A Point-Neighborhood Learning Framework for Nasal Endoscope Image Segmentation

0

Sign in to get full access
A Point-Neighborhood Learning Framework for Nasal Endoscope Image Segmentation
Overview
- This research paper presents a point-neighborhood learning framework for segmenting nasal endoscope images.
- The goal is to accurately identify and separate different anatomical structures, such as the nasal cavity, turbinates, and septum, within endoscopic images of the nasal passage.
- The proposed method leverages both local and global context to improve segmentation performance compared to existing approaches.
Plain English Explanation
The researchers have developed a new way to automatically identify and separate different parts of the nasal passage in images taken using a tiny camera inserted into the nose (called a nasal endoscope). This is an important task in medical imaging, as it allows doctors to clearly see the structures inside the nose and diagnose or monitor conditions more effectively.
The key idea is to use information about not just the individual pixels in the image, but also the pixels surrounding them (the "neighborhood"). This helps the algorithm better understand the overall shape and context of the different anatomical structures, rather than just looking at them in isolation. By combining this local and global information, the researchers were able to create a more accurate segmentation model compared to previous methods.
This type of advanced image analysis could ultimately lead to improved diagnosis and treatment of nasal and sinus problems, as doctors gain a clearer view of the underlying structures. The ability to precisely segment endoscope images also has applications in areas like surgical planning and training.
Technical Explanation
The proposed framework, called Point-Neighborhood Learning (PNL), uses a neural network architecture that learns features from both the individual pixels in the image and their local neighborhoods. This allows the model to capture both local details and broader contextual information.
The key components of the PNL framework include:
- A point-based encoder that extracts features from individual pixels
- A neighborhood-based encoder that learns features from the surrounding pixels
- A fusion module that combines the point and neighborhood features
- A segmentation head that produces the final pixel-wise segmentation map
The researchers also incorporate semi-supervised learning techniques, pseudo-labeling, and evidential learning to leverage both labeled and unlabeled data and improve performance, especially in situations with limited manual annotations.
The model is evaluated on a dataset of nasal endoscope images, demonstrating significant improvements in segmentation accuracy compared to previous state-of-the-art methods.
Critical Analysis
The paper provides a thorough technical explanation of the proposed PNL framework and presents convincing experimental results. However, a few potential limitations or areas for further research are worth considering:
- The dataset used for evaluation, while representative of nasal endoscope images, may not capture the full diversity of clinical scenarios. Testing the model's performance on a larger and more varied dataset could help assess its robustness.
- The paper does not delve into the computational efficiency or real-time performance of the PNL model, which could be an important practical consideration for its deployment in clinical settings.
- While the semi-supervised and pseudo-labeling techniques are shown to be effective, the reliance on these approaches may raise questions about the model's ability to generalize to new environments without access to large annotated datasets.
Overall, the PNL framework represents an interesting and promising approach to nasal endoscope image segmentation, with potential to improve clinical diagnosis and treatment. However, further research and validation may be needed to fully understand the method's capabilities and limitations.
Conclusion
This research paper presents a novel point-neighborhood learning framework for the segmentation of nasal endoscope images. By leveraging both local and global contextual information, the proposed model demonstrates superior performance compared to previous state-of-the-art methods.
The ability to accurately segment endoscopic images of the nasal passage could have important implications for medical diagnostics and treatment planning, allowing clinicians to better visualize and understand the underlying anatomical structures. While the current results are promising, further research is needed to fully assess the method's robustness and suitability for real-world clinical deployments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Point-Neighborhood Learning Framework for Nasal Endoscope Image Segmentation
Pengyu Jie, Wanquan Liu, Chenqiang Gao, Yihui Wen, Rui He, Pengcheng Li, Jintao Zhang, Deyu Meng
The lesion segmentation on endoscopic images is challenging due to its complex and ambiguous features. Fully-supervised deep learning segmentation methods can receive good performance based on entirely pixel-level labeled dataset but greatly increase experts' labeling burden. Semi-supervised and weakly supervised methods can ease labeling burden, but heavily strengthen the learning difficulty. To alleviate this difficulty, weakly semi-supervised segmentation adopts a new annotation protocol of adding a large number of point annotation samples into a few pixel-level annotation samples. However, existing methods only mine points' limited information while ignoring reliable prior surrounding the point annotations. In this paper, we propose a weakly semi-supervised method called Point-Neighborhood Learning (PNL) framework. To mine the prior of the pixels surrounding the annotated point, we transform a single-point annotation into a circular area named a point-neighborhood. We propose point-neighborhood supervision loss and pseudo-label scoring mechanism to enhance training supervision. Point-neighborhoods are also used to augment the data diversity. Our method greatly improves performance without changing the structure of segmentation network. Comprehensive experiments show the superiority of our method over the other existing methods, demonstrating its effectiveness in point-annotated medical images. The project code will be available on: https://github.com/ParryJay/PNL.
