Permissible Knowledge Pooling
2404.03418
0
0
🔗
Abstract
Information pooling has been extensively formalised across various logical frameworks in distributed systems, characterized by diverse information-sharing patterns. These approaches generally adopt an intersection perspective, aggregating all possible information, regardless of whether it is known or unknown to the agents. In contrast, this work adopts a unique stance, emphasising that sharing knowledge means distributing what is known, rather than what remains uncertain. This paper introduces new modal logics for knowledge pooling and sharing, ranging from a novel language of knowledge pooling to a dynamic mechanism for knowledge sharing. It also outlines their axiomatizations and discusses a potential framework for permissible knowledge pooling.
Create account to get full access
Overview
- Explores the concept of "permissible knowledge pooling" in the context of AI systems
- Discusses the challenges of knowledge integration and the potential for knowledge collapse
- Proposes a theoretical framework for facilitating effective knowledge sharing and reasoning
Plain English Explanation
The paper examines the critical challenge of enabling AI systems to pool and integrate knowledge from diverse sources without experiencing "knowledge collapse" - a phenomenon where the system's understanding becomes fragmented or inconsistent. The researchers argue that effective knowledge pooling is essential for developing AI agents that can engage in robust reasoning and decision-making.
The core idea is to establish a set of "permissible" rules or guidelines that govern how AI systems can aggregate and reconcile information from multiple knowledge bases. This would allow the systems to maintain a coherent and well-structured knowledge representation, while still benefiting from the diverse inputs. Categorical Semiotics: Foundations for Knowledge Integration and Towards Scalable, Efficient, Interaction-Aware Planning for Autonomous Systems explore related concepts of knowledge integration and reasoning.
By developing a principled framework for knowledge pooling, the researchers aim to address challenges like knowledge boundary persona and dynamic shape for better social interaction and untangling the knot of interweaving conflicting knowledge and reasoning skills. The ultimate goal is to enable AI systems to leverage diverse information sources while maintaining a coherent and consistent understanding of the world.
Technical Explanation
The paper proposes a theoretical framework for "permissible knowledge pooling" in AI systems. The key elements include:
-
Static Information: The researchers define a set of static information objects, such as concepts, properties, and relations, that represent the foundational knowledge of the system.
-
Dynamic Information: The system also maintains a set of dynamic information objects, which represent the evolving knowledge and beliefs of the agent as it interacts with the world.
-
Pooling Dynamics: The paper outlines a set of rules and constraints that govern how the static and dynamic information objects can be combined and reconciled during the knowledge pooling process. This is designed to prevent knowledge collapse and maintain a coherent knowledge representation.
-
Reasoning Capabilities: The framework also incorporates reasoning mechanisms that allow the AI agent to draw inferences, make decisions, and update its understanding based on the pooled knowledge.
The researchers demonstrate the application of this framework through a series of experiments and use cases, highlighting its potential to address challenges like AI problems and knowledge collapse.
Critical Analysis
The paper presents a compelling theoretical framework for enabling effective knowledge pooling in AI systems. However, the authors acknowledge that the proposed approach may face practical challenges in real-world deployment, such as:
-
Scalability: Scaling the knowledge pooling process to handle large and diverse knowledge bases may require additional optimizations and computational resources.
-
Robustness: Ensuring the system's ability to handle contradictory or noisy inputs without compromising the overall knowledge integrity could be a significant challenge.
-
Interpretability: Providing transparent and interpretable explanations for the system's reasoning and decision-making processes may be crucial for building trust and acceptance in real-world applications.
Further research and experimentation are needed to address these challenges and validate the practical viability of the proposed framework. Additionally, exploring the potential synergies between this work and related approaches, such as Categorical Semiotics: Foundations for Knowledge Integration, could lead to more comprehensive solutions for knowledge integration in AI systems.
Conclusion
The paper presents a novel theoretical framework for "permissible knowledge pooling" in AI systems, which aims to address the critical challenge of enabling effective knowledge integration and reasoning while maintaining a coherent and consistent knowledge representation. The proposed approach offers a promising direction for developing AI agents that can leverage diverse information sources without succumbing to knowledge collapse.
