Estimating Model Performance Under Covariate Shift Without Labels
2401.08348
0
0
📈
Abstract
Machine learning models often experience performance degradation post-deployment due to shifts in data distribution. It is challenging to assess model's performance accurately when labels are missing or delayed. Existing proxy methods, such as drift detection, fail to measure the effects of these shifts adequately. To address this, we introduce a new method, Probabilistic Adaptive Performance Estimation (PAPE), for evaluating classification models on unlabeled data that accurately quantifies the impact of covariate shift on model performance. It is model and data-type agnostic and works for various performance metrics. Crucially, PAPE operates independently of the original model, relying only on its predictions and probability estimates, and does not need any assumptions about the nature of the covariate shift, learning directly from data instead. We tested PAPE on tabular data using over 900 dataset-model combinations created from US census data, assessing its performance against multiple benchmarks. Overall, PAPE provided more accurate performance estimates than other evaluated methodologies.
Create account to get full access
Overview
- Machine learning models can experience performance degradation after deployment due to shifts in the data distribution
- Existing methods for assessing post-deployment performance, like drift detection, often fail to adequately measure the impact of these shifts
- This paper introduces a new method called Probabilistic Adaptive Performance Estimation (PAPE) to accurately quantify the effects of covariate shift on model performance, without needing labeled data or assumptions about the shift
Plain English Explanation
Machine learning models are trained on data to perform certain tasks, like classifying images or predicting outcomes. However, once these models are deployed in the real world, the data they encounter may change over time, a phenomenon known as covariate shift. This can cause the model's performance to degrade, as it is no longer as accurate on the new data.
Existing methods for assessing a model's post-deployment performance, such as drift detection, have limitations in accurately measuring the impact of these data shifts. The new PAPE method introduced in this paper aims to solve this problem.
PAPE works by analyzing the model's own predictions and probability estimates, without needing access to the original model or any assumptions about the nature of the data shift. It can quantify the effects of covariate shift on the model's performance for any given metric, like accuracy or F1-score. This makes PAPE a versatile and powerful tool for monitoring and maintaining the performance of deployed machine learning models.
Technical Explanation
The paper presents a new method called Probabilistic Adaptive Performance Estimation (PAPE) for evaluating the performance of classification models on unlabeled data, even in the presence of covariate shift. PAPE is model and data-type agnostic, meaning it can work with any machine learning model and any type of data.
The key idea behind PAPE is to use the model's own prediction probabilities to estimate how the model's performance would change due to a shift in the data distribution. PAPE does not require access to the original model or any assumptions about the nature of the data shift; it learns directly from the data and model outputs.
The authors tested PAPE using over 900 dataset-model combinations from US census data, comparing its performance to several benchmarks. The results showed that PAPE outperforms other methodologies in accurately estimating the impact of covariate shift on model performance.
Critical Analysis
The paper provides a thorough evaluation of PAPE and demonstrates its superiority over existing methods for assessing post-deployment model performance. However, the authors acknowledge that PAPE has some limitations. For example, it may not perform as well when the covariate shift is very large or when the original model's probability estimates are not well-calibrated.
Additionally, the paper does not address the potential challenges of deploying PAPE in real-world scenarios, where the data shifts may be more complex and continuous over time. Further research could explore how PAPE could be adapted to handle these more dynamic and realistic conditions.
Overall, the PAPE method represents a significant advancement in the field of model robustness and adaptation, and the authors have provided a comprehensive and well-designed study to support its effectiveness.
Conclusion
This paper introduces a new method called Probabilistic Adaptive Performance Estimation (PAPE) that can accurately quantify the impact of covariate shift on the performance of classification models, even in the absence of labeled data. PAPE is a versatile and powerful tool that can help machine learning practitioners monitor and maintain the performance of their deployed models, which is crucial for ensuring the reliability and trustworthiness of these systems.
