WangLab at MEDIQA-M3G 2024: Multimodal Medical Answer Generation using Large Language Models

0
🛸
Sign in to get full access
Overview
- This paper describes two standalone solutions submitted by the authors to the MEDIQA2024 Multilingual and Multimodal Medical Answer Generation (M3G) shared task.
- The first solution involved using the Claude 3 Opus API in a two-step process, while the second solution trained a CLIP-style image-disease label joint embedding for image classification.
- These two solutions achieved the top two spots on the competition leaderboard, outperforming the next best solution by a significant margin.
- The authors also discuss insights gained from post-competition experiments and identify the multi-stage LLM approach and the CLIP image classification approach as promising avenues for further investigation.
Plain English Explanation
The paper describes two different approaches the authors used to tackle a challenging task in the field of medical AI. The first approach involved using an existing language model called Claude 3 Opus in a two-step process to generate answers to medical questions. The second approach trained a new model that could classify images of medical conditions and diseases.
Both of these approaches performed very well in a competition where teams competed to see who could best answer medical questions using both text and images. In fact, the authors' two approaches came in first and second place, significantly outperforming the next best solution.
After the competition, the authors did some additional experiments and identified the key strengths of each approach. They believe that using multiple language models in sequence (PEFOMED: Parameter-Efficient Fine-Tuning of Multimodal Large Language Models) and training models to classify medical images (MedExpQA: Multilingual Benchmarking of Large Language Models on Medical Question Answering) are promising directions for further research in this area.
Technical Explanation
The paper describes two standalone solutions the authors submitted to the MEDIQA2024 Multilingual and Multimodal Medical Answer Generation (M3G) shared task.
The first solution involved using the Claude 3 Opus API in a two-step process. First, the model was used to generate a preliminary answer to a medical question. Then, the model was fine-tuned on a dataset of medical question-answer pairs to produce a refined final answer. This multi-stage LLM approach (WangLab at MEDIQA-CORR 2024: Optimized LLM for Multilingual Medical QA) allowed the model to leverage the broad knowledge of the pre-trained Claude 3 Opus while also incorporating task-specific medical knowledge.
The second solution trained a CLIP-style image-disease label joint embedding model for image classification. This model was trained to learn a joint representation of medical images and their associated disease labels, allowing it to accurately classify images of medical conditions. This CLIP-based approach (Medical-MT5: Open-Source Multilingual Text-to-Text Transformer for Medical Domain, Introducing L2M3: A Multilingual Medical Large Language Model) proved to be a powerful technique for the visual component of the medical question answering task.
These two solutions significantly outperformed the next best submission on the competition leaderboard, demonstrating the effectiveness of the multi-stage LLM approach and the CLIP-style image classification approach for this challenging task.
Critical Analysis
While the performance of the authors' two solutions was impressive, the paper acknowledges that there is still substantial room for improvement in the field of medical visual question answering. The shared task itself was highly challenging, and the authors note that medical visual question answering remains a difficult problem in general.
The paper also highlights the need for further research and experimentation to fully unlock the potential of the multi-stage LLM approach and the CLIP-style image classification approach. The authors suggest that these techniques are promising avenues for future work, but more work is needed to refine and optimize these methods.
Additionally, the paper does not address potential biases or limitations of the training data or model architectures used. It would be valuable for future research to examine these aspects more closely and consider ways to mitigate any issues that may arise.
Overall, the paper presents two innovative solutions that performed exceptionally well in the MEDIQA2024 shared task. However, the authors rightly acknowledge that this is a complex and difficult problem, and more research is needed to further advance the state of the art in medical visual question answering.
Conclusion
This paper outlines the authors' submission to the MEDIQA2024 Multilingual and Multimodal Medical Answer Generation (M3G) shared task, which involved two standalone solutions that achieved the top two spots on the competition leaderboard.
The first solution leveraged the Claude 3 Opus API in a two-step process, while the second solution trained a CLIP-style image-disease label joint embedding model for image classification. Both approaches demonstrated strong performance, suggesting that the multi-stage LLM approach and the CLIP-based image classification technique are promising directions for further research in this challenging domain.
