Unsupervised Part Discovery via Dual Representation Alignment

0

Sign in to get full access
Overview
- Unsupervised learning approach for discovering parts in visual objects
- Uses dual representation alignment to discover part-specific attention
- Applies to vision transformers for improved performance on part-aware tasks
Plain English Explanation
This research proposes a new unsupervised method for discovering parts in visual objects, such as in images or 3D models. The key idea is to use dual representation alignment, which means aligning two different ways of representing the object to find the important parts.
One representation is the overall object, and the other is the individual parts that make up the object. By finding the alignment between these two representations, the method can discover the parts in an unsupervised way, without needing any labeled training data.
This part discovery is particularly useful for vision transformer models, which can then focus attention on the relevant parts of the object to improve performance on part-aware tasks like object recognition or segmentation.
Technical Explanation
The key technical innovation is the dual representation alignment approach. The first representation is a global object-level embedding, which captures the overall structure and appearance of the object. The second representation is a set of part-level embeddings, which capture the individual components that make up the object.
The method aligns these two representations by optimizing a loss function that encourages the part-level embeddings to be predictive of the object-level embedding. This forces the part-level embeddings to capture the salient parts of the object in an unsupervised manner.
Once the part-level embeddings are learned, they can be used to guide the attention mechanism of a vision transformer model, allowing it to focus on the relevant parts of the object for improved performance on downstream tasks.
Critical Analysis
The main strength of this approach is its ability to discover object parts in an unsupervised way, without requiring any labeled training data. This is a significant advantage over supervised methods that rely on human-annotated part labels.
However, the paper does not extensively evaluate the quality or usefulness of the discovered parts, nor does it compare the method to other unsupervised part discovery techniques. Further research would be needed to fully understand the limitations and tradeoffs of this approach.
Additionally, the method is demonstrated only on relatively simple object categories, and it's unclear how well it would scale to more complex, real-world objects with a larger number of parts. Exploring the robustness and generalization of the approach would be an important area for future work.
Conclusion
This research presents a novel unsupervised method for discovering object parts using dual representation alignment. By aligning global object-level and part-level representations, the approach can identify the salient parts of an object in a data-driven way. This part discovery can then be leveraged to improve the performance of vision transformer models on part-aware tasks, with potential applications in areas like object recognition, segmentation, and 3D understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Part Discovery via Dual Representation Alignment
Jiahao Xia, Wenjian Huang, Min Xu, Jianguo Zhang, Haimin Zhang, Ziyu Sheng, Dong Xu
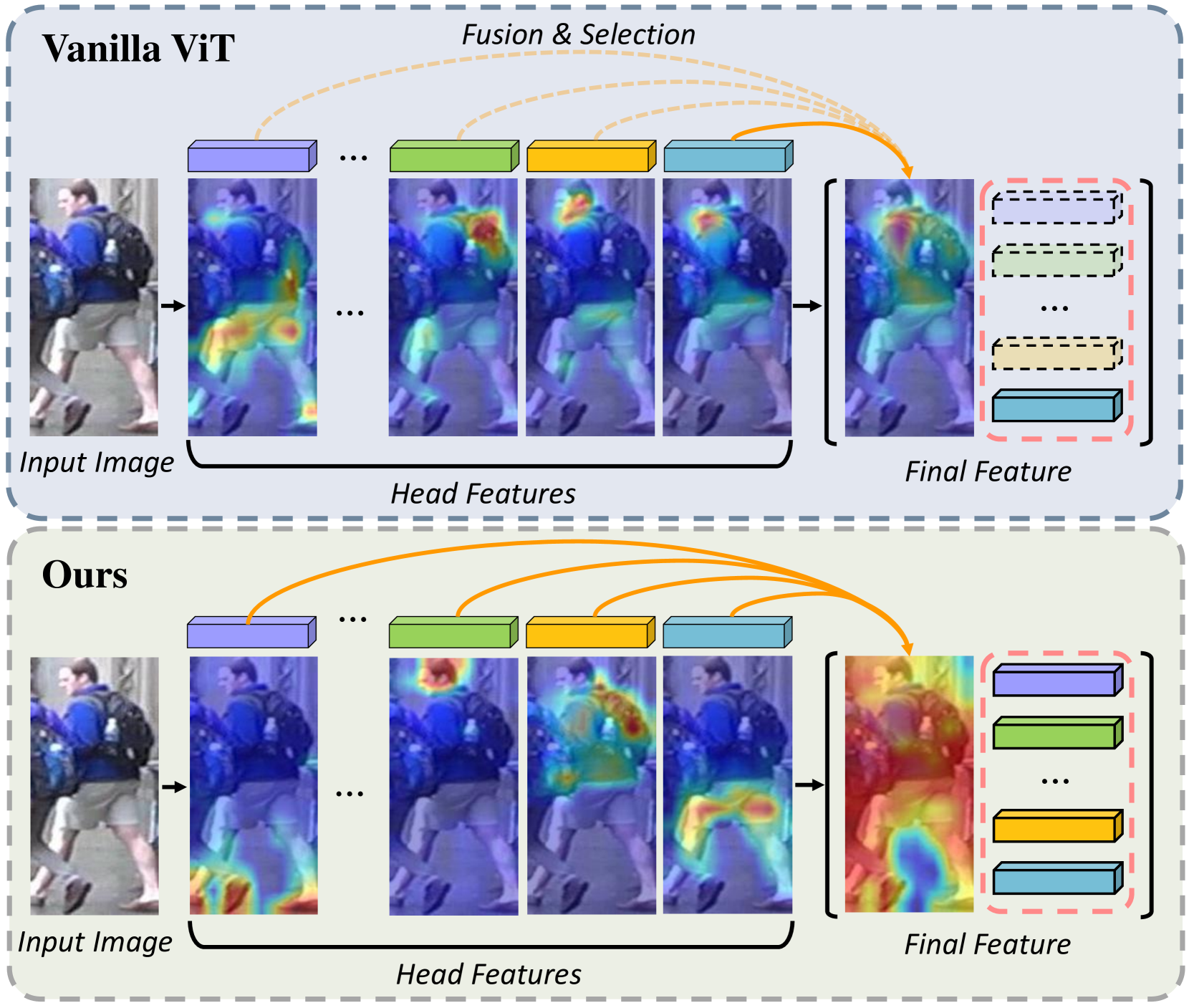
Object parts serve as crucial intermediate representations in various downstream tasks, but part-level representation learning still has not received as much attention as other vision tasks. Previous research has established that Vision Transformer can learn instance-level attention without labels, extracting high-quality instance-level representations for boosting downstream tasks. In this paper, we achieve unsupervised part-specific attention learning using a novel paradigm and further employ the part representations to improve part discovery performance. Specifically, paired images are generated from the same image with different geometric transformations, and multiple part representations are extracted from these paired images using a novel module, named PartFormer. These part representations from the paired images are then exchanged to improve geometric transformation invariance. Subsequently, the part representations are aligned with the feature map extracted by a feature map encoder, achieving high similarity with the pixel representations of the corresponding part regions and low similarity in irrelevant regions. Finally, the geometric and semantic constraints are applied to the part representations through the intermediate results in alignment for part-specific attention learning, encouraging the PartFormer to focus locally and the part representations to explicitly include the information of the corresponding parts. Moreover, the aligned part representations can further serve as a series of reliable detectors in the testing phase, predicting pixel masks for part discovery. Extensive experiments are carried out on four widely used datasets, and our results demonstrate that the proposed method achieves competitive performance and robustness due to its part-specific attention.
Read more8/16/2024
0
PartFormer: Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification
Lei Tan, Pingyang Dai, Jie Chen, Liujuan Cao, Yongjian Wu, Rongrong Ji
Extracting robust feature representation is critical for object re-identification to accurately identify objects across non-overlapping cameras. Although having a strong representation ability, the Vision Transformer (ViT) tends to overfit on most distinct regions of training data, limiting its generalizability and attention to holistic object features. Meanwhile, due to the structural difference between CNN and ViT, fine-grained strategies that effectively address this issue in CNN do not continue to be successful in ViT. To address this issue, by observing the latent diverse representation hidden behind the multi-head attention, we present PartFormer, an innovative adaptation of ViT designed to overcome the granularity limitations in object Re-ID tasks. The PartFormer integrates a Head Disentangling Block (HDB) that awakens the diverse representation of multi-head self-attention without the typical loss of feature richness induced by concatenation and FFN layers post-attention. To avoid the homogenization of attention heads and promote robust part-based feature learning, two head diversity constraints are imposed: attention diversity constraint and correlation diversity constraint. These constraints enable the model to exploit diverse and discriminative feature representations from different attention heads. Comprehensive experiments on various object Re-ID benchmarks demonstrate the superiority of the PartFormer. Specifically, our framework significantly outperforms state-of-the-art by 2.4% mAP scores on the most challenging MSMT17 dataset.
Read more8/30/2024

