Distributed Continual Learning
2405.17466
0
0
Abstract
This work studies the intersection of continual and federated learning, in which independent agents face unique tasks in their environments and incrementally develop and share knowledge. We introduce a mathematical framework capturing the essential aspects of distributed continual learning, including agent model and statistical heterogeneity, continual distribution shift, network topology, and communication constraints. Operating on the thesis that distributed continual learning enhances individual agent performance over single-agent learning, we identify three modes of information exchange: data instances, full model parameters, and modular (partial) model parameters. We develop algorithms for each sharing mode and conduct extensive empirical investigations across various datasets, topology structures, and communication limits. Our findings reveal three key insights: sharing parameters is more efficient than sharing data as tasks become more complex; modular parameter sharing yields the best performance while minimizing communication costs; and combining sharing modes can cumulatively improve performance.
Create account to get full access
Overview
- Distributed Continual Learning explores how machine learning models can continuously learn and adapt to new tasks or environments in a decentralized setting.
- This paper proposes a framework to enable continual learning across multiple devices or data sources, addressing challenges like catastrophic forgetting and data privacy.
- The research aims to advance the field of continual learning and federated learning, which are important for deploying AI in real-world, dynamic settings.
Plain English Explanation
Imagine you have a machine learning model that's trained to recognize different types of flowers. Over time, you want it to also learn to identify animals, cars, and other new things. Normally, if you just keep training the model on new data, it will forget what it learned about flowers. This is called "catastrophic forgetting."
The key idea in this paper is to enable the model to continuously learn new skills without forgetting the old ones, even when it's spread across multiple devices or data sources. For example, different devices in people's homes could each contribute small amounts of data to help the model expand its knowledge over time, without any single device having to share all its data.
This is important because in the real world, AI systems often need to keep learning and adapting as they encounter new situations. And we want to do this in a way that protects people's privacy, since the data used to train the model is often sensitive.
The paper proposes a framework that allows the model to learn continually across multiple devices or data sources, without suffering from catastrophic forgetting. This helps push the field of continual learning and federated learning forward, bringing us closer to AI systems that can adapt and grow in the real world.
Technical Explanation
The key technical contribution of this paper is a distributed continual learning framework that enables machine learning models to learn continuously across multiple devices or data sources.
The framework consists of several components:
- A global model that aggregates knowledge from all the devices and tasks.
- Local models on individual devices that adapt to their own data and tasks.
- A knowledge distillation process that transfers knowledge from the global model to the local models, and vice versa, to enable continual learning.
- A privacy-preserving aggregation mechanism that allows the global model to be updated without accessing raw data from the devices.
The authors evaluate this framework on several benchmark continual learning tasks, simulating a distributed setting where data and tasks are spread across multiple devices. The results show the framework can achieve strong performance on new tasks while preserving performance on old tasks, outperforming baseline continual learning approaches.
Importantly, the paper also analyzes the trade-offs between model accuracy, communication efficiency, and data privacy in this distributed continual learning setup. This provides valuable insights for deploying such systems in real-world, federated learning scenarios.
Critical Analysis
The paper makes a valuable contribution by addressing the challenge of continual learning in a distributed setting, where data and tasks are spread across multiple devices. This is an important step towards building AI systems that can continuously adapt and learn in the real world.
However, the authors acknowledge several limitations and areas for future work. For example, the current framework assumes non-overlapping tasks across devices, which may not always be the case in practice. Additionally, the privacy-preserving aggregation mechanism could be further improved to provide stronger guarantees.
Another potential issue is the reliance on knowledge distillation, which can be sensitive to hyperparameter tuning and may not scale well to a large number of devices or tasks. Exploring alternative continual learning approaches, such as variational Bayes or liquid ensembles, could be an interesting direction for future research.
Overall, this paper represents a significant step forward in the field of distributed continual learning, but there are still many challenges to be addressed before such systems can be deployed in real-world, dynamic environments.
Conclusion
The Distributed Continual Learning paper proposes a promising framework for enabling machine learning models to continuously learn and adapt to new tasks or environments in a decentralized setting. By addressing challenges like catastrophic forgetting and data privacy, this research advances the state-of-the-art in both continual learning and federated learning.