Read more5/31/2024
💬
0
Learning Semantic Segmentation with Query Points Supervision on Aerial Images
Santiago Rivier, Carlos Hinojosa, Silvio Giancola, Bernard Ghanem
Semantic segmentation is crucial in remote sensing, where high-resolution satellite images are segmented into meaningful regions. Recent advancements in deep learning have significantly improved satellite image segmentation. However, most of these methods are typically trained in fully supervised settings that require high-quality pixel-level annotations, which are expensive and time-consuming to obtain. In this work, we present a weakly supervised learning algorithm to train semantic segmentation algorithms that only rely on query point annotations instead of full mask labels. Our proposed approach performs accurate semantic segmentation and improves efficiency by significantly reducing the cost and time required for manual annotation. Specifically, we generate superpixels and extend the query point labels into those superpixels that group similar meaningful semantics. Then, we train semantic segmentation models supervised with images partially labeled with the superpixel pseudo-labels. We benchmark our weakly supervised training approach on an aerial image dataset and different semantic segmentation architectures, showing that we can reach competitive performance compared to fully supervised training while reducing the annotation effort. The code of our proposed approach is publicly available at: https://github.com/santiago2205/LSSQPS.
Read more8/7/2024
0
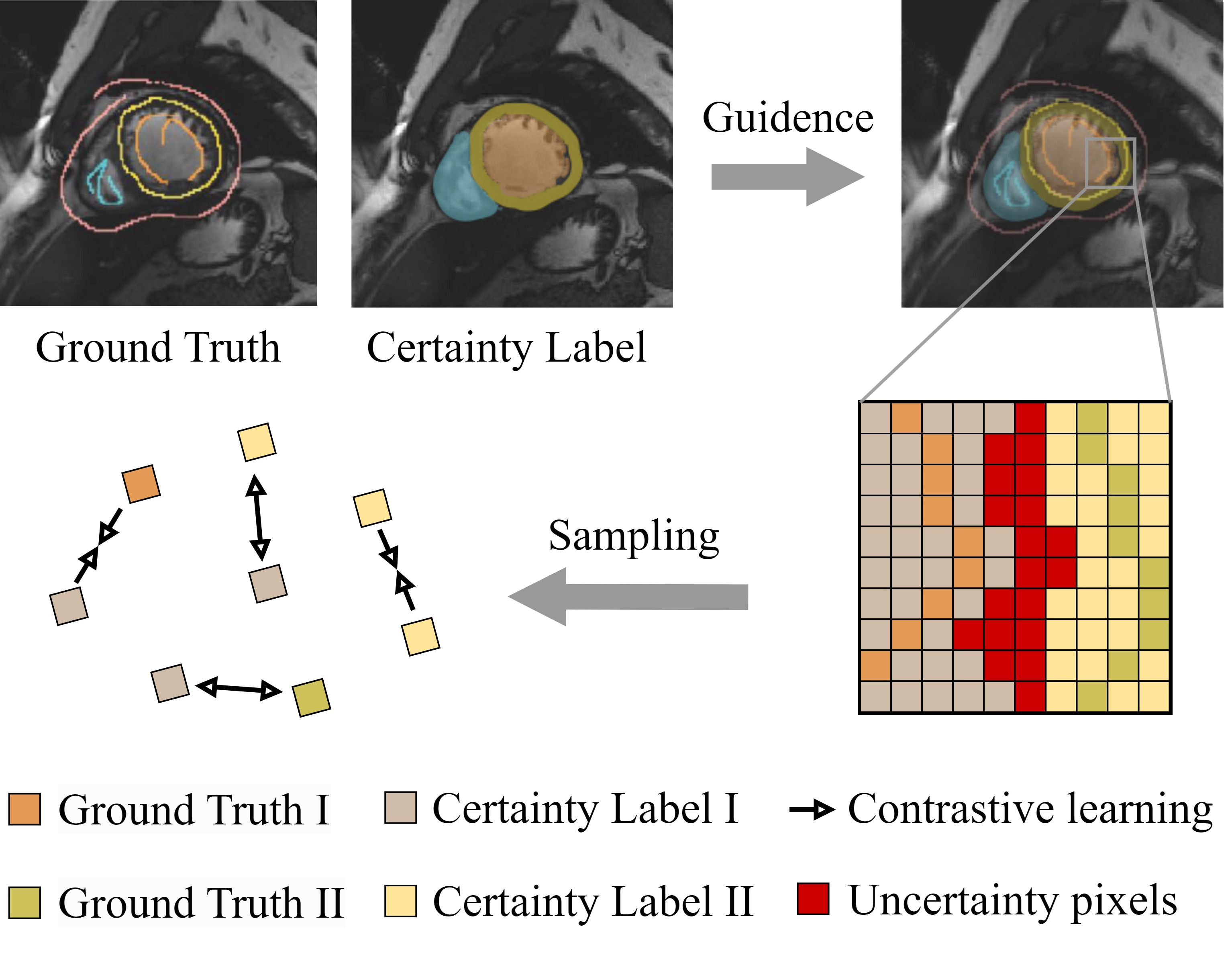
PCLMix: Weakly Supervised Medical Image Segmentation via Pixel-Level Contrastive Learning and Dynamic Mix Augmentation
Yu Lei, Haolun Luo, Lituan Wang, Zhenwei Zhang, Lei Zhang
In weakly supervised medical image segmentation, the absence of structural priors and the discreteness of class feature distribution present a challenge, i.e., how to accurately propagate supervision signals from local to global regions without excessively spreading them to other irrelevant regions? To address this, we propose a novel weakly supervised medical image segmentation framework named PCLMix, comprising dynamic mix augmentation, pixel-level contrastive learning, and consistency regularization strategies. Specifically, PCLMix is built upon a heterogeneous dual-decoder backbone, addressing the absence of structural priors through a strategy of dynamic mix augmentation during