0
PDiscoFormer: Relaxing Part Discovery Constraints with Vision Transformers
Ananthu Aniraj, Cassio F. Dantas, Dino Ienco, Diego Marcos
Computer vision methods that explicitly detect object parts and reason on them are a step towards inherently interpretable models. Existing approaches that perform part discovery driven by a fine-grained classification task make very restrictive assumptions on the geometric properties of the discovered parts; they should be small and compact. Although this prior is useful in some cases, in this paper we show that pre-trained transformer-based vision models, such as self-supervised DINOv2 ViT, enable the relaxation of these constraints. In particular, we find that a total variation (TV) prior, which allows for multiple connected components of any size, substantially outperforms previous work. We test our approach on three fine-grained classification benchmarks: CUB, PartImageNet and Oxford Flowers, and compare our results to previously published methods as well as a re-implementation of the state-of-the-art method PDiscoNet with a transformer-based backbone. We consistently obtain substantial improvements across the board, both on part discovery metrics and the downstream classification task, showing that the strong inductive biases in self-supervised ViT models require to rethink the geometric priors that can be used for unsupervised part discovery.
Read more7/23/2024

0
DuoFormer: Leveraging Hierarchical Visual Representations by Local and Global Attention
Xiaoya Tang, Bodong Zhang, Beatrice S. Knudsen, Tolga Tasdizen
We here propose a novel hierarchical transformer model that adeptly integrates the feature extraction capabilities of Convolutional Neural Networks (CNNs) with the advanced representational potential of Vision Transformers (ViTs). Addressing the lack of inductive biases and dependence on extensive training datasets in ViTs, our model employs a CNN backbone to generate hierarchical visual representations. These representations are then adapted for transformer input through an innovative patch tokenization. We also introduce a 'scale attention' mechanism that captures cross-scale dependencies, complementing patch attention to enhance spatial understanding and preserve global perception. Our approach significantly outperforms baseline models on small and medium-sized medical datasets, demonstrating its efficiency and generalizability. The components are designed as plug-and-play for different CNN architectures and can be adapted for multiple applications. The code is available at https://github.com/xiaoyatang/DuoFormer.git.
Read more7/22/2024