with FedLGR providing the best results across evaluations.
5/28/2024