Parm: Efficient Training of Large Sparsely-Activated Models with Dedicated Schedules

0

Sign in to get full access
Overview
- The paper introduces a novel training method called Parm, which enables efficient training of large sparsely-activated models.
- Parm utilizes dedicated activation and pruning schedules to train these models, leading to significant improvements in performance and memory efficiency compared to existing approaches.
- The paper demonstrates the effectiveness of Parm on various large-scale language and vision tasks, showcasing its potential to accelerate the development of efficient AI models.
Plain English Explanation
The paper introduces a new training method called Parm that helps to efficiently train large AI models that only activate a small portion of their parameters at a time. These types of models, known as "sparsely-activated models," can be more memory-efficient and perform better than traditional dense models, but they can be challenging to train effectively.
Parm addresses this challenge by using specialized schedules for activating and pruning the model's parameters during training. This allows the model to learn a sparse and efficient representation of the task, leading to significant improvements in performance and memory usage compared to previous methods.
The researchers demonstrate the effectiveness of Parm on a variety of large-scale language and computer vision tasks, showing that it can accelerate the development of efficient AI models that are capable of tackling complex problems while using fewer computational resources.
Technical Explanation
The paper introduces a novel training method called Parm (Efficient Training of Large Sparsely-Activated Models with Dedicated Schedules) that enables efficient training of large sparsely-activated models. Sparsely-activated models, such as Mixture of Experts (MoE) models, Sparse Transformer models, and Sparse Mixture of Experts models, have shown promise in improving performance and memory efficiency compared to traditional dense models.
However, training these sparsely-activated models can be challenging due to the complex interactions between activation and pruning schedules. Parm addresses this challenge by introducing dedicated activation and pruning schedules that are tailored to the specific properties of large sparsely-activated models. The paper demonstrates that Parm can achieve significant improvements in performance and memory efficiency compared to existing training methods, as shown through experiments on various large-scale language and vision tasks.
The key insights and contributions of the paper include:
- A novel training method, Parm, that leverages dedicated activation and pruning schedules to efficiently train large sparsely-activated models.
- Extensive experiments on language and vision tasks, showcasing the effectiveness of Parm in improving performance and memory efficiency compared to previous approaches, such as Pre-Gated MoE and SIDA-MoE.
- Detailed analysis and insights into the role of activation and pruning schedules in training large sparsely-activated models.
Critical Analysis
The paper presents a compelling approach to training large sparsely-activated models, but there are a few potential limitations and areas for further research that could be explored:
-
Generalization to a wider range of tasks and architectures: While the paper demonstrates the effectiveness of Parm on various language and vision tasks, it would be valuable to explore its applicability to a broader set of problem domains and model architectures, such as reinforcement learning or multimodal tasks.
-
Theoretical understanding of the training dynamics: The paper provides a thorough empirical evaluation of Parm, but a deeper theoretical analysis of the underlying training dynamics and the role of activation and pruning schedules could yield additional insights and guide further improvements.
-
Computational and memory efficiency trade-offs: The paper focuses on improving performance and memory efficiency through Parm, but it would be interesting to examine the computational trade-offs, such as the impact on training time or energy consumption, and explore ways to further optimize these aspects.
-
Sensitivity to hyperparameter tuning: The effectiveness of Parm may be sensitive to the choice of hyperparameters, such as the specific activation and pruning schedules. It would be valuable to investigate the robustness of Parm to these choices and provide guidance on hyperparameter selection.
Overall, the paper presents a promising approach to training large sparsely-activated models, and the Parm method has the potential to significantly accelerate the development of efficient AI systems. By addressing these potential areas for further research, the impact of this work could be further expanded.
Conclusion
The paper introduces Parm, a novel training method that enables efficient training of large sparsely-activated models. Parm utilizes dedicated activation and pruning schedules to learn a sparse and efficient representation of the task, leading to significant improvements in performance and memory usage compared to existing approaches.
The researchers demonstrate the effectiveness of Parm on a variety of large-scale language and vision tasks, showcasing its potential to accelerate the development of efficient AI models that can tackle complex problems while using fewer computational resources. The paper's contributions have important implications for the field of machine learning, as the ability to train large, efficient models has the potential to unlock new frontiers in AI applications and make these technologies more accessible and sustainable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Parm: Efficient Training of Large Sparsely-Activated Models with Dedicated Schedules
Xinglin Pan, Wenxiang Lin, Shaohuai Shi, Xiaowen Chu, Weinong Sun, Bo Li
Sparsely-activated Mixture-of-Expert (MoE) layers have found practical applications in enlarging the model size of large-scale foundation models, with only a sub-linear increase in computation demands. Despite the wide adoption of hybrid parallel paradigms like model parallelism, expert parallelism, and expert-sharding parallelism (i.e., MP+EP+ESP) to support MoE model training on GPU clusters, the training efficiency is hindered by communication costs introduced by these parallel paradigms. To address this limitation, we propose Parm, a system that accelerates MP+EP+ESP training by designing two dedicated schedules for placing communication tasks. The proposed schedules eliminate redundant computations and communications and enable overlaps between intra-node and inter-node communications, ultimately reducing the overall training time. As the two schedules are not mutually exclusive, we provide comprehensive theoretical analyses and derive an automatic and accurate solution to determine which schedule should be applied in different scenarios. Experimental results on an 8-GPU server and a 32-GPU cluster demonstrate that Parm outperforms the state-of-the-art MoE training system, DeepSpeed-MoE, achieving 1.13$times$ to 5.77$times$ speedup on 1296 manually configured MoE layers and approximately 3$times$ improvement on two real-world MoE models based on BERT and GPT-2.
Read more7/4/2024