The insights and techniques developed in this paper could have important implications for deploying AI systems in real-world, dynamic settings, where the ability to continuously learn and adapt is crucial. While the current approach has some limitations, the paper lays the groundwork for further advancements in this exciting area of machine learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Cross-Silo Federated Learning Across Divergent Domains with Iterative Parameter Alignment
Matt Gorbett, Hossein Shirazi, Indrakshi Ray
0
0
Learning from the collective knowledge of data dispersed across private sources can provide neural networks with enhanced generalization capabilities. Federated learning, a method for collaboratively training a machine learning model across remote clients, achieves this by combining client models via the orchestration of a central server. However, current approaches face two critical limitations: i) they struggle to converge when client domains are sufficiently different, and ii) current aggregation techniques produce an identical global model for each client. In this work, we address these issues by reformulating the typical federated learning setup: rather than learning a single global model, we learn N models each optimized for a common objective. To achieve this, we apply a weighted distance minimization to model parameters shared in a peer-to-peer topology. The resulting framework, Iterative Parameter Alignment, applies naturally to the cross-silo setting, and has the following properties: (i) a unique solution for each participant, with the option to globally converge each model in the federation, and (ii) an optional early-stopping mechanism to elicit fairness among peers in collaborative learning settings. These characteristics jointly provide a flexible new framework for iteratively learning from peer models trained on disparate datasets. We find that the technique achieves competitive results on a variety of data partitions compared to state-of-the-art approaches. Further, we show that the method is robust to divergent domains (i.e. disjoint classes across peers) where existing approaches struggle.
5/20/2024
Parameterizing Federated Continual Learning for Reproducible Research
Bart Cox, Jeroen Galjaard, Aditya Shankar, J'er'emie Decouchant, Lydia Y. Chen