By establishing a set of rules and constraints for knowledge pooling, the researchers seek to pave the way for more robust and reliable AI systems that can engage in sophisticated reasoning and decision-making. While the framework still faces practical challenges, this work represents an important step towards unlocking the full potential of AI in complex, real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
AI and the Problem of Knowledge Collapse
Andrew J. Peterson
0
0
While artificial intelligence has the potential to process vast amounts of data, generate new insights, and unlock greater productivity, its widespread adoption may entail unforeseen consequences. We identify conditions under which AI, by reducing the cost of access to certain modes of knowledge, can paradoxically harm public understanding. While large language models are trained on vast amounts of diverse data, they naturally generate output towards the 'center' of the distribution. This is generally useful, but widespread reliance on recursive AI systems could lead to a process we define as knowledge collapse, and argue this could harm innovation and the richness of human understanding and culture. However, unlike AI models that cannot choose what data they are trained on, humans may strategically seek out diverse forms of knowledge if they perceive them to be worthwhile. To investigate this, we provide a simple model in which a community of learners or innovators choose to use traditional methods or to rely on a discounted AI-assisted process and identify conditions under which knowledge collapse occurs. In our default model, a 20% discount on AI-generated content generates public beliefs 2.3 times further from the truth than when there is no discount. An empirical approach to measuring the distribution of LLM outputs is provided in theoretical terms and illustrated through a specific example comparing the diversity of outputs across different models and prompting styles. Finally, based on the results, we consider further research directions to counteract such outcomes.
4/23/2024
🤿
Semantic Objective Functions: A distribution-aware method for adding logical constraints in deep learning
Miguel Angel Mendez-Lucero, Enrique Bojorquez Gallardo, Vaishak Belle
0
0
Issues of safety, explainability, and efficiency are of increasing concern in learning systems deployed with hard and soft constraints. Symbolic Constrained Learning and Knowledge Distillation techniques have shown promising results in this area, by embedding and extracting knowledge, as well as providing logical constraints during neural network training. Although many frameworks exist to date, through an integration of logic and information geometry, we provide a construction and theoretical framework for these tasks that generalize many approaches. We propose a loss-based method that embeds knowledge-enforces logical constraints-into a machine learning model that outputs probability distributions. This is done by constructing a distribution from the external knowledge/logic formula and constructing a loss function as a linear combination of the original loss function with the Fisher-Rao distance or Kullback-Leibler divergence to the constraint distribution. This construction includes logical constraints in the form of propositional formulas (Boolean variables), formulas of a first-order language with finite variables over a model with compact domain (categorical and continuous variables), and in general, likely applicable to any statistical model that was pretrained with semantic information. We evaluate our method on a variety of learning tasks, including classification tasks with logic constraints, transferring knowledge from logic formulas, and knowledge distillation from general distributions.
5/28/2024
Leveraging Multi-AI Agents for Cross-Domain Knowledge Discovery
Shiva Aryal, Tuyen Do, Bisesh Heyojoo, Sandeep Chataut, Bichar Dip Shrestha Gurung, Venkataramana Gadhamshetty, Etienne Gnimpieba
0
0
In the rapidly evolving field of artificial intelligence, the ability to harness and integrate knowledge across various domains stands as a paramount challenge and opportunity. This study introduces a novel approach to cross-domain knowledge discovery through the deployment of multi-AI agents, each specialized in distinct knowledge domains. These AI agents, designed to function as domain-specific experts, collaborate in a unified framework to synthesize and provide comprehensive insights that transcend the limitations of single-domain expertise. By facilitating seamless interaction among these agents, our platform aims to leverage the unique strengths and perspectives of each, thereby enhancing the process of knowledge discovery and decision-making. We present a comparative analysis of the different multi-agent workflow scenarios evaluating their performance in terms of efficiency, accuracy, and the breadth of knowledge integration. Through a series of experiments involving complex, interdisciplinary queries, our findings demonstrate the superior capability of domain specific multi-AI agent system in identifying and bridging knowledge gaps. This research not only underscores the significance of collaborative AI in driving innovation but also sets the stage for future advancements in AI-driven, cross-disciplinary research and application. Our methods were evaluated on a small pilot data and it showed a trend we expected, if we increase the amount of data we custom train the agents, the trend is expected to be more smooth.