Although the authors acknowledge that medical visual question answering remains a difficult problem with significant room for improvement, the insights gained from this work provide valuable guidance for future researchers and practitioners working to advance the state of the art in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
WangLab at MEDIQA-M3G 2024: Multimodal Medical Answer Generation using Large Language Models
Ronald Xie, Steven Palayew, Augustin Toma, Gary Bader, Bo Wang
This paper outlines our submission to the MEDIQA2024 Multilingual and Multimodal Medical Answer Generation (M3G) shared task. We report results for two standalone solutions under the English category of the task, the first involving two consecutive API calls to the Claude 3 Opus API and the second involving training an image-disease label joint embedding in the style of CLIP for image classification. These two solutions scored 1st and 2nd place respectively on the competition leaderboard, substantially outperforming the next best solution. Additionally, we discuss insights gained from post-competition experiments. While the performance of these two solutions have significant room for improvement due to the difficulty of the shared task and the challenging nature of medical visual question answering in general, we identify the multi-stage LLM approach and the CLIP image classification approach as promising avenues for further investigation.
Read more4/24/2024
0
MediFact at MEDIQA-M3G 2024: Medical Question Answering in Dermatology with Multimodal Learning
Nadia Saeed
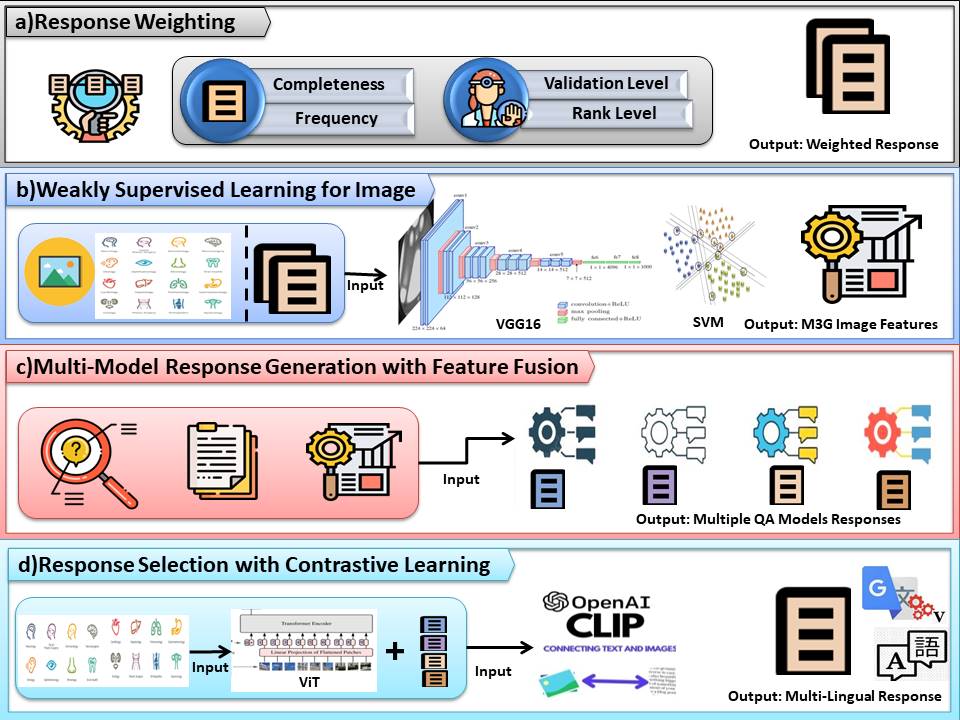
The MEDIQA-M3G 2024 challenge necessitates novel solutions for Multilingual & Multimodal Medical Answer Generation in dermatology (wai Yim et al., 2024a). This paper addresses the limitations of traditional methods by proposing a weakly supervised learning approach for open-ended medical question-answering (QA). Our system leverages readily available MEDIQA-M3G images via a VGG16-CNN-SVM model, enabling multilingual (English, Chinese, Spanish) learning of informative skin condition representations. Using pre-trained QA models, we further bridge the gap between visual and textual information through multimodal fusion. This approach tackles complex, open-ended questions even without predefined answer choices. We empower the generation of comprehensive answers by feeding the ViT-CLIP model with multiple responses alongside images. This work advances medical QA research, paving the way for clinical decision support systems and ultimately improving healthcare delivery.
