PECTP: Parameter-Efficient Cross-Task Prompts for Incremental Vision Transformer

0

Sign in to get full access
Overview
- This research paper introduces PECTP, a technique for Incremental Vision Transformer that uses parameter-efficient cross-task prompts.
- The key ideas are:
- Developing prompts that can be efficiently transferred across different computer vision tasks.
- Enabling incremental learning of new tasks without catastrophic forgetting of previous ones.
- Maintaining high performance on individual tasks compared to finetuning the entire model.
Plain English Explanation
The paper describes a new way to train vision transformers to work on multiple visual tasks, like image classification or object detection, without forgetting how to do the earlier tasks.
The key innovation is parameter-efficient cross-task prompts (PECTP). Prompts are short sequences of text that can be added to the input of a pre-trained model to guide it towards a specific task. The researchers show that they can develop prompts that work well across different vision tasks, rather than needing a separate prompt for each task.
This allows the model to learn new tasks incrementally, adding them one-by-one, without forgetting how to do the earlier tasks (a problem known as catastrophic forgetting). And it does this while using far fewer additional parameters compared to fine-tuning the entire model for each new task.
Technical Explanation
The paper presents the PECTP technique for enabling incremental learning in vision transformers. The key components are:
- Cross-Task Prompts: The researchers design a prompt encoder module that can generate prompts that are effective across multiple vision tasks, rather than requiring a separate prompt for each task.
- Incremental Learning: By appending the cross-task prompts to the input of the vision transformer, the model can learn new tasks sequentially without forgetting how to do the earlier ones.
- Parameter Efficiency: Updating only the prompt encoder, rather than the entire vision transformer, results in a more parameter-efficient approach compared to full model fine-tuning.
Experiments on standard benchmarks like ImageNet, CIFAR-100, and MS-COCO show that PECTP can match the performance of fine-tuning the full model, while using orders of magnitude fewer additional parameters.
Critical Analysis
The paper makes a strong case for the PECTP approach, demonstrating its effectiveness on a range of computer vision tasks. Some potential limitations and areas for future work include:
- The prompts are still task-specific, even if they can be shared across tasks. Developing truly task-agnostic prompts could further improve parameter efficiency.
- The experiments focus on a relatively narrow set of vision tasks. Evaluating PECTP on a broader range of applications, including multi-modal tasks, would help validate its wider applicability.
- The paper does not explore the interpretability or the "reasoning" behind the generated prompts. Understanding what semantic information the prompts capture could lead to further insights.
Overall, PECTP is a promising technique that advances the state-of-the-art in parameter-efficient incremental learning for vision transformers.
Conclusion
This paper introduces PECTP, a novel approach for enabling incremental learning in vision transformers. By developing cross-task prompts that can be efficiently transferred between different visual tasks, the method allows models to learn new capabilities without forgetting old ones, while using far fewer additional parameters compared to full model fine-tuning.
The strong empirical results on standard benchmarks suggest that PECTP is an important step towards building more flexible and scalable computer vision systems. As AI models become increasingly powerful and ubiquitous, techniques like this that can adapt and grow without catastrophic forgetting will be crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PECTP: Parameter-Efficient Cross-Task Prompts for Incremental Vision Transformer
Qian Feng, Hanbin Zhao, Chao Zhang, Jiahua Dong, Henghui Ding, Yu-Gang Jiang, Hui Qian
Incremental Learning (IL) aims to learn deep models on sequential tasks continually, where each new task includes a batch of new classes and deep models have no access to task-ID information at the inference time. Recent vast pre-trained models (PTMs) have achieved outstanding performance by prompt technique in practical IL without the old samples (rehearsal-free) and with a memory constraint (memory-constrained): Prompt-extending and Prompt-fixed methods. However, prompt-extending methods need a large memory buffer to maintain an ever-expanding prompt pool and meet an extra challenging prompt selection problem. Prompt-fixed methods only learn a single set of prompts on one of the incremental tasks and can not handle all the incremental tasks effectively. To achieve a good balance between the memory cost and the performance on all the tasks, we propose a Parameter-Efficient Cross-Task Prompt (PECTP) framework with Prompt Retention Module (PRM) and classifier Head Retention Module (HRM). To make the final learned prompts effective on all incremental tasks, PRM constrains the evolution of cross-task prompts' parameters from Outer Prompt Granularity and Inner Prompt Granularity. Besides, we employ HRM to inherit old knowledge in the previously learned classifier heads to facilitate the cross-task prompts' generalization ability. Extensive experiments show the effectiveness of our method. The source codes will be available at url{https://github.com/RAIAN08/PECTP}.
