Privacy-preserving recommender system using the data collaboration analysis for distributed datasets

0

Sign in to get full access
Overview
- This paper proposes a privacy-preserving recommender system that uses data collaboration analysis for distributed datasets.
- The system aims to provide personalized movie recommendations while preserving user privacy by using federated learning and differential privacy techniques.
- The researchers evaluate their approach on real-world datasets and compare it to existing methods, demonstrating its effectiveness in terms of both recommendation quality and privacy protection.
Plain English Explanation
The paper discusses a new way to provide personalized movie recommendations while protecting people's privacy. The researchers developed a system that uses a technique called federated learning to train a recommendation model without needing to access users' personal data. Instead, the model learns from data that is kept private on each user's device.
To further enhance privacy, the system also incorporates differential privacy techniques. This means the recommendation results are slightly "noisy" or altered in a way that makes it very difficult to identify individual users or their preferences.
The researchers tested their approach on real-world movie rating datasets and compared it to other privacy-preserving recommendation methods. They found that their system was able to provide high-quality movie recommendations while effectively protecting user privacy, outperforming the alternatives.
This type of privacy-preserving recommender system could be very useful for companies and services that want to provide personalized recommendations to users without compromising their personal information. It aligns with the growing focus on data privacy and security in the field of recommender systems.
Technical Explanation
The proposed privacy-preserving recommender system uses a federated learning approach to train a recommendation model without centralizing user data. In federated learning, the model is trained on data distributed across many user devices, with only model updates (not raw data) being shared with a central server.
To further enhance privacy, the researchers incorporate differential privacy techniques. Differential privacy introduces controlled amounts of noise into the model updates, making it very difficult to infer information about individual users from the shared data.
The system's architecture consists of a central server that coordinates the federated learning process and a set of user devices that participate in the model training. The researchers evaluate their approach on two real-world movie rating datasets, comparing it to existing privacy-preserving recommendation methods, such as matrix factorization with differential privacy and federated collaborative filtering.
The results show that the proposed system achieves competitive recommendation accuracy while providing strong privacy guarantees, outperforming the baseline methods in terms of both recommendation quality and privacy protection.
Critical Analysis
The paper provides a thorough evaluation of the proposed privacy-preserving recommender system, but it also acknowledges several limitations and areas for future research:
- The system is evaluated on movie rating datasets, which may not fully capture the complexities of real-world recommendation scenarios. Further testing on a wider range of datasets would be valuable.
- The differential privacy techniques used in the system introduce a trade-off between privacy and recommendation quality. The researchers suggest exploring more advanced privacy-preserving mechanisms to optimize this balance.
- The federated learning process assumes that user devices are always available and connected to the central server. In practice, there may be challenges related to device availability and network connectivity that need to be addressed.
- The paper does not discuss the computational and communication overhead associated with the federated learning and differential privacy components of the system. These practical considerations should be examined in future work.
Overall, the research presents a promising approach to privacy-preserving recommendations, but there are still opportunities to refine and expand the techniques to make them more robust and applicable to real-world scenarios.
Conclusion
This paper introduces a novel privacy-preserving recommender system that leverages federated learning and differential privacy to provide personalized recommendations while protecting user data. The researchers demonstrate the effectiveness of their approach through experiments on real-world datasets, showing that it can achieve high recommendation accuracy while offering strong privacy guarantees.
The proposed system represents an important step forward in the field of data-centric recommender systems, where the focus is on developing techniques that respect user privacy and security. As data privacy becomes an increasingly critical concern, this type of privacy-preserving recommendation technology could become increasingly valuable for a wide range of applications and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Privacy-preserving recommender system using the data collaboration analysis for distributed datasets
Tomoya Yanagi, Shunnosuke Ikeda, Noriyoshi Sukegawa, Yuichi Takano
In order to provide high-quality recommendations for users, it is desirable to share and integrate multiple datasets held by different parties. However, when sharing such distributed datasets, we need to protect personal and confidential information contained in the datasets. To this end, we establish a framework for privacy-preserving recommender systems using the data collaboration analysis of distributed datasets. Numerical experiments with two public rating datasets demonstrate that our privacy-preserving method for rating prediction can improve the prediction accuracy for distributed datasets. This study opens up new possibilities for privacy-preserving techniques in recommender systems.
Read more6/5/2024
👀
0
A Privacy Preserving System for Movie Recommendations Using Federated Learning
David Neumann, Andreas Lutz, Karsten Muller, Wojciech Samek
Recommender systems have become ubiquitous in the past years. They solve the tyranny of choice problem faced by many users, and are utilized by many online businesses to drive engagement and sales. Besides other criticisms, like creating filter bubbles within social networks, recommender systems are often reproved for collecting considerable amounts of personal data. However, to personalize recommendations, personal information is fundamentally required. A recent distributed learning scheme called federated learning has made it possible to learn from personal user data without its central collection. Consequently, we present a recommender system for movie recommendations, which provides privacy and thus trustworthiness on multiple levels: First and foremost, it is trained using federated learning and thus, by its very nature, privacy-preserving, while still enabling users to benefit from global insights. Furthermore, a novel federated learning scheme, called FedQ, is employed, which not only addresses the problem of non-i.i.d.-ness and small local datasets, but also prevents input data reconstruction attacks by aggregating client updates early. Finally, to reduce the communication overhead, compression is applied, which significantly compresses the exchanged neural network parametrizations to a fraction of their original size. We conjecture that this may also improve data privacy through its lossy quantization stage.