training. To handle the discrete distribution of class features, PCLMix incorporates pixel-level contrastive learning based on prediction uncertainty, effectively enhancing the model's ability to differentiate inter-class pixel differences and intra-class consistency. Furthermore, to reinforce segmentation consistency and robustness, PCLMix employs an auxiliary decoder for dual consistency regularization. In the inference phase, the auxiliary decoder will be dropped and no computation complexity is increased. Extensive experiments on the ACDC dataset demonstrate that PCLMix appropriately propagates local supervision signals to the global scale, further narrowing the gap between weakly supervised and fully supervised segmentation methods. Our code is available at https://github.com/Torpedo2648/PCLMix.
Read more5/21/2024

0
Dynamic Pseudo Label Optimization in Point-Supervised Nuclei Segmentation
Ziyue Wang, Ye Zhang, Yifeng Wang, Linghan Cai, Yongbing Zhang
Deep learning has achieved impressive results in nuclei segmentation, but the massive requirement for pixel-wise labels remains a significant challenge. To alleviate the annotation burden, existing methods generate pseudo masks for model training using point labels. However, the generated masks are inevitably different from the ground truth, and these dissimilarities are not handled reasonably during the network training, resulting in the subpar performance of the segmentation model. To tackle this issue, we propose a framework named DoNuSeg, enabling textbf{D}ynamic pseudo label textbf{O}ptimization in point-supervised textbf{Nu}clei textbf{Seg}mentation. Specifically, DoNuSeg takes advantage of class activation maps (CAMs) to adaptively capture regions with semantics similar to annotated points. To leverage semantic diversity in the hierarchical feature levels, we design a dynamic selection module to choose the optimal one among CAMs from different encoder blocks as pseudo masks. Meanwhile, a CAM-guided contrastive module is proposed to further enhance the accuracy of pseudo masks. In addition to exploiting the semantic information provided by CAMs, we consider location priors inherent to point labels, developing a task-decoupled structure for effectively differentiating nuclei. Extensive experiments demonstrate that DoNuSeg outperforms state-of-the-art point-supervised methods. The code is available at https://github.com/shinning0821/MICCAI24-DoNuSeg.
Read more6/26/2024