Read more7/8/2024

0
CVPT: Cross-Attention help Visual Prompt Tuning adapt visual task
Lingyun Huang, Jianxu Mao, Yaonan Wang, Junfei Yi, Ziming Tao
In recent years, the rapid expansion of model sizes has led to large-scale pre-trained models demonstrating remarkable capabilities. Consequently, there has been a trend towards increasing the scale of models. However, this trend introduces significant challenges, including substantial computational costs of training and transfer to downstream tasks. To address these issues, Parameter-Efficient Fine-Tuning (PEFT) methods have been introduced. These methods optimize large-scale pre-trained models for specific tasks by fine-tuning a select group of parameters. Among these PEFT methods, adapter-based and prompt-based methods are the primary techniques. Specifically, in the field of visual fine-tuning, adapters gain prominence over prompts because of the latter's relatively weaker performance and efficiency. Under the circumstances, we refine the widely-used Visual Prompt Tuning (VPT) method, proposing Cross Visual Prompt Tuning (CVPT). CVPT calculates cross-attention between the prompt tokens and the embedded tokens, which allows us to compute the semantic relationship between them and conduct the fine-tuning of models exactly to adapt visual tasks better. Furthermore, we introduce the weight-sharing mechanism to initialize the parameters of cross-attention, which avoids massive learnable parameters from cross-attention and enhances the representative capability of cross-attention. We conduct comprehensive testing across 25 datasets and the result indicates that CVPT significantly improves VPT's performance and efficiency in visual tasks. For example, on the VTAB-1K benchmark, CVPT outperforms VPT over 4% in average accuracy, rivaling the advanced adapter-based methods in performance and efficiency. Our experiments confirm that prompt-based methods can achieve exceptional results in visual fine-tuning.
Read more8/28/2024
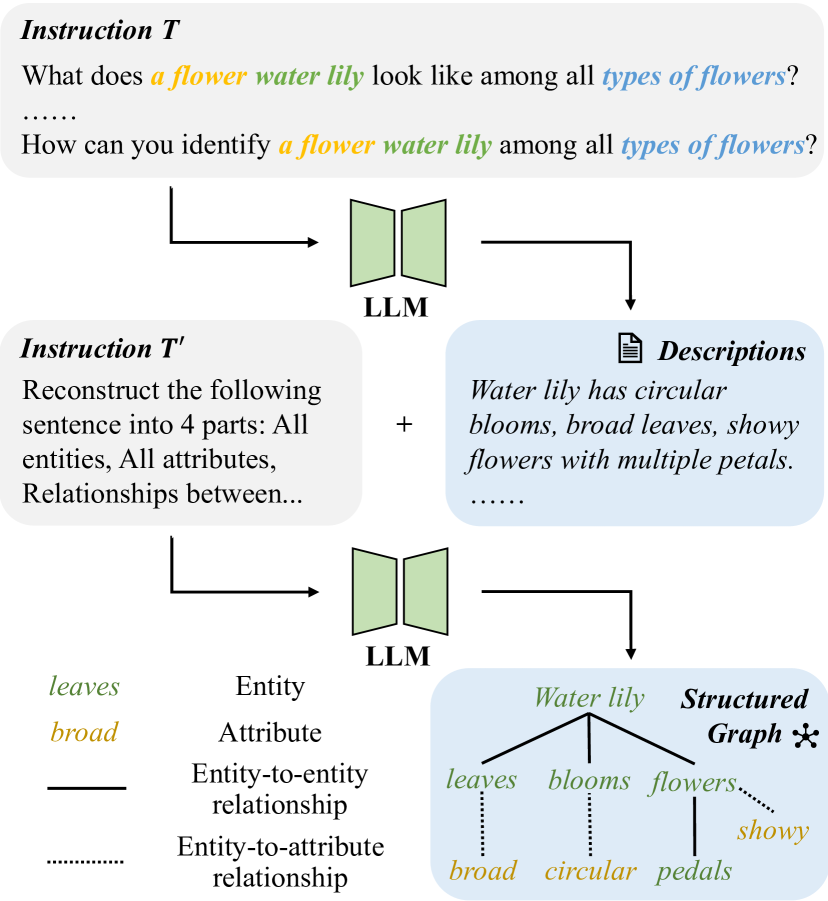
0
HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling
Yubin Wang, Xinyang Jiang, De Cheng, Wenli Sun, Dongsheng Li, Cairong Zhao
Prompt learning has become a prevalent strategy for adapting vision-language foundation models (VLMs) such as CLIP to downstream tasks. With the emergence of large language models (LLMs), recent studies have explored the potential of using category-related descriptions to enhance prompt effectiveness. However, conventional descriptions lack explicit structured information necessary to represent the interconnections among key elements like entities or attributes with relation to a particular category. Since existing prompt tuning methods give little consideration to managing structured knowledge, this paper advocates leveraging LLMs to construct