Read more5/6/2024
0
Advancing High Resolution Vision-Language Models in Biomedicine
Zekai Chen, Arda Pekis, Kevin Brown
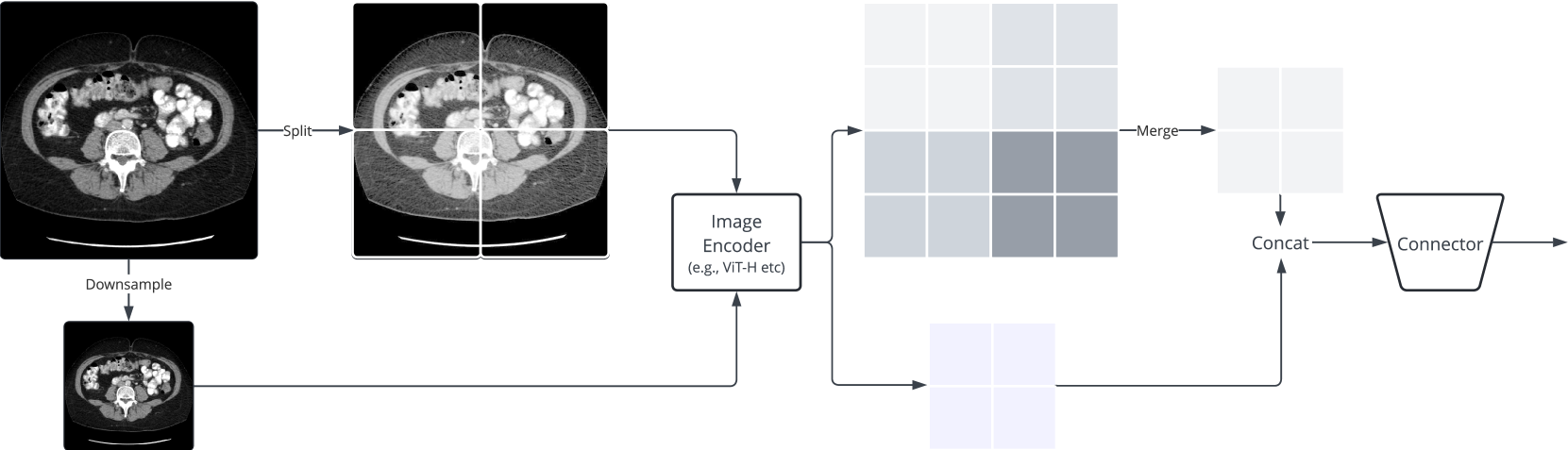
Multi-modal learning has significantly advanced generative AI, especially in vision-language modeling. Innovations like GPT-4V and open-source projects such as LLaVA have enabled robust conversational agents capable of zero-shot task completions. However, applying these technologies in the biomedical field presents unique challenges. Recent initiatives like LLaVA-Med have started to adapt instruction-tuning for biomedical contexts using large datasets such as PMC-15M. Our research offers three key contributions: (i) we present a new instruct dataset enriched with medical image-text pairs from Claude3-Opus and LLaMA3 70B, (ii) we propose a novel image encoding strategy using hierarchical representations to improve fine-grained biomedical visual comprehension, and (iii) we develop the Llama3-Med model, which achieves state-of-the-art zero-shot performance on biomedical visual question answering benchmarks, with an average performance improvement of over 10% compared to previous methods. These advancements provide more accurate and reliable tools for medical professionals, bridging gaps in current multi-modal conversational assistants and promoting further innovations in medical AI.