0
0
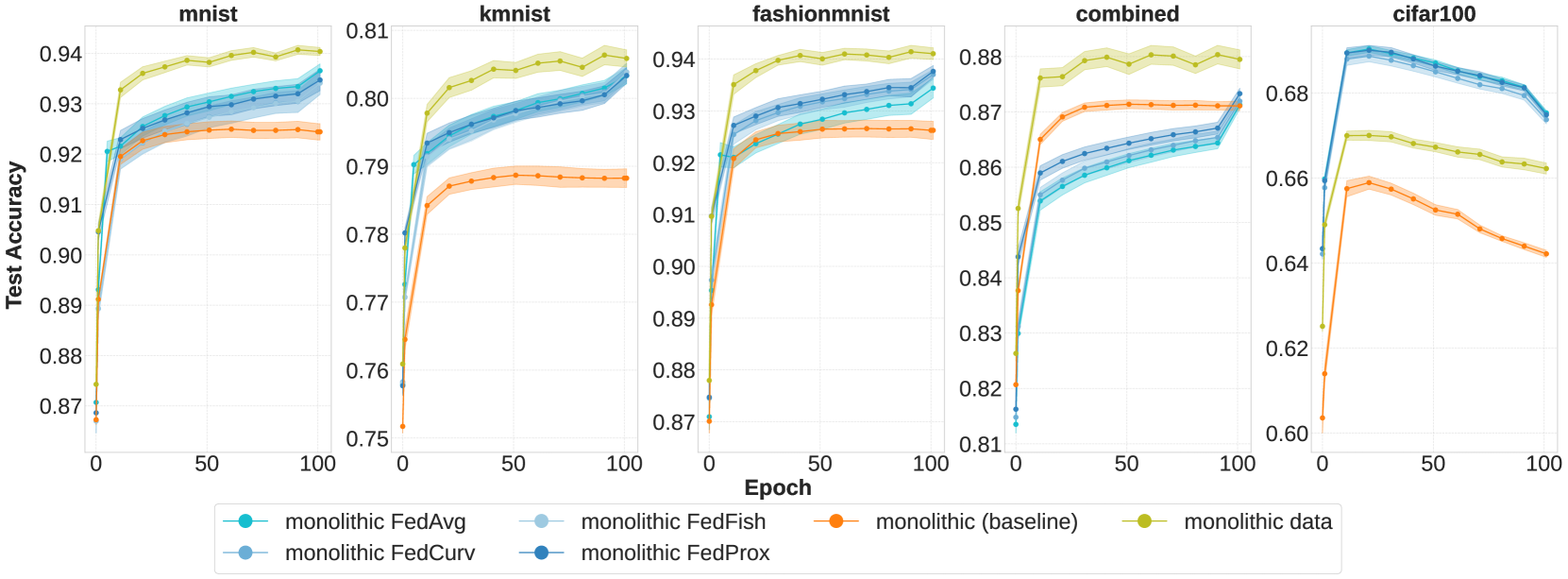
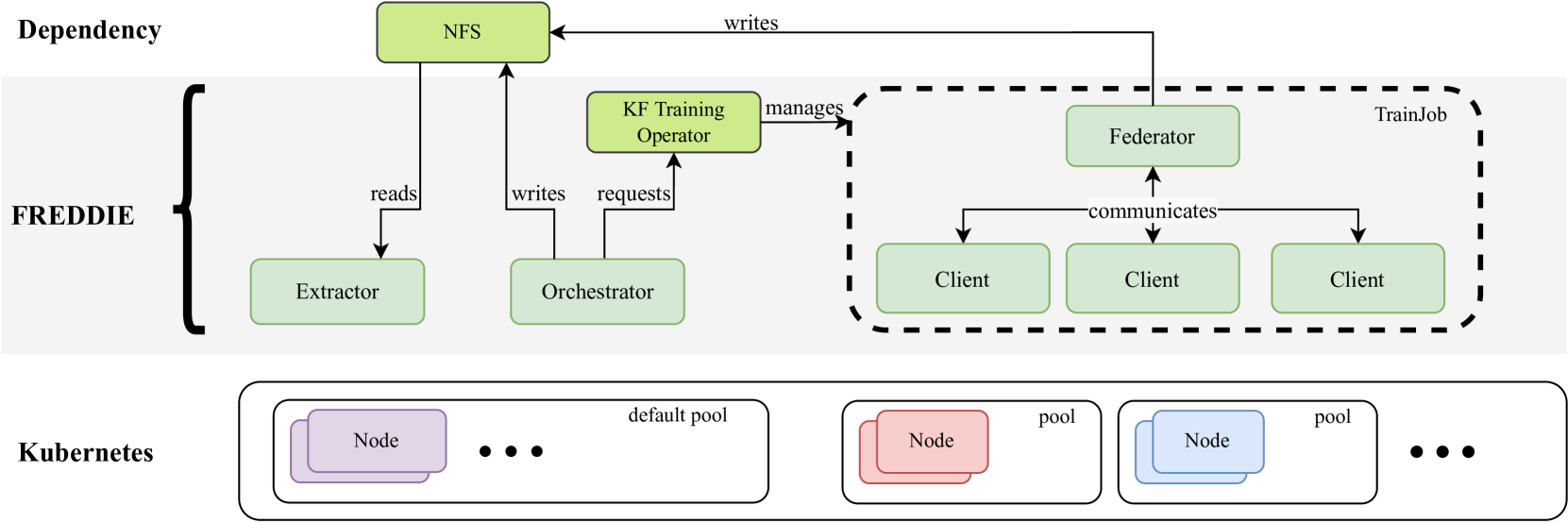
Federated Learning (FL) systems evolve in heterogeneous and ever-evolving environments that challenge their performance. Under real deployments, the learning tasks of clients can also evolve with time, which calls for the integration of methodologies such as Continual Learning. To enable research reproducibility, we propose a set of experimental best practices that precisely capture and emulate complex learning scenarios. Our framework, Freddie, is the first entirely configurable framework for Federated Continual Learning (FCL), and it can be seamlessly deployed on a large number of machines thanks to the use of Kubernetes and containerization. We demonstrate the effectiveness of Freddie on two use cases, (i) large-scale FL on CIFAR100 and (ii) heterogeneous task sequence on FCL, which highlight unaddressed performance challenges in FCL scenarios.
6/5/2024
Decentralized Personalized Federated Learning
Salma Kharrat, Marco Canini, Samuel Horvath
0
0
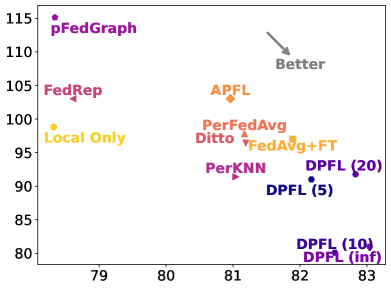
This work tackles the challenges of data heterogeneity and communication limitations in decentralized federated learning. We focus on creating a collaboration graph that guides each client in selecting suitable collaborators for training personalized models that leverage their local data effectively. Our approach addresses these issues through a novel, communication-efficient strategy that enhances resource efficiency. Unlike traditional methods, our formulation identifies collaborators at a granular level by considering combinatorial relations of clients, enhancing personalization while minimizing communication overhead. We achieve this through a bi-level optimization framework that employs a constrained greedy algorithm, resulting in a resource-efficient collaboration graph for personalized learning. Extensive evaluation against various baselines across diverse datasets demonstrates the superiority of our method, named DPFL. DPFL consistently outperforms other approaches, showcasing its effectiveness in handling real-world data heterogeneity, minimizing communication overhead, enhancing resource efficiency, and building personalized models in decentralized federated learning scenarios.