4/15/2024
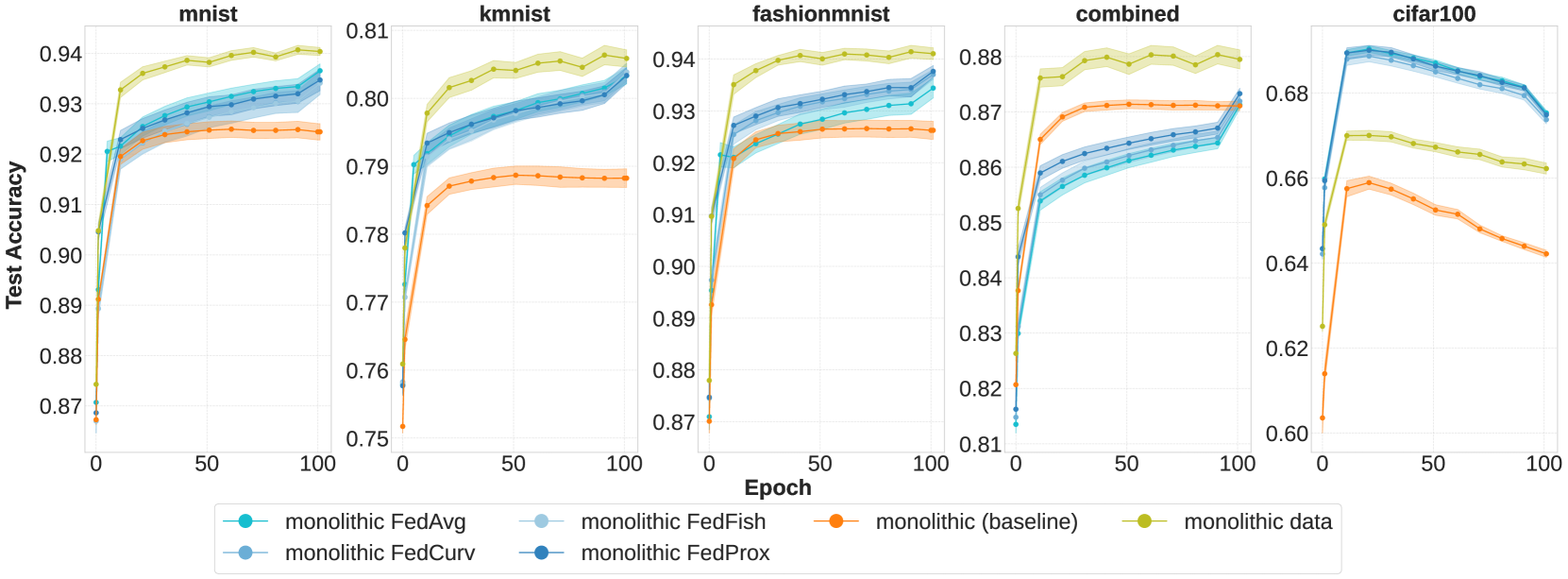
Distributed Continual Learning
Long Le, Marcel Hussing, Eric Eaton
0
0
This work studies the intersection of continual and federated learning, in which independent agents face unique tasks in their environments and incrementally develop and share knowledge. We introduce a mathematical framework capturing the essential aspects of distributed continual learning, including agent model and statistical heterogeneity, continual distribution shift, network topology, and communication constraints. Operating on the thesis that distributed continual learning enhances individual agent performance over single-agent learning, we identify three modes of information exchange: data instances, full model parameters, and modular (partial) model parameters. We develop algorithms for each sharing mode and conduct extensive empirical investigations across various datasets, topology structures, and communication limits. Our findings reveal three key insights: sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.
5/29/2024