PDiscoFormer: Relaxing Part Discovery Constraints with Vision Transformers

0

Sign in to get full access
Overview
- PDiscoFormer is a new approach to part discovery in computer vision that uses vision transformers to relax the constraints of traditional part discovery methods.
- The paper proposes a novel transformer-based model that can identify object parts without requiring bounding box annotations or other strict constraints.
- The model achieves state-of-the-art performance on part discovery benchmarks while being more flexible and requiring less supervision than previous methods.
Plain English Explanation
In the field of computer vision, researchers often try to develop algorithms that can automatically identify the different parts or components that make up an object in an image. This is known as "part discovery." Traditional part discovery methods have often required a lot of detailed information or annotations about the objects, such as bounding boxes around each part.
PDiscoFormer: Relaxing Part Discovery Constraints with Vision Transformers proposes a new approach that uses a type of AI model called a "vision transformer" to make part discovery more flexible and require less supervision. Vision transformers are a newer type of neural network that have shown impressive performance on a variety of computer vision tasks.
The key idea behind PDiscoFormer is that by using a vision transformer as the core of the model, it can learn to identify object parts without needing the same level of detailed annotation or constraints as previous methods. Instead, the model can discover the parts in a more free-form, unsupervised way, simply by analyzing the patterns and structures in the visual data.
The paper demonstrates that PDiscoFormer achieves state-of-the-art results on standard part discovery benchmarks, while being more flexible and requiring less manual effort to set up than older approaches. This suggests that vision transformers could be a powerful tool for advancing part discovery and other computer vision tasks that traditionally required a lot of supervision and constraints.
Technical Explanation
PDiscoFormer introduces a novel transformer-based model for part discovery in computer vision. The core of the model is a vision transformer that takes in an image and learns to identify the different parts or components that make up the objects in the image.
Unlike previous part discovery methods, PDiscoFormer does not require detailed annotations such as bounding boxes around each part. Instead, the model uses a more free-form, unsupervised approach to discover the parts by learning from the inherent visual patterns and structures in the data.
The key architectural elements of PDiscoFormer include:
- A vision transformer backbone that encodes the input image
- A part discovery module that identifies distinct object parts from the transformer features
- A consistency loss that encourages the model to discover semantically meaningful parts
The model is trained end-to-end on part discovery benchmarks, and the paper demonstrates that PDiscoFormer achieves state-of-the-art performance while requiring less supervision than previous approaches.
A key insight is that the flexibility of vision transformers allows the model to discover object parts in a more natural, unconstrained way, rather than being limited by strict part annotations or bounding box requirements. This suggests that transformer-based approaches could be a promising direction for advancing part discovery and other computer vision tasks that have traditionally relied on heavily supervised learning.
Critical Analysis
The PDiscoFormer paper makes a compelling case for the use of vision transformers to relax the constraints of traditional part discovery methods. By leveraging the flexibility and unsupervised learning capabilities of transformers, the model is able to achieve strong results on part discovery benchmarks while requiring less manual effort and annotation than previous approaches.
However, the paper does acknowledge some limitations and areas for further research. For example, the model still relies on some degree of supervision in the form of consistency losses to guide the part discovery process. It would be interesting to see if completely unsupervised part discovery is possible using transformers.
Additionally, the paper only evaluates PDiscoFormer on a limited set of benchmarks and object categories. Further research would be needed to understand how well the approach generalizes to a wider range of part-based objects and tasks.
Another potential area for improvement could be in the interpretability and explainability of the discovered parts. While the paper shows that the model can identify semantically meaningful parts, it's not always clear why the model chooses to segment an object in a particular way. Techniques for improving the interpretability of transformer-based part discovery could be a valuable direction.
Overall, the PDiscoFormer paper represents an exciting step forward in the use of vision transformers for part discovery and other computer vision challenges. The flexibility and unsupervised learning capabilities of transformers offer promising avenues for advancing the field, and the results in this paper suggest that further research in this direction could yield valuable insights and breakthroughs.
