Path Following and Stabilisation of a Bicycle Model using a Reinforcement Learning Approach

0

Sign in to get full access
Overview
- The paper focuses on using a reinforcement learning approach to achieve path following and stabilization of a bicycle model.
- It involves developing a bicycle model and applying reinforcement learning techniques to train an agent to control the bicycle and navigate a desired path.
- The key goals are to enable the bicycle to follow a specified path and maintain stability during the process.
Plain English Explanation
The researchers in this paper explored using a technique called reinforcement learning to control the movement of a virtual bicycle. Reinforcement learning is a type of machine learning where an agent (in this case, the bicycle) learns to take actions that maximize a "reward" signal.
The researchers first created a mathematical model to simulate the behavior of a real bicycle. This model captured the dynamics and constraints of how a bicycle moves and balances. Then, they trained a reinforcement learning agent to control the virtual bicycle and make it follow a specified path while maintaining stability.
The key idea is that the agent can learn, through trial and error, how to steer and balance the bicycle in a way that keeps it on the desired path. Over many iterations, the agent discovers the optimal control strategy. This allows the bicycle to navigate complex paths without needing to be explicitly programmed with every possible maneuver.
The researchers tested their approach in simulation and found that the reinforcement learning agent was able to successfully follow paths and maintain stability, even when faced with disturbances or changes in the environment. This suggests the technique could be useful for controlling real-world bicycles or other vehicles in the future.
Technical Explanation
The researchers first developed a bicycle model that captured the key dynamics of a real bicycle, including the nonlinear lateral and longitudinal dynamics, tire forces, and other relevant factors. They then formulated the path following and stabilization problem as a reinforcement learning task.
In the reinforcement learning framework, the bicycle is the "agent" that interacts with the environment (the bicycle model and desired path) to learn an optimal control policy. At each time step, the agent observes the current state of the bicycle (position, velocity, orientation, etc.) and the desired path, and then selects an action (steering angle and throttle/brake) to apply.
The agent receives a reward signal that encourages it to follow the desired path and maintain stability. For example, the agent might receive a positive reward for staying close to the path and a negative reward for deviating from it or losing balance. By iteratively taking actions and observing the results, the agent gradually learns the optimal control strategy through a trial-and-error process.
The researchers used a deep reinforcement learning approach, where the agent's policy is represented by a deep neural network that maps states to actions. This allows the agent to learn complex, nonlinear control policies that are well-suited to the bicycle's dynamics.
Through simulation experiments, the researchers demonstrated that the reinforcement learning agent was able to successfully follow various paths and maintain the bicycle's stability, even in the presence of disturbances. This suggests the technique could be applicable to real-world bicycle control or other similar vehicle control problems.
Critical Analysis
The researchers acknowledge several limitations and areas for further research. Firstly, the study was conducted entirely in simulation, and it remains to be seen how well the approach would translate to a real-world bicycle system with all its complexities and uncertainties.
Additionally, the researchers used a relatively simple bicycle model that may not capture all the nuances of a real bicycle's behavior. More detailed models, or even experiments with a physical bicycle, could be needed to fully validate the approach.
Another potential issue is the reliance on the reward function, which was manually designed by the researchers. The performance of the reinforcement learning agent could be sensitive to the choice of reward function, and finding the optimal reward function may require significant trial and error.
Finally, the study did not compare the reinforcement learning approach to other control techniques, such as model-based control or classical control methods. Understanding how the reinforcement learning approach performs relative to these alternatives would be valuable for assessing its merits.
Despite these limitations, the researchers' work demonstrates the potential of reinforcement learning for solving complex control problems, and the results are promising for future applications in bicycle and vehicle control.
Conclusion
This paper explored the use of a reinforcement learning approach to achieve path following and stabilization of a bicycle model. By developing a bicycle model and training a reinforcement learning agent to control the virtual bicycle, the researchers were able to demonstrate the agent's ability to navigate desired paths while maintaining stability, even in the presence of disturbances.