The thorough evaluation of PAPE presented in the paper demonstrates its superiority over existing methods, making it a valuable addition to the field of model robustness and adaptation. While PAPE has some limitations, the authors have provided a solid foundation for further research and development in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
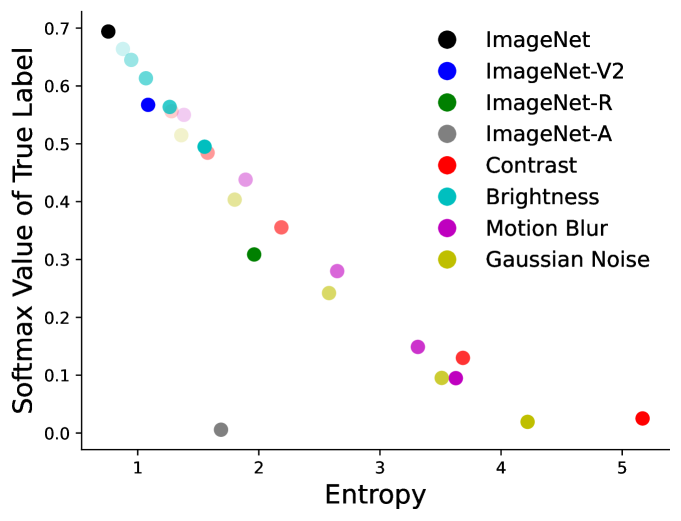
Adapting Conformal Prediction to Distribution Shifts Without Labels
Kevin Kasa, Zhiyu Zhang, Heng Yang, Graham W. Taylor
0
0
Conformal prediction (CP) enables machine learning models to output prediction sets with guaranteed coverage rate, assuming exchangeable data. Unfortunately, the exchangeability assumption is frequently violated due to distribution shifts in practice, and the challenge is often compounded by the lack of ground truth labels at test time. Focusing on classification in this paper, our goal is to improve the quality of CP-generated prediction sets using only unlabeled data from the test domain. This is achieved by two new methods called ECP and EACP, that adjust the score function in CP according to the base model's uncertainty on the unlabeled test data. Through extensive experiments on a number of large-scale datasets and neural network architectures, we show that our methods provide consistent improvement over existing baselines and nearly match the performance of supervised algorithms.
6/4/2024
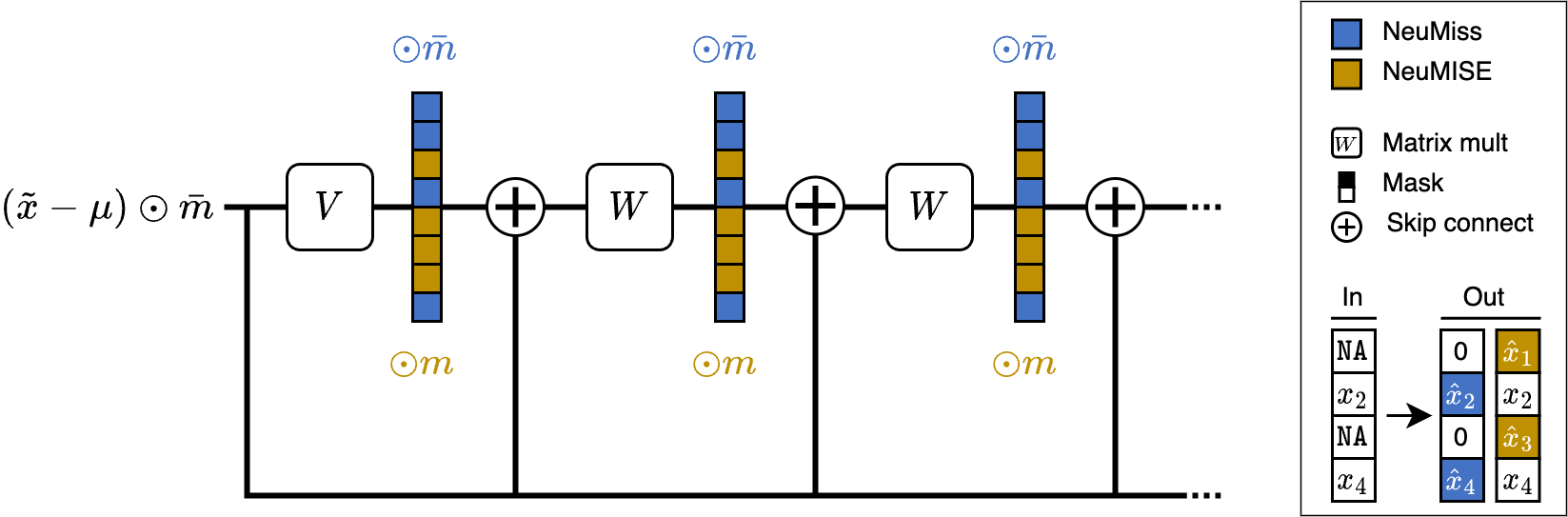
Robust prediction under missingness shifts
Patrick Rockenschaub, Zhicong Xian, Alireza Zamanian, Marta Piperno, Octavia-Andreea Ciora, Elisabeth Pachl, Narges Ahmidi
0
0
Prediction becomes more challenging with missing covariates. What method is chosen to handle missingness can greatly affect how models perform. In many real-world problems, the best prediction performance is achieved by models that can leverage the informative nature of a value being missing. Yet, the reasons why a covariate goes missing can change once a model is deployed in practice. If such a missingness shift occurs, the conditional probability of a value being missing differs in the target data. Prediction performance in the source data may no longer be a good selection criterion, and approaches that do not rely on informative missingness may be preferable. However, we show that the Bayes predictor remains unchanged by ignorable shifts for which the probability of missingness only depends on observed data. Any consistent estimator of the Bayes predictor may therefore result in robust prediction under those conditions, although we show empirically that different methods appear robust to different types of shifts. If the missingness shift is non-ignorable, the Bayes predictor may change due to the shift. While neither approach recovers the Bayes predictor in this case, we found empirically that disregarding missingness was most beneficial when it was highly informative.