Conclusion
PDiscoFormer introduces a novel transformer-based approach to part discovery in computer vision that relaxes the constraints of traditional methods. By leveraging the flexibility and unsupervised learning capabilities of vision transformers, the model is able to achieve state-of-the-art performance on part discovery benchmarks while requiring less supervision and manual effort than previous approaches.
The key innovation of PDiscoFormer is its ability to discover semantically meaningful object parts in a more free-form, unconstrained way, rather than being limited by strict part annotations or bounding box requirements. This suggests that transformer-based models could be a promising direction for advancing part discovery and other computer vision tasks that have traditionally relied on heavily supervised learning.
While the paper demonstrates the potential of this approach, it also highlights areas for further research, such as improving the interpretability of the discovered parts and exploring completely unsupervised part discovery. Overall, the PDiscoFormer paper represents an exciting step forward in the use of vision transformers for computer vision, and the insights and techniques developed in this work could have broader implications for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PDiscoFormer: Relaxing Part Discovery Constraints with Vision Transformers
Ananthu Aniraj, Cassio F. Dantas, Dino Ienco, Diego Marcos
Computer vision methods that explicitly detect object parts and reason on them are a step towards inherently interpretable models. Existing approaches that perform part discovery driven by a fine-grained classification task make very restrictive assumptions on the geometric properties of the discovered parts; they should be small and compact. Although this prior is useful in some cases, in this paper we show that pre-trained transformer-based vision models, such as self-supervised DINOv2 ViT, enable the relaxation of these constraints. In particular, we find that a total variation (TV) prior, which allows for multiple connected components of any size, substantially outperforms previous work. We test our approach on three fine-grained classification benchmarks: CUB, PartImageNet and Oxford Flowers, and compare our results to previously published methods as well as a re-implementation of the state-of-the-art method PDiscoNet with a transformer-based backbone. We consistently obtain substantial improvements across the board, both on part discovery metrics and the downstream classification task, showing that the strong inductive biases in self-supervised ViT models require to rethink the geometric priors that can be used for unsupervised part discovery.
Read more7/23/2024

0
Unsupervised Part Discovery via Dual Representation Alignment
Jiahao Xia, Wenjian Huang, Min Xu, Jianguo Zhang, Haimin Zhang, Ziyu Sheng, Dong Xu
Object parts serve as crucial intermediate representations in various downstream tasks, but part-level representation learning still has not received as much attention as other vision tasks. Previous research has established that Vision Transformer can learn instance-level attention without labels, extracting high-quality instance-level representations for boosting downstream tasks. In this paper, we achieve unsupervised part-specific attention learning using a novel paradigm and further employ the part representations to improve part discovery performance. Specifically, paired images are generated from the same image with different geometric transformations, and multiple part representations are extracted from these paired images using a novel module, named PartFormer. These part representations from the paired images are then exchanged to improve geometric transformation invariance. Subsequently, the part representations are aligned with the feature map extracted by a feature map encoder, achieving high similarity with the pixel representations of the corresponding part regions and low similarity in irrelevant regions. Finally, the geometric and semantic constraints are applied to the part representations through the intermediate results in alignment for part-specific attention learning, encouraging the PartFormer to focus locally and the part representations to explicitly include the information of the corresponding parts. Moreover, the aligned part representations can further serve as a series of reliable detectors in the testing phase, predicting pixel masks for part discovery. Extensive experiments are carried out on four widely used datasets, and our results demonstrate that the proposed method achieves competitive performance and robustness due to its part-specific attention.