Read more6/17/2024
0
Towards Building Multilingual Language Model for Medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
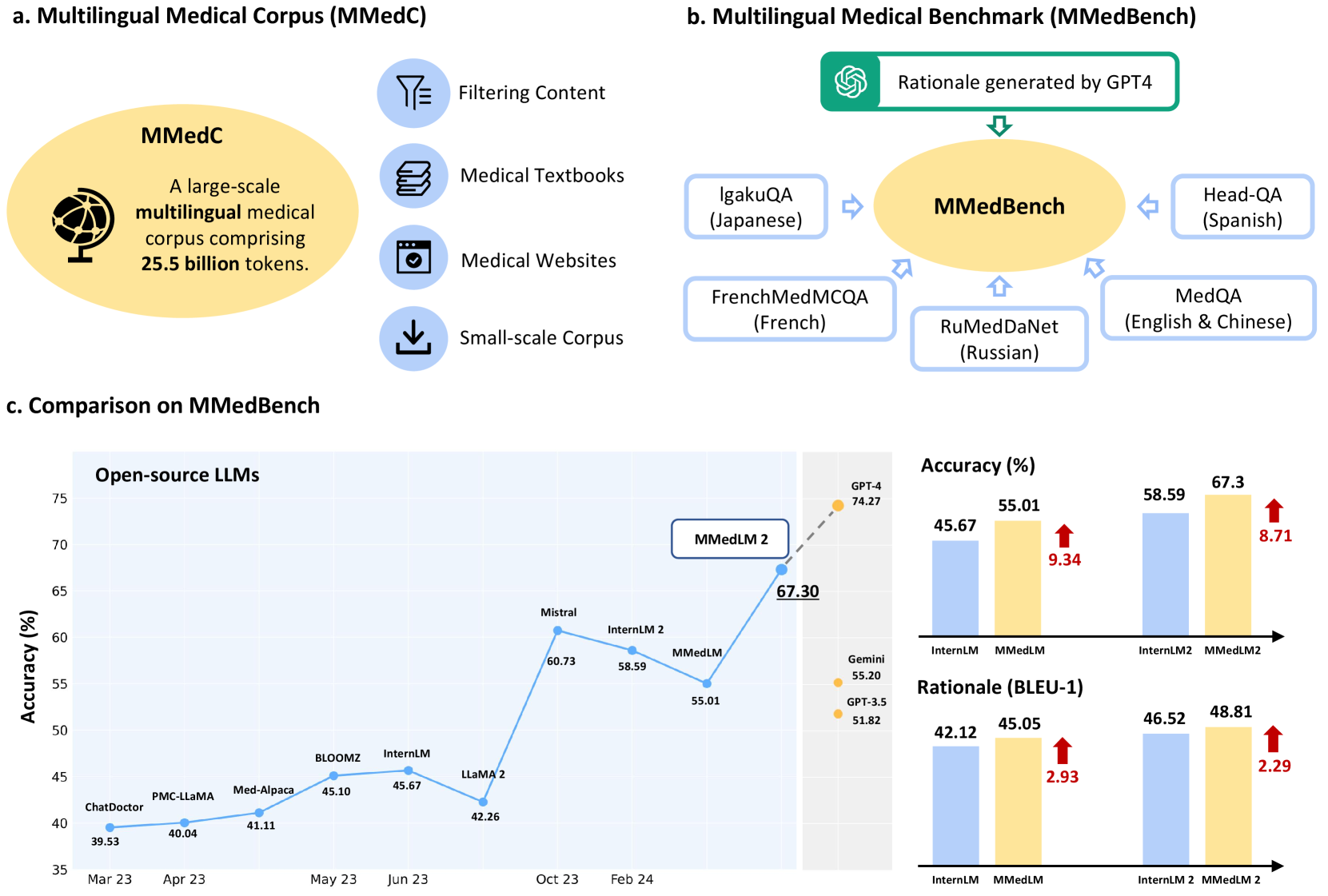
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
Read more6/4/2024