Read more5/17/2024
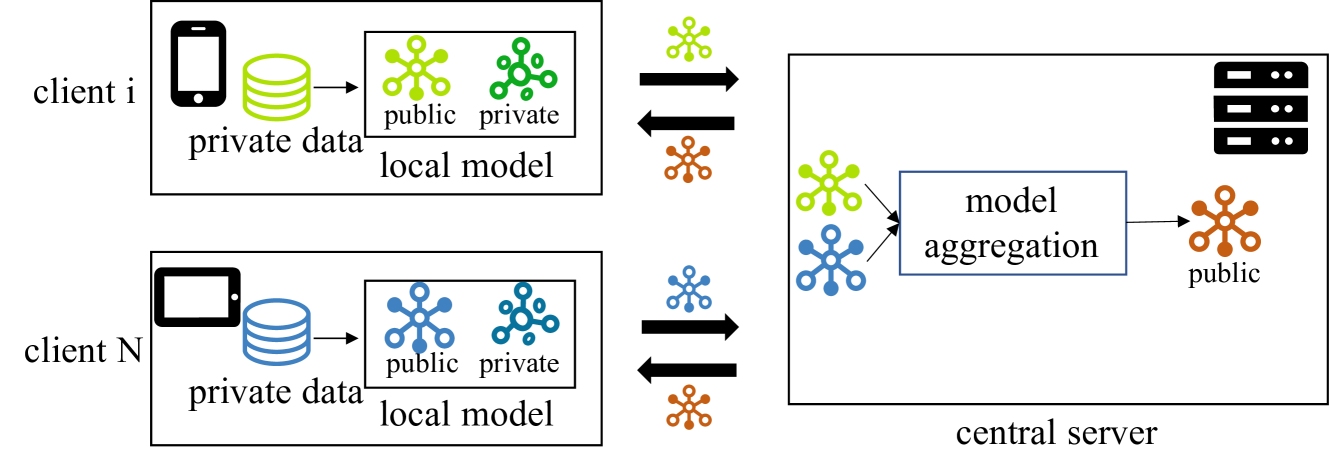
0
PDC-FRS: Privacy-preserving Data Contribution for Federated Recommender System
Chaoqun Yang, Wei Yuan, Liang Qu, Thanh Tam Nguyen
Federated recommender systems (FedRecs) have emerged as a popular research direction for protecting users' privacy in on-device recommendations. In FedRecs, users keep their data locally and only contribute their local collaborative information by uploading model parameters to a central server. While this rigid framework protects users' raw data during training, it severely compromises the recommendation model's performance due to the following reasons: (1) Due to the power law distribution nature of user behavior data, individual users have few data points to train a recommendation model, resulting in uploaded model updates that may be far from optimal; (2) As each user's uploaded parameters are learned from local data, which lacks global collaborative information, relying solely on parameter aggregation methods such as FedAvg to fuse global collaborative information may be suboptimal. To bridge this performance gap, we propose a novel federated recommendation framework, PDC-FRS. Specifically, we design a privacy-preserving data contribution mechanism that allows users to share their data with a differential privacy guarantee. Based on the shared but perturbed data, an auxiliary model is trained in parallel with the original federated recommendation process. This auxiliary model enhances FedRec by augmenting each user's local dataset and integrating global collaborative information. To demonstrate the effectiveness of PDC-FRS, we conduct extensive experiments on two widely used recommendation datasets. The empirical results showcase the superiority of PDC-FRS compared to baseline methods.
Read more9/14/2024
➖
0
Advancements in Recommender Systems: A Comprehensive Analysis Based on Data, Algorithms, and Evaluation
Xin Ma, Mingyue Li, Xuguang Liu
Using 286 research papers collected from Web of Science, ScienceDirect, SpringerLink, arXiv, and Google Scholar databases, a systematic review methodology was adopted to review and summarize the current challenges and potential future developments in data, algorithms, and evaluation aspects of RSs. It was found that RSs involve five major research topics, namely algorithmic improvement, domain applications, user behavior & cognition, data processing & modeling, and social impact & ethics. Collaborative filtering and hybrid recommendation techniques are mainstream. The performance of RSs is jointly limited by four types of eight data issues, two types of twelve algorithmic issues, and two evaluation issues. Notably, data-related issues such as cold start, data sparsity, and data poisoning, algorithmic issues like interest drift, device-cloud collaboration, non-causal driven, and multitask conflicts, along with evaluation issues such as offline data leakage and multi-objective balancing, have prominent impacts. Fusing physiological signals for multimodal modeling, defending against data poisoning through user information behavior, evaluating generative recommendations via social experiments, fine-tuning pre-trained large models to schedule device-cloud resource, enhancing causal inference with deep reinforcement learning, training multi-task models based on probability distributions, using cross-temporal dataset partitioning, and evaluating recommendation objectives across the full lifecycle are feasible solutions to address the aforementioned prominent challenges and unlock the power and value of RSs.The collected literature is mainly based on major international databases, and future research will further expand upon it.
Read more7/30/2024