Read more8/16/2024
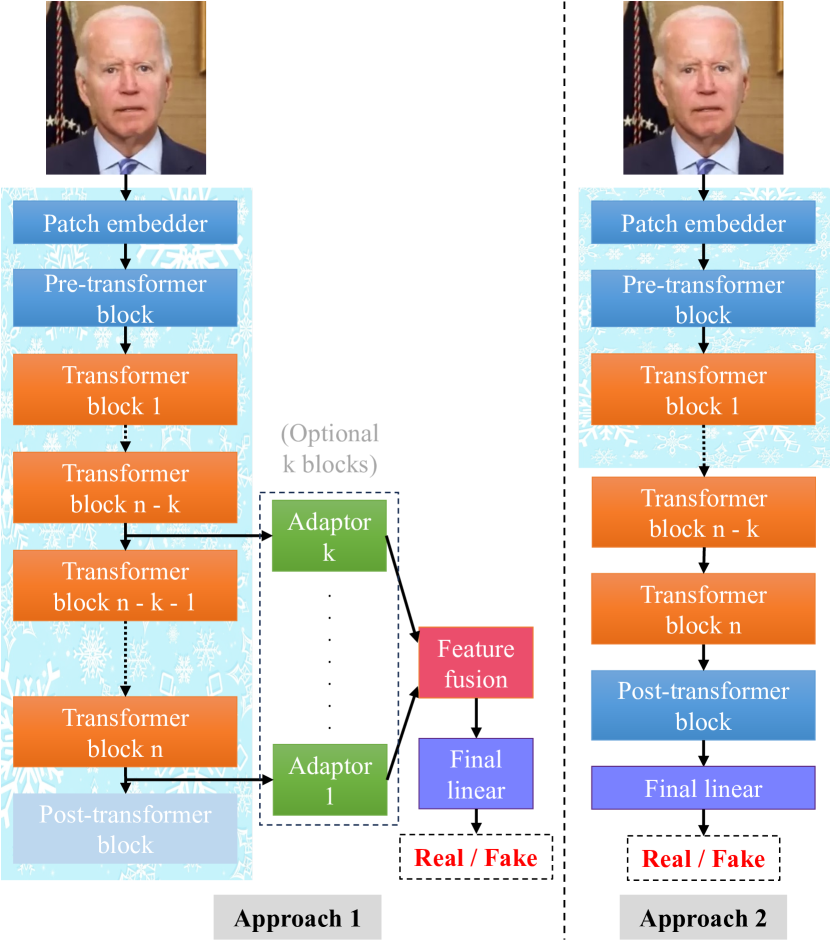
0
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
This paper investigates the effectiveness of self-supervised pre-trained vision transformers (ViTs) compared to supervised pre-trained ViTs and conventional neural networks (ConvNets) for detecting facial deepfake images and videos. It examines their potential for improved generalization and explainability, especially with limited training data. Despite the success of transformer architectures in various tasks, the deepfake detection community is hesitant to use large ViTs as feature extractors due to their perceived need for extensive data and suboptimal generalization with small datasets. This contrasts with ConvNets, which are already established as robust feature extractors. Additionally, training ViTs from scratch requires significant resources, limiting their use to large companies. Recent advancements in self-supervised learning (SSL) for ViTs, like masked autoencoders and DINOs, show adaptability across diverse tasks and semantic segmentation capabilities. By leveraging SSL ViTs for deepfake detection with modest data and partial fine-tuning, we find comparable adaptability to deepfake detection and explainability via the attention mechanism. Moreover, partial fine-tuning of ViTs is a resource-efficient option.
