PDSR: A Privacy-Preserving Diversified Service Recommendation Method on Distributed Data

0

Sign in to get full access
Overview
- A privacy-preserving and diversified service recommendation method called PDSR
- Designed to provide personalized recommendations while protecting user privacy across distributed data sources
- Addresses the challenges of data fragmentation and heterogeneity in recommender systems
Plain English Explanation
The paper presents a new method called PDSR (Privacy-preserving Diversified Service Recommendation) that aims to provide personalized service recommendations while also protecting user privacy. One of the key challenges in recommendation systems is that user data is often spread across different sources, making it difficult to get a complete picture of user preferences. PDSR tackles this by allowing different data owners to collaborate on recommendations without sharing sensitive user data.
PDSR uses a technique called differential privacy to add noise to the data, which protects individual user information. It also incorporates diversity in the recommendations to ensure users are presented with a broad range of options, rather than just the most popular items. This helps users discover new and potentially more relevant services.
The paper demonstrates through experiments that PDSR can provide accurate and diverse recommendations while preserving user privacy, even when the data is fragmented across multiple sources. This approach could be valuable in industries like e-commerce, entertainment, and healthcare, where personalized recommendations are important but user privacy is a major concern.
Technical Explanation
The PDSR method consists of three main components:
-
Differential Privacy-based Data Aggregation: PDSR uses differential privacy to aggregate user preference data from multiple sources without revealing individual user information. This involves adding carefully calibrated noise to the data to protect privacy.
-
Diversified Recommendation Model: PDSR incorporates a diversification step into the recommendation model to ensure a broad range of relevant items are suggested to each user, rather than just the most popular options.
-
Distributed Optimization: PDSR optimizes the recommendation model in a distributed manner, allowing different data owners to collaborate on the recommendations without sharing their raw data.
The paper evaluates PDSR on several real-world datasets and compares its performance to other state-of-the-art recommendation methods. The results show that PDSR can achieve high recommendation accuracy and diversity while maintaining strong privacy guarantees, even when user data is fragmented across multiple sources.
Critical Analysis
The paper provides a comprehensive solution to the challenge of privacy-preserving and diversified recommendations in distributed data environments. By incorporating differential privacy and diversification techniques, PDSR addresses important limitations of traditional recommendation systems.
One potential limitation is that the paper does not explore the computational complexity and scalability of the PDSR method, which could be a concern for large-scale real-world applications. Additionally, the paper does not discuss the impact of different levels of noise addition on recommendation quality, which could be an area for further investigation.
Overall, the PDSR method represents a promising approach to balancing personalization, diversity, and privacy in recommender systems. Future research could explore ways to further optimize the performance and efficiency of the system, as well as its applicability to a wider range of domains.
Conclusion
The PDSR method presented in this paper offers a novel solution for providing personalized and diverse service recommendations while preserving user privacy in distributed data environments. By leveraging differential privacy and diversification techniques, PDSR demonstrates the ability to generate accurate and relevant recommendations without compromising individual user information.
This research has important implications for the development of privacy-preserving recommender systems, which are increasingly crucial in industries where personalization and user trust are paramount. The PDSR approach could be particularly valuable in sectors such as e-commerce, entertainment, and healthcare, where personalized recommendations are highly sought after but user privacy concerns remain a significant challenge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PDSR: A Privacy-Preserving Diversified Service Recommendation Method on Distributed Data
Lina Wang, Huan Yang, Yiran Shen, Chao Liu, Lianyong Qi, Xiuzhen Cheng, Feng Li
The last decade has witnessed a tremendous growth of service computing, while efficient service recommendation methods are desired to recommend high-quality services to users. It is well known that collaborative filtering is one of the most popular methods for service recommendation based on QoS, and many existing proposals focus on improving recommendation accuracy, i.e., recommending high-quality redundant services. Nevertheless, users may have different requirements on QoS, and hence diversified recommendation has been attracting increasing attention in recent years to fulfill users' diverse demands and to explore potential services. Unfortunately, the recommendation performances relies on a large volume of data (e.g., QoS data), whereas the data may be distributed across multiple platforms. Therefore, to enable data sharing across the different platforms for diversified service recommendation, we propose a Privacy-preserving Diversified Service Recommendation (PDSR) method. Specifically, we innovate in leveraging the Locality-Sensitive Hashing (LSH) mechanism such that privacy-preserved data sharing across different platforms is enabled to construct a service similarity graph. Based on the similarity graph, we propose a novel accuracy-diversity metric and design a $2$-approximation algorithm to select $K$ services to recommend by maximizing the accuracy-diversity measure. Extensive experiments on real datasets are conducted to verify the efficacy of our PDSR method.
Read more8/29/2024