a graph for each description to prioritize such structured knowledge. Consequently, we propose a novel approach called Hierarchical Prompt Tuning (HPT), enabling simultaneous modeling of both structured and conventional linguistic knowledge. Specifically, we introduce a relationship-guided attention module to capture pair-wise associations among entities and attributes for low-level prompt learning. In addition, by incorporating high-level and global-level prompts modeling overall semantics, the proposed hierarchical structure forges cross-level interlinks and empowers the model to handle more complex and long-term relationships. Finally, by enhancing multi-granularity knowledge generation, redesigning the relationship-driven attention re-weighting module, and incorporating consistent constraints on the hierarchical text encoder, we propose HPT++, which further improves the performance of HPT. Our experiments are conducted across a wide range of evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization. Extensive results and ablation studies demonstrate the effectiveness of our methods, which consistently outperform existing SOTA methods.
Read more8/28/2024

0
Enhancing Few-Shot Transfer Learning with Optimized Multi-Task Prompt Tuning through Modular Prompt Composition
Ahmad Pouramini, Hesham Faili
In recent years, multi-task prompt tuning has garnered considerable attention for its inherent modularity and potential to enhance parameter-efficient transfer learning across diverse tasks. This paper aims to analyze and improve the performance of multiple tasks by facilitating the transfer of knowledge between their corresponding prompts in a multi-task setting. Our proposed approach decomposes the prompt for each target task into a combination of shared prompts (source prompts) and a task-specific prompt (private prompt). During training, the source prompts undergo fine-tuning and are integrated with the private prompt to drive the target prompt for each task. We present and compare multiple methods for combining source prompts to construct the target prompt, analyzing the roles of both source and private prompts within each method. We investigate their contributions to task performance and offer flexible, adjustable configurations based on these insights to optimize performance. Our empirical findings clearly showcase improvements in accuracy and robustness compared to the conventional practice of prompt tuning and related works. Notably, our results substantially outperform other methods in the field in few-shot settings, demonstrating superior performance in various tasks across GLUE benchmark, among other tasks. This achievement is attained with a significantly reduced amount of training data, making our method a promising one for few-shot settings.
Read more8/26/2024