The findings suggest that reinforcement learning could be a useful technique for controlling real-world bicycles or other vehicles in the future. However, further research is needed to validate the approach in real-world conditions and compare it to alternative control methods. Nonetheless, this work contributes to the growing body of research on applying advanced machine learning techniques to challenging control problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Path Following and Stabilisation of a Bicycle Model using a Reinforcement Learning Approach
Sebastian Weyrer, Peter Manzl, A. L. Schwab, Johannes Gerstmayr
Over the years, complex control approaches have been developed to control the motion of a bicycle. Reinforcement Learning (RL), a branch of machine learning, promises easy deployment of so-called agents. Deployed agents are increasingly considered as an alternative to controllers for mechanical systems. The present work introduces an RL approach to do path following with a virtual bicycle model while simultaneously stabilising it laterally. The bicycle, modelled as the Whipple benchmark model and using multibody system dynamics, has no stabilisation aids. The agent succeeds in both path following and stabilisation of the bicycle model exclusively by outputting steering angles, which are converted into steering torques via a PD controller. Curriculum learning is applied as a state-of-the-art training strategy. Different settings for the implemented RL framework are investigated and compared to each other. The performance of the deployed agents is evaluated using different types of paths and measurements. The ability of the deployed agents to do path following and stabilisation of the bicycle model travelling between 2m/s and 7m/s along complex paths including full circles, slalom manoeuvres, and lane changes is demonstrated. Explanatory methods for machine learning are used to analyse the functionality of a deployed agent and link the introduced RL approach with research in the field of bicycle dynamics.
Read more7/25/2024
0
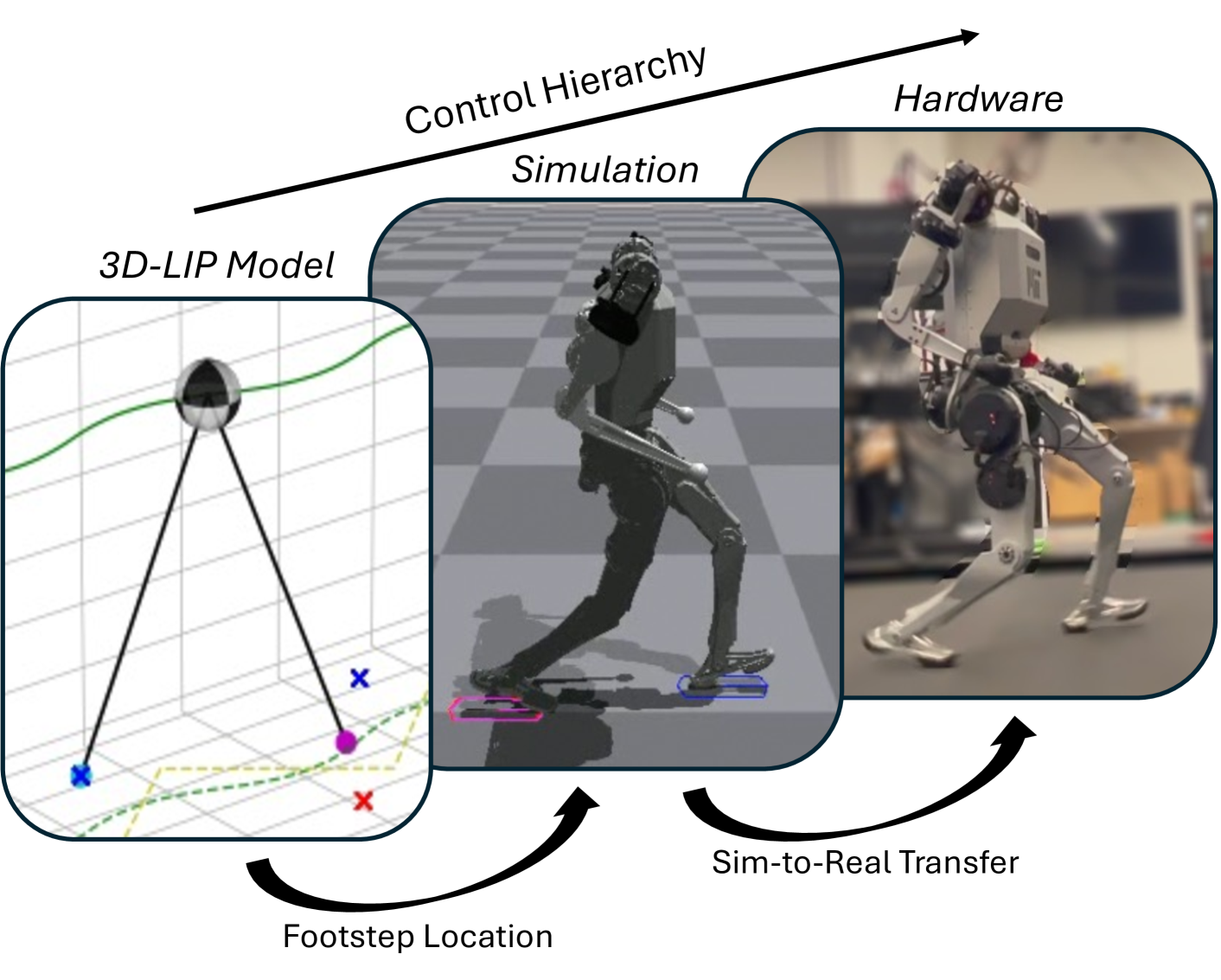
Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion
Ho Jae Lee, Seungwoo Hong, Sangbae Kim
In this work, we introduce a control framework that combines model-based footstep planning with Reinforcement Learning (RL), leveraging desired footstep patterns derived from the Linear Inverted Pendulum (LIP) dynamics. Utilizing the LIP model, our method forward predicts robot states and determines the desired foot placement given the velocity commands. We then train an RL policy to track the foot placements without following the full reference motions derived from the LIP model. This partial guidance from the physics model allows the RL policy to integrate the predictive capabilities of the physics-informed dynamics and the adaptability characteristics of the RL controller without overfitting the policy to the template model. Our approach is validated on the MIT Humanoid, demonstrating that our policy can achieve stable yet dynamic locomotion for walking and turning. We further validate the adaptability and generalizability of our policy by extending the locomotion task to unseen, uneven terrain. During the hardware deployment, we have achieved forward walking speeds of up to 1.5 m/s on a treadmill and have successfully performed dynamic locomotion maneuvers such as 90-degree and 180-degree turns.
Read more8/6/2024