0
Privacy-preserving recommender system using the data collaboration analysis for distributed datasets
Tomoya Yanagi, Shunnosuke Ikeda, Noriyoshi Sukegawa, Yuichi Takano
In order to provide high-quality recommendations for users, it is desirable to share and integrate multiple datasets held by different parties. However, when sharing such distributed datasets, we need to protect personal and confidential information contained in the datasets. To this end, we establish a framework for privacy-preserving recommender systems using the data collaboration analysis of distributed datasets. Numerical experiments with two public rating datasets demonstrate that our privacy-preserving method for rating prediction can improve the prediction accuracy for distributed datasets. This study opens up new possibilities for privacy-preserving techniques in recommender systems.
Read more6/5/2024
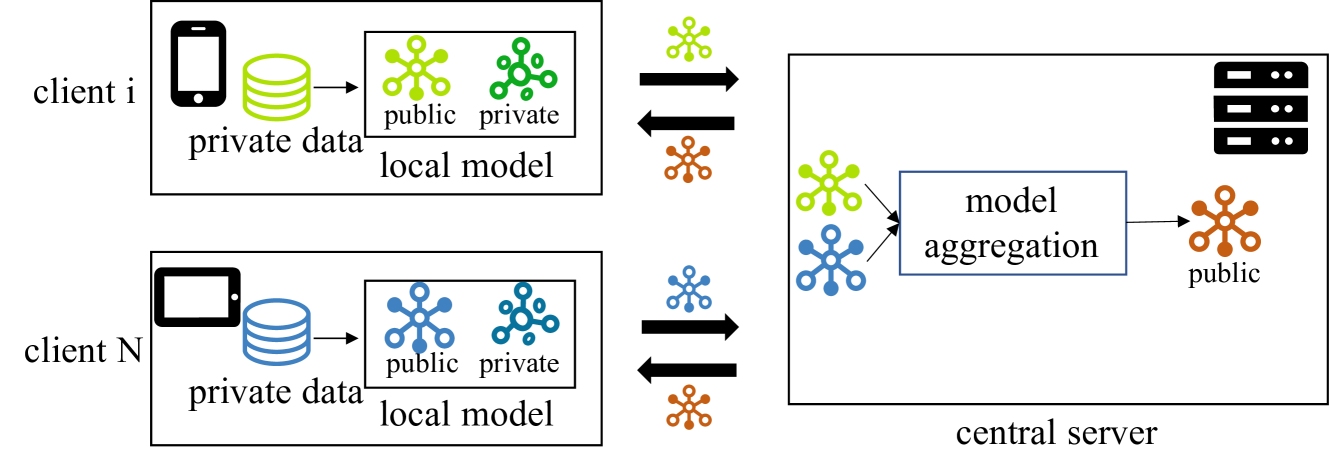
0
PDC-FRS: Privacy-preserving Data Contribution for Federated Recommender System
Chaoqun Yang, Wei Yuan, Liang Qu, Thanh Tam Nguyen
Federated recommender systems (FedRecs) have emerged as a popular research direction for protecting users' privacy in on-device recommendations. In FedRecs, users keep their data locally and only contribute their local collaborative information by uploading model parameters to a central server. While this rigid framework protects users' raw data during training, it severely compromises the recommendation model's performance due to the following reasons: (1) Due to the power law distribution nature of user behavior data, individual users have few data points to train a recommendation model, resulting in uploaded model updates that may be far from optimal; (2) As each user's uploaded parameters are learned from local data, which lacks global collaborative information, relying solely on parameter aggregation methods such as FedAvg to fuse global collaborative information may be suboptimal. To bridge this performance gap, we propose a novel federated recommendation framework, PDC-FRS. Specifically, we design a privacy-preserving data contribution mechanism that allows users to share their data with a differential privacy guarantee. Based on the shared but perturbed data, an auxiliary model is trained in parallel with the original federated recommendation process. This auxiliary model enhances FedRec by augmenting each user's local dataset and integrating global collaborative information. To demonstrate the effectiveness of PDC-FRS, we conduct extensive experiments on two widely used recommendation datasets. The empirical results showcase the superiority of PDC-FRS compared to baseline methods.
Read more9/14/2024
✨
0
Multi-Resolution Diffusion for Privacy-Sensitive Recommender Systems
Derek Lilienthal, Paul Mello, Magdalini Eirinaki, Stas Tiomkin
While recommender systems have become an integral component of the Web experience, their heavy reliance on user data raises privacy and security concerns. Substituting user data with synthetic data can address these concerns, but accurately replicating these real-world datasets has been a notoriously challenging problem. Recent advancements in generative AI have demonstrated the impressive capabilities of diffusion models in generating realistic data across various domains. In this work we introduce a Score-based Diffusion Recommendation Module (SDRM), which captures the intricate patterns of real-world datasets required for training highly accurate recommender systems. SDRM allows for the generation of synthetic data that can replace existing datasets to preserve user privacy, or augment existing datasets to address excessive data sparsity. Our method outperforms competing baselines such as generative adversarial networks, variational autoencoders, and recently proposed diffusion models in synthesizing various datasets to replace or augment the original data by an average improvement of 4.30% in Recall@k and 4.65% in NDCG@k.
Read more6/21/2024