6/11/2024
A Survey of Distributed Learning in Cloud, Mobile, and Edge Settings
Madison Threadgill, Andreas Gerstlauer
0
0
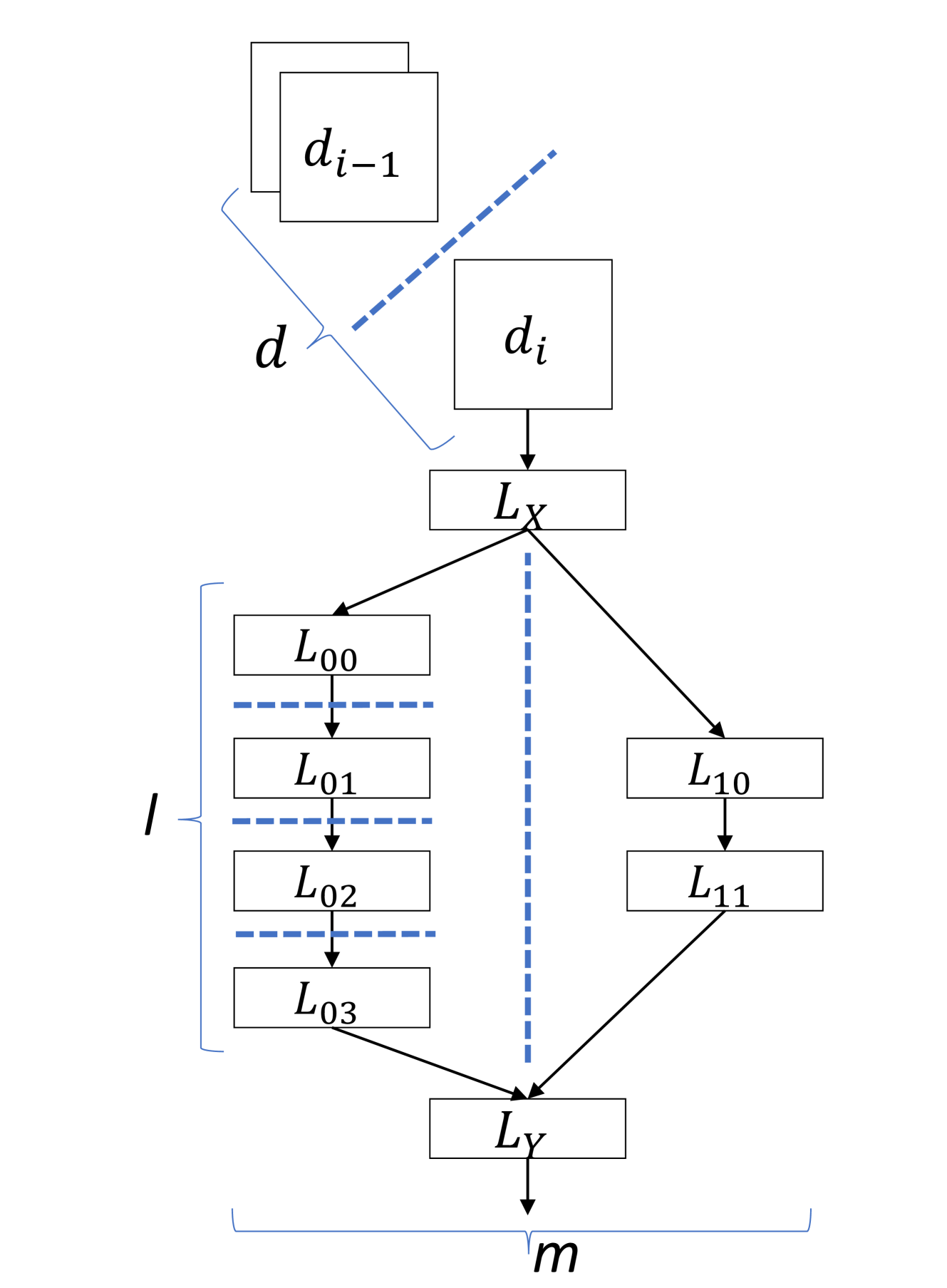
In the era of deep learning (DL), convolutional neural networks (CNNs), and large language models (LLMs), machine learning (ML) models are becoming increasingly complex, demanding significant computational resources for both inference and training stages. To address this challenge, distributed learning has emerged as a crucial approach, employing parallelization across various devices and environments. This survey explores the landscape of distributed learning, encompassing cloud and edge settings. We delve into the core concepts of data and model parallelism, examining how models are partitioned across different dimensions and layers to optimize resource utilization and performance. We analyze various partitioning schemes for different layer types, including fully connected, convolutional, and recurrent layers, highlighting the trade-offs between computational efficiency, communication overhead, and memory constraints. This survey provides valuable insights for future research and development in this rapidly evolving field by comparing and contrasting distributed learning approaches across diverse contexts.
5/27/2024