🏅
0
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
Zhongyu Li, Xue Bin Peng, Pieter Abbeel, Sergey Levine, Glen Berseth, Koushil Sreenath
This paper presents a comprehensive study on using deep reinforcement learning (RL) to create dynamic locomotion controllers for bipedal robots. Going beyond focusing on a single locomotion skill, we develop a general control solution that can be used for a range of dynamic bipedal skills, from periodic walking and running to aperiodic jumping and standing. Our RL-based controller incorporates a novel dual-history architecture, utilizing both a long-term and short-term input/output (I/O) history of the robot. This control architecture, when trained through the proposed end-to-end RL approach, consistently outperforms other methods across a diverse range of skills in both simulation and the real world. The study also delves into the adaptivity and robustness introduced by the proposed RL system in developing locomotion controllers. We demonstrate that the proposed architecture can adapt to both time-invariant dynamics shifts and time-variant changes, such as contact events, by effectively using the robot's I/O history. Additionally, we identify task randomization as another key source of robustness, fostering better task generalization and compliance to disturbances. The resulting control policies can be successfully deployed on Cassie, a torque-controlled human-sized bipedal robot. This work pushes the limits of agility for bipedal robots through extensive real-world experiments. We demonstrate a diverse range of locomotion skills, including: robust standing, versatile walking, fast running with a demonstration of a 400-meter dash, and a diverse set of jumping skills, such as standing long jumps and high jumps.
Read more8/27/2024
🏅
0
Agile and versatile bipedal robot tracking control through reinforcement learning
Jiayi Li, Linqi Ye, Yi Cheng, Houde Liu, Bin Liang
The remarkable athletic intelligence displayed by humans in complex dynamic movements such as dancing and gymnastics suggests that the balance mechanism in biological beings is decoupled from specific movement patterns. This decoupling allows for the execution of both learned and unlearned movements under certain constraints while maintaining balance through minor whole-body coordination. To replicate this balance ability and body agility, this paper proposes a versatile controller for bipedal robots. This controller achieves ankle and body trajectory tracking across a wide range of gaits using a single small-scale neural network, which is based on a model-based IK solver and reinforcement learning. We consider a single step as the smallest control unit and design a universally applicable control input form suitable for any single-step variation. Highly flexible gait control can be achieved by combining these minimal control units with high-level policy through our extensible control interface. To enhance the trajectory-tracking capability of our controller, we utilize a three-stage training curriculum. After training, the robot can move freely between target footholds at varying distances and heights. The robot can also maintain static balance without repeated stepping to adjust posture. Finally, we evaluate the tracking accuracy of our controller on various bipedal tasks, and the effectiveness of our control framework is verified in the simulation environment.
Read more4/15/2024