6/26/2024
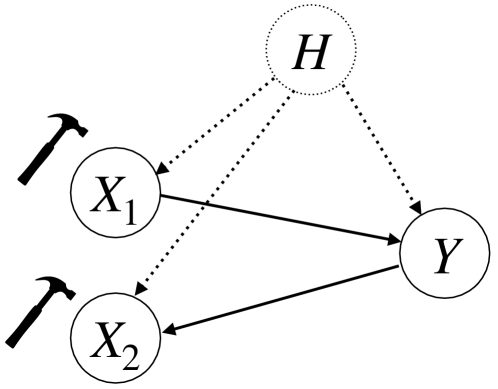
Invariant Probabilistic Prediction
Alexander Henzi, Xinwei Shen, Michael Law, Peter Buhlmann
0
0
In recent years, there has been a growing interest in statistical methods that exhibit robust performance under distribution changes between training and test data. While most of the related research focuses on point predictions with the squared error loss, this article turns the focus towards probabilistic predictions, which aim to comprehensively quantify the uncertainty of an outcome variable given covariates. Within a causality-inspired framework, we investigate the invariance and robustness of probabilistic predictions with respect to proper scoring rules. We show that arbitrary distribution shifts do not, in general, admit invariant and robust probabilistic predictions, in contrast to the setting of point prediction. We illustrate how to choose evaluation metrics and restrict the class of distribution shifts to allow for identifiability and invariance in the prototypical Gaussian heteroscedastic linear model. Motivated by these findings, we propose a method to yield invariant probabilistic predictions, called IPP, and study the consistency of the underlying parameters. Finally, we demonstrate the empirical performance of our proposed procedure on simulated as well as on single-cell data.
6/18/2024
🔮
Selective Prediction for Semantic Segmentation using Post-Hoc Confidence Estimation and Its Performance under Distribution Shift
Bruno Laboissiere Camargos Borges, Bruno Machado Pacheco, Danilo Silva
0
0
Semantic segmentation plays a crucial role in various computer vision applications, yet its efficacy is often hindered by the lack of high-quality labeled data. To address this challenge, a common strategy is to leverage models trained on data from different populations, such as publicly available datasets. This approach, however, leads to the distribution shift problem, presenting a reduced performance on the population of interest. In scenarios where model errors can have significant consequences, selective prediction methods offer a means to mitigate risks and reduce reliance on expert supervision. This paper investigates selective prediction for semantic segmentation in low-resource settings, thus focusing on post-hoc confidence estimators applied to pre-trained models operating under distribution shift. We propose a novel image-level confidence measure tailored for semantic segmentation and demonstrate its effectiveness through experiments on three medical imaging tasks. Our findings show that post-hoc confidence estimators offer a cost-effective approach to reducing the impacts of distribution shift.
5/8/2024