Read more8/12/2024
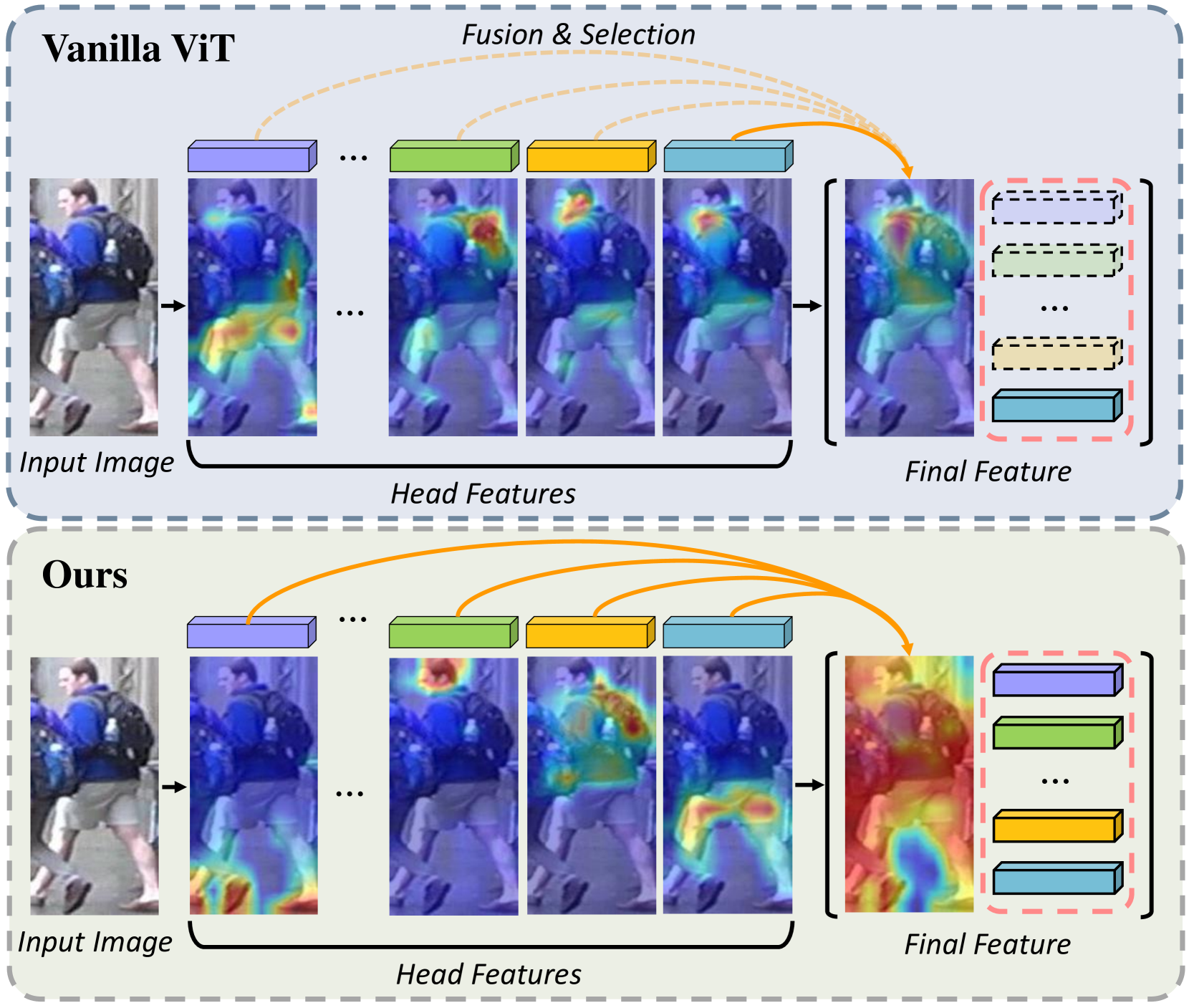
0
PartFormer: Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification
Lei Tan, Pingyang Dai, Jie Chen, Liujuan Cao, Yongjian Wu, Rongrong Ji
Extracting robust feature representation is critical for object re-identification to accurately identify objects across non-overlapping cameras. Although having a strong representation ability, the Vision Transformer (ViT) tends to overfit on most distinct regions of training data, limiting its generalizability and attention to holistic object features. Meanwhile, due to the structural difference between CNN and ViT, fine-grained strategies that effectively address this issue in CNN do not continue to be successful in ViT. To address this issue, by observing the latent diverse representation hidden behind the multi-head attention, we present PartFormer, an innovative adaptation of ViT designed to overcome the granularity limitations in object Re-ID tasks. The PartFormer integrates a Head Disentangling Block (HDB) that awakens the diverse representation of multi-head self-attention without the typical loss of feature richness induced by concatenation and FFN layers post-attention. To avoid the homogenization of attention heads and promote robust part-based feature learning, two head diversity constraints are imposed: attention diversity constraint and correlation diversity constraint. These constraints enable the model to exploit diverse and discriminative feature representations from different attention heads. Comprehensive experiments on various object Re-ID benchmarks demonstrate the superiority of the PartFormer. Specifically, our framework significantly outperforms state-of-the-art by 2.4% mAP scores on the most challenging MSMT17 dataset.
Read more8/30/2024