Perception Without Vision for Trajectory Prediction: Ego Vehicle Dynamics as Scene Representation for Efficient Active Learning in Autonomous Driving
2405.09049
0
0
Abstract
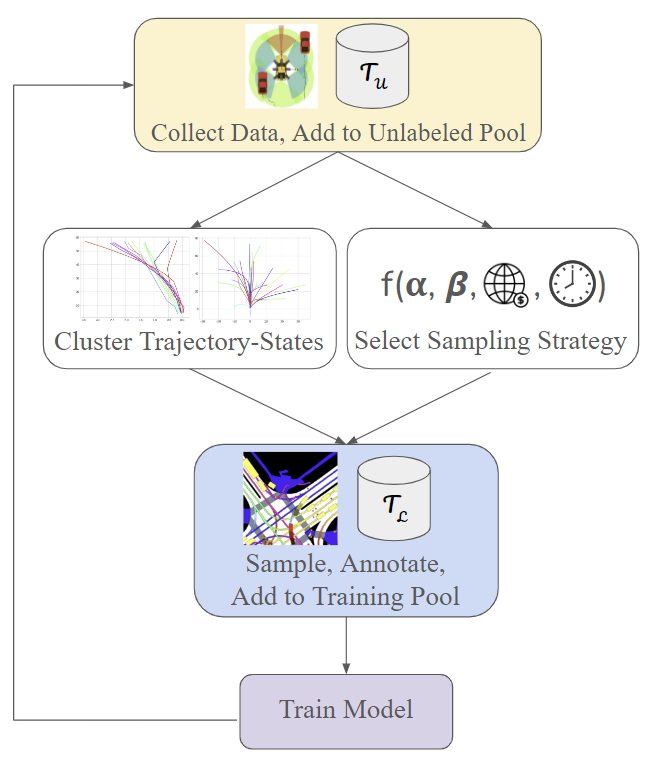
This study investigates the use of trajectory and dynamic state information for efficient data curation in autonomous driving machine learning tasks. We propose methods for clustering trajectory-states and sampling strategies in an active learning framework, aiming to reduce annotation and data costs while maintaining model performance. Our approach leverages trajectory information to guide data selection, promoting diversity in the training data. We demonstrate the effectiveness of our methods on the trajectory prediction task using the nuScenes dataset, showing consistent performance gains over random sampling across different data pool sizes, and even reaching sub-baseline displacement errors at just 50% of the data cost. Our results suggest that sampling typical data initially helps overcome the ''cold start problem,'' while introducing novelty becomes more beneficial as the training pool size increases. By integrating trajectory-state-informed active learning, we demonstrate that more efficient and robust autonomous driving systems are possible and practical using low-cost data curation strategies.
Create account to get full access
Overview
- This paper proposes a novel approach for trajectory prediction in autonomous driving that uses ego vehicle dynamics as a scene representation instead of relying on vision-based perception.
- The authors introduce an efficient active learning framework that leverages the proposed scene representation to curate a targeted dataset for training trajectory prediction models.
- The research aims to address the challenges of vision-based perception, such as occlusion and sensor failures, by using a dynamics-aware scene representation that can provide robust and efficient trajectory prediction.
Plain English Explanation
The paper introduces a new way to help self-driving cars predict the future paths of other vehicles on the road. Instead of relying solely on camera data to perceive the scene, the authors propose using the ego vehicle's own dynamics and motion as a representation of the surrounding environment. This "perception without vision" approach can be more robust to issues like obstructed views or sensor failures that can plague traditional vision-based systems.
The key innovation is an active learning framework that uses this dynamics-based scene representation to intelligently curate a training dataset for the trajectory prediction model. By targeting the most informative samples, the model can be trained more efficiently compared to using a generic, randomly collected dataset. This helps address the significant data requirements of modern machine learning approaches.
The underlying idea is that the ego vehicle's own motion and behavior can provide valuable cues about the state of the driving environment, even without direct visual perception. For example, if the ego vehicle is braking hard, it likely means there is an obstacle or hazard ahead that other nearby vehicles are also reacting to. By learning from these kinds of implicit signals in the ego vehicle's dynamics, the trajectory prediction model can learn to anticipate the movements of other cars on the road.
Technical Explanation
The paper proposes a Perception Without Vision for Trajectory Prediction approach that uses the ego vehicle's own dynamics as a scene representation for efficient active learning in autonomous driving.
The key elements of the research include:
-
Dynamics-Aware Scene Representation: Instead of relying solely on camera data, the authors use the ego vehicle's own motion and behavioral signals (e.g., acceleration, steering angle) as a proxy for understanding the surrounding environment. This "perception without vision" approach aims to be more robust to challenges like occlusion and sensor failures.
-
Active Learning Framework: The authors introduce an efficient active learning pipeline that leverages the proposed scene representation to selectively curate a training dataset for the trajectory prediction model. This targeted data collection approach is designed to be more sample-efficient compared to using a generic, randomly collected dataset.
-
Trajectory Prediction Model: The paper evaluates the proposed approach on a trajectory prediction task, using the curated dataset to train a model that can anticipate the future paths of other vehicles on the road. The authors demonstrate improved performance compared to baseline methods that rely on traditional vision-based perception.