0
Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts
Weilin Cai, Juyong Jiang, Le Qin, Junwei Cui, Sunghun Kim, Jiayi Huang
Expert parallelism has been introduced as a strategy to distribute the computational workload of sparsely-gated mixture-of-experts (MoE) models across multiple computing devices, facilitating the execution of these increasingly large-scale models. However, the All-to-All communication intrinsic to expert parallelism constitutes a significant overhead, diminishing the MoE models' efficiency. Current optimization approaches offer some relief, yet they are constrained by the sequential interdependence of communication and computation operations. To address this limitation, we present a novel shortcut-connected MoE architecture with overlapping parallel strategy, designated as ScMoE, which effectively decouples communication from its conventional sequence, allowing for a substantial overlap of 70% to 100% with computation. When compared with the prevalent top-2 MoE architecture, ScMoE demonstrates training speed improvements of 30% and 11%, and inference improvements of 40% and 15%, in our PCIe and NVLink hardware environments, respectively, where communication constitutes 60% and 15% of the total MoE time consumption. On the other hand, extensive experiments and theoretical analyses indicate that ScMoE not only achieves comparable but in some instances surpasses the model quality of existing approaches in vision and language tasks.
Read more4/9/2024
0
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
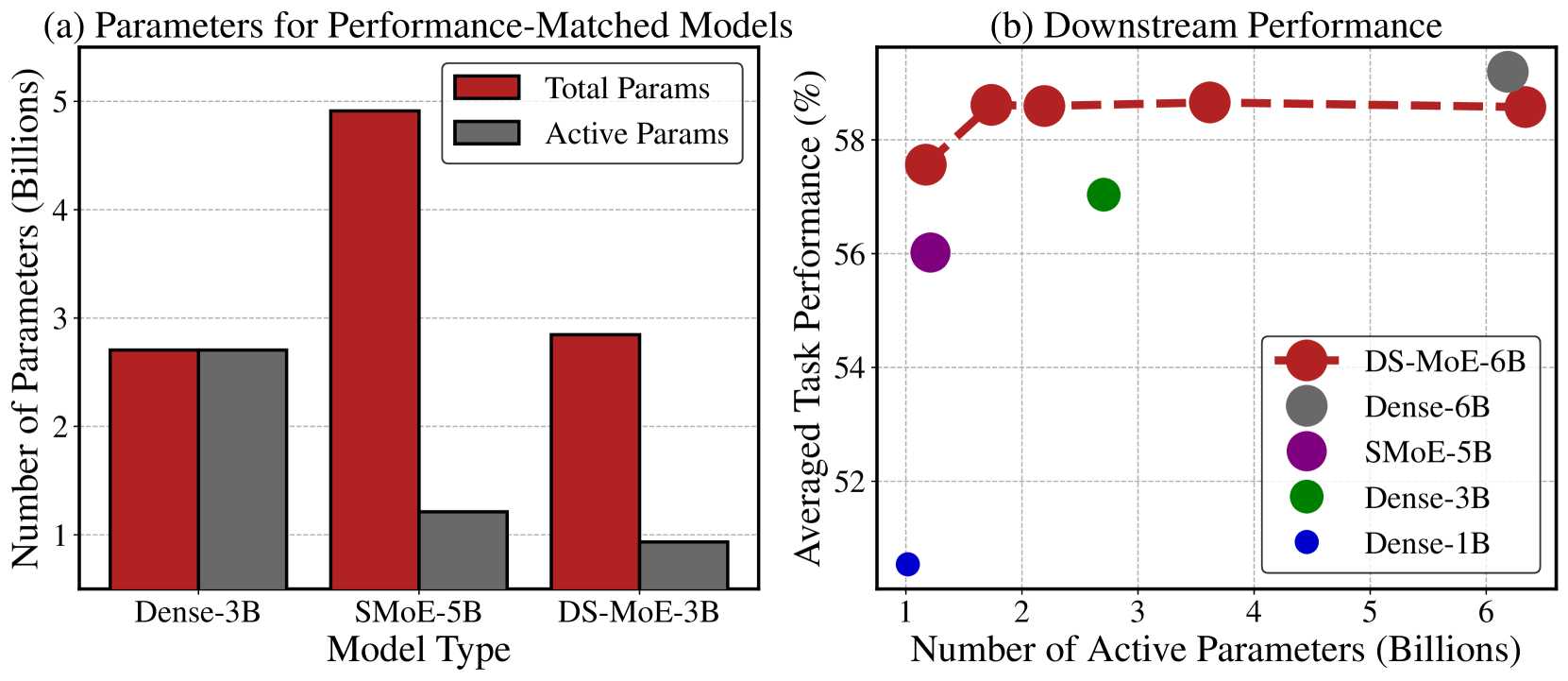
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Read more4/9/2024

0
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B. Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang
The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.
Read more7/2/2024