The research draws inspiration from related work in dynamics-aware contrastive learning, interpretable neural motion planning, and cognitive-driven trajectory prediction. The authors also discuss how the proposed approach could be integrated with attention-based end-to-end driving models and contribute to the broader robustness of trajectory prediction in autonomous vehicles.
Critical Analysis
The paper presents a promising approach to addressing the challenges of vision-based perception in autonomous driving. By leveraging the ego vehicle's own dynamics as a scene representation, the authors demonstrate improved trajectory prediction performance and efficiency compared to traditional methods.
One potential limitation is the reliance on the availability and quality of the ego vehicle's own motion data. In real-world scenarios, there may be cases where this data is incomplete or noisy, which could impact the performance of the proposed system. The authors acknowledge this and suggest potential ways to mitigate these issues, such as sensor fusion and robust state estimation techniques.
Additionally, while the active learning framework is a key innovation of the paper, the specific details of the data curation process and its long-term scalability could benefit from further exploration. The authors mention the importance of maintaining diversity in the training dataset, but more investigation into the tradeoffs and practical considerations of this approach would be valuable.
Overall, the research presented in this paper offers a compelling alternative to vision-based perception for trajectory prediction in autonomous driving. The dynamics-aware scene representation and efficient active learning framework show promise in addressing the limitations of traditional approaches and could contribute to the development of more robust and reliable self-driving systems.
Conclusion
This paper introduces a novel approach to trajectory prediction in autonomous driving that uses the ego vehicle's own dynamics as a scene representation, rather than relying solely on vision-based perception. The authors present an efficient active learning framework that leverages this dynamics-aware scene representation to curate a targeted training dataset, leading to improved performance and sample efficiency compared to baseline methods.
The key innovation of this work is the "perception without vision" concept, which aims to address the challenges of occlusion, sensor failures, and other issues that can plague traditional vision-based systems. By learning from the implicit signals in the ego vehicle's own motion and behavior, the trajectory prediction model can better anticipate the movements of other cars on the road.
The proposed approach has the potential to contribute to the development of more robust and reliable autonomous driving systems, by providing a complementary scene understanding mechanism to complement vision-based perception. Further research is needed to explore the scalability and practical considerations of the active learning framework, as well as the integration of this dynamics-aware representation with other state-of-the-art autonomous driving models and algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, Jose M. Alvarez
0
0
End-to-end autonomous driving recently emerged as a promising research direction to target autonomy from a full-stack perspective. Along this line, many of the latest works follow an open-loop evaluation setting on nuScenes to study the planning behavior. In this paper, we delve deeper into the problem by conducting thorough analyses and demystifying more devils in the details. We initially observed that the nuScenes dataset, characterized by relatively simple driving scenarios, leads to an under-utilization of perception information in end-to-end models incorporating ego status, such as the ego vehicle's velocity. These models tend to rely predominantly on the ego vehicle's status for future path planning. Beyond the limitations of the dataset, we also note that current metrics do not comprehensively assess the planning quality, leading to potentially biased conclusions drawn from existing benchmarks. To address this issue, we introduce a new metric to evaluate whether the predicted trajectories adhere to the road. We further propose a simple baseline able to achieve competitive results without relying on perception annotations. Given the current limitations on the benchmark and metrics, we suggest the community reassess relevant prevailing research and be cautious whether the continued pursuit of state-of-the-art would yield convincing and universal conclusions. Code and models are available at url{https://github.com/NVlabs/BEV-Planner}
6/4/2024

TrACT: A Training Dynamics Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Junrui Zhang, Mozhgan Pourkeshavarz, Amir Rasouli
0
0
As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.
5/1/2024
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Sourav Biswas, Sergio Casas, Quinlan Sykora, Ben Agro, Abbas Sadat, Raquel Urtasun
0
0
A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
4/3/2024
🧪
DualAD: Disentangling the Dynamic and Static World for End-to-End Driving
Simon Doll, Niklas Hanselmann, Lukas Schneider, Richard Schulz, Marius Cordts, Markus Enzweiler, Hendrik P. A. Lensch
0
0
State-of-the-art approaches for autonomous driving integrate multiple sub-tasks of the overall driving task into a single pipeline that can be trained in an end-to-end fashion by passing latent representations between the different modules. In contrast to previous approaches that rely on a unified grid to represent the belief state of the scene, we propose dedicated representations to disentangle dynamic agents and static scene elements. This allows us to explicitly compensate for the effect of both ego and object motion between consecutive time steps and to flexibly propagate the belief state through time. Furthermore, dynamic objects can not only attend to the input camera images, but also directly benefit from the inferred static scene structure via a novel dynamic-static cross-attention. Extensive experiments on the challenging nuScenes benchmark demonstrate the benefits of the proposed dual-stream design, especially for modelling highly dynamic agents in the scene, and highlight the improved temporal consistency of our approach. Our method titled DualAD not only outperforms independently trained single-task networks, but also improves over previous state-of-the-art end-to-end models by a large margin on all tasks along the functional chain